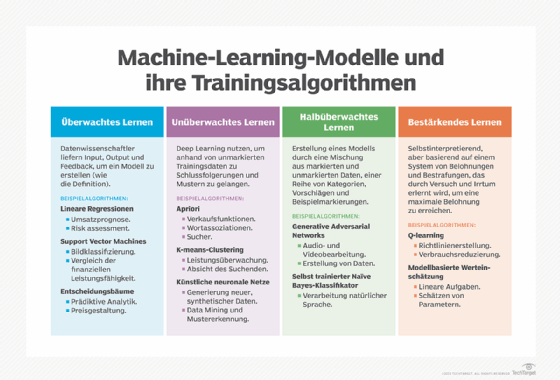
Überwachtes Lernen (Supervised Learning)

Was ist überwachtes Lernen (Supervised Learning)?
Überwachtes Lernen ist ein Ansatz zur Entwicklung künstlicher Intelligenz (KI), bei dem ein Computeralgorithmus auf Eingabedaten trainiert wird, die für eine bestimmte Ausgabe gelabelt beziehungsweise markiert worden sind. Das Modell wird so lange trainiert, bis es die zugrunde liegenden Muster und Beziehungen zwischen den Eingabedaten und den Ausgabelabel erkennen kann, so dass es in der Lage ist, genaue Ergebnisse zu liefern, wenn es mit noch nie zuvor gesehenen Daten konfrontiert wird.
Beim überwachten Lernen besteht das Ziel darin, die Daten im Kontext einer bestimmten Frage zu verstehen. Überwachtes Lernen eignet sich gut für Klassifizierungs- und Regressionsprobleme, wie zum Beispiel die Bestimmung der Kategorie eines Nachrichtenartikels oder die Vorhersage des Verkaufsvolumens für ein bestimmtes zukünftiges Datum. Unternehmen können das überwachte Lernen in Prozessen wie der Erkennung von Anomalien, der Betrugserkennung, der Bildklassifizierung, der Risikobewertung und der Spam-Filterung einsetzen.
Im Gegensatz zum überwachten Lernen steht das unüberwachte maschinelle Lernen. Bei diesem Ansatz werden dem Algorithmus nicht gelabelte Daten vorgelegt, und er ist so konzipiert, dass er selbständig Muster oder Ähnlichkeiten erkennt, ein Prozess, der im Folgenden näher beschrieben wird.
Wie funktioniert überwachtes Lernen?
Wie alle Algorithmen des maschinellen Lernens basiert auch das überwachte Lernen auf Training. Während der Trainingsphase wird das System mit gelabelten Datensätzen gefüttert, die dem System mitteilen, welche Ausgabevariable mit jedem spezifischen Eingabewert zusammenhängt. Das trainierte Modell wird dann mit Testdaten konfrontiert. Dabei handelt es sich um Daten, die zwar markiert wurden, deren Label dem Algorithmus jedoch nicht bekannt sind. Mit den Testdaten soll gemessen werden, wie genau der Algorithmus bei nicht gelabelten Daten arbeitet.
Zu den allgemeinen, grundlegenden Schritten bei der Implementierung des überwachten Lernens gehören:
- Bestimmen Sie die Art der Trainingsdaten, die als Trainingssatz verwendet werden sollen.
- Sammeln von gelabelten Trainingsdaten.
- Aufteilung der Trainingsdaten in Trainings-, Test- und Validierungsdatensätze.
- Bestimmen Sie einen Algorithmus, der für das maschinelle Lernmodell verwendet werden soll.
- Führen Sie den Algorithmus mit dem Trainingsdatensatz aus.
- Bewerten Sie die Genauigkeit des Modells. Wenn das Modell korrekte Ergebnisse vorhersagt, ist es genau.
Beispielsweise kann ein Algorithmus darauf trainiert werden, Bilder von Katzen und Hunden zu identifizieren, indem er mit einer großen Menge von Trainingsdaten gefüttert wird, die aus verschiedenen markierten Bildern von Katzen und Hunden bestehen. Diese Trainingsdaten sind eine Teilmenge von Fotos aus einem viel größeren Datensatz von Bildern. Nach dem Training sollte das Modell dann in der Lage sein, vorherzusagen, ob es sich bei der Ausgabe eines Bildes um eine Katze oder einen Hund handelt. Ein weiterer Satz von Bildern kann den Algorithmus durchlaufen lassen, um das Modell zu validieren.
Bei Algorithmen für neuronale Netze wird der überwachte Lernprozess verbessert, indem die resultierenden Ausgaben des Modells ständig gemessen werden und eine Feinabstimmung des Systems vorgenommen wird, um der Zielgenauigkeit näher zu kommen. Die erreichbare Genauigkeit hängt von zwei Dingen ab: den verfügbaren gelabelten Daten und dem verwendeten Algorithmus. Darüber hinaus beeinflussen die folgenden Faktoren den Prozess:
- Die Trainingsdaten müssen ausgewogen und bereinigt sein. Datenmüll oder doppelte Daten verzerren das Verständnis der KI – daher müssen Datenwissenschaftler sorgfältig mit den Daten umgehen, auf denen das Modell trainiert wird.
- Die Vielfalt der Daten bestimmt, wie gut die KI arbeitet, wenn sie mit neuen Fällen konfrontiert wird; wenn der Trainingsdatensatz nicht genügend Stichproben enthält, versagt das Modell und liefert keine zuverlässigen Antworten.
- Eine hohe Genauigkeit ist paradoxerweise nicht unbedingt ein gutes Zeichen; sie kann auch bedeuten, dass das Modell an einer Überanpassung leidet, das heißt dass es zu sehr auf seinen speziellen Trainingsdatensatz abgestimmt ist. Ein solcher Datensatz kann in Testszenarien gut abschneiden, aber bei realen Herausforderungen versagen. Um eine Überanpassung zu vermeiden, ist es wichtig, dass sich die Testdaten von den Trainingsdaten unterscheiden, um sicherzustellen, dass das Modell die Antworten nicht aus seinen früheren Erfahrungen ableitet, sondern dass die Schlussfolgerungen des Modells verallgemeinert werden.
- Der Algorithmus hingegen bestimmt, wie diese Daten verwendet werden können. So können beispielsweise Deep-Learning-Algorithmen so trainiert werden, dass sie Milliarden von Parametern aus ihren Daten extrahieren und eine noch nie dagewesene Genauigkeit erreichen, wie GPT-3-Modell von OpenAI zeigt.
Neben neuronalen Netzen gibt es viele andere überwachte Lernalgorithmen. Algorithmen des überwachten Lernens liefern hauptsächlich zwei Arten von Ergebnissen: Klassifizierung und Regression.
Klassifizierungsalgorithmen
Algorithmen des überwachten Lernens werden in zwei Arten unterteilt: Klassifizierung und Regression.
Ein Klassifizierungsalgorithmus zielt darauf ab, Eingaben in eine bestimmte Anzahl von Kategorien – oder Klassen – zu sortieren, basierend auf den gelabelten Daten, auf denen er trainiert wurde. Klassifizierungsalgorithmen können für binäre Klassifizierungen verwendet werden, zum Beispiel die Klassifizierung eines Bildes als Hund oder Katze, die Filterung von E-Mails in Spam oder Nicht-Spam und die Kategorisierung von Kunden-Feedback als positiv oder negativ.
Beispiele für maschinelle Lerntechniken zur Klassifizierung sind:
- Ein Entscheidungsbaum unterteilt Datenpunkte in zwei ähnliche Kategorien, von einem Baumstamm zu Zweigen und dann zu Blättern, wodurch kleinere Kategorien innerhalb von Kategorien entstehen.
- Bei der logistischen Regression werden unabhängige Variablen analysiert, um ein binäres Ergebnis zu ermitteln, das in eine von zwei Kategorien fällt.
- Ein Zufallsbaum ist eine Sammlung von Entscheidungsbäumen, die Ergebnisse aus mehreren Prädiktoren zusammenfasst. Er ist besser in der Verallgemeinerung, aber im Vergleich zu Entscheidungsbäumen weniger interpretierbar.
- Eine Support Vector Machine findet eine Linie, welche die Daten in einem gegebenen Satz während des Modelltrainings in bestimmte Klassen unterteilt und die Ränder jeder Klasse maximiert. Diese Algorithmen können zum Vergleich der relativen finanziellen Leistung, des Werts und der Investitionsgewinne verwendet werden.
Regressionsmodelle
Regressionsaufgaben sind anders gelagert, da sie vom Modell erwarten, dass es eine numerische Beziehung zwischen den Eingabe- und Ausgabedaten herstellt. Beispiele für Regressionsmodelle sind die Vorhersage von Immobilienpreisen auf der Grundlage der Postleitzahl, die Vorhersage von Klickraten bei Online-Anzeigen in Abhängigkeit von der Tageszeit und die Bestimmung des Preises, den Kunden für ein bestimmtes Produkt zu zahlen bereit sind, anhand ihres Alters.
Zu den Algorithmen, die üblicherweise in überwachten Lernprogrammen verwendet werden, gehören:
- Die Bayes'sche Logik analysiert statistische Modelle unter Einbeziehung von Vorwissen über Modellparameter oder das Modell selbst.
- Die lineare Regression sagt den Wert einer Variablen auf der Grundlage des Wertes einer anderen Variablen voraus.
- Nichtlineare Regression wird verwendet, wenn eine Ausgabe nicht aus linearen Eingaben reproduzierbar ist. In diesem Fall weisen die Datenpunkte eine nichtlineare Beziehung auf, zum Beispiel können die Daten einen nichtlinearen, kurvigen Trend aufweisen.
- Ein Regressionsbaum ist ein Entscheidungsbaum, bei dem kontinuierliche Werte aus einer Zielvariablen entnommen werden können.
Bei der Auswahl eines Algorithmus für überwachtes Lernen sind einige Dinge zu beachten. Der erste ist die Verzerrung und Varianz, die innerhalb des Algorithmus bestehen, da es einen schmalen Grat gibt zwischen flexibel genug und zu flexibel. Ein weiterer Punkt ist die Komplexität des Modells oder der Funktion, die das System zu erlernen versucht. Wie bereits erwähnt, sollten auch die Heterogenität, Genauigkeit, Redundanz und Linearität der Daten analysiert werden, bevor ein Algorithmus ausgewählt wird.
Überwachtes versus unüberwachtes Lernen
Der Hauptunterschied zwischen unüberwachtem und überwachtem Lernen besteht darin, wie der Algorithmus lernt.
Beim unüberwachten Lernen erhält der Algorithmus unmarkierte Daten als Trainingsmenge. Im Gegensatz zum überwachten Lernen gibt es keine korrekten Ausgabewerte; der Algorithmus ermittelt die Muster und Ähnlichkeiten innerhalb der Daten, anstatt sie mit einer externen Messung in Beziehung zu setzen. Mit anderen Worten: Algorithmen können frei arbeiten, um mehr über die Daten zu lernen und interessante oder unerwartete Ergebnisse zu entdecken, nach denen der Mensch nicht gesucht hat.
Unüberwachtes Lernen wird häufig bei Clustering-Algorithmen (Aufdeckung von Gruppen innerhalb von Daten) und Assoziationen (Vorhersage von Regeln, die die Daten beschreiben) eingesetzt.
Da das Modell des maschinellen Lernens eigenständig arbeitet, um Muster in den Daten zu entdecken, kann es sein, dass das Modell nicht die gleichen Klassifizierungen vornimmt wie beim überwachten Lernen. In dem Beispiel mit den Katzen und Hunden könnte das Modell für unüberwachtes Lernen die Unterschiede, Ähnlichkeiten und Muster zwischen Katzen und Hunden erkennen, kann sie aber nicht als Katzen oder Hunde einstufen.
Vorteile und Einschränkungen
Überwachte Lernmodelle haben einige Vorteile gegenüber dem unüberwachten Ansatz, aber sie haben auch ihre Grenzen. Zu den Vorteilen gehören:
- Systeme mit überwachtem Lernen sind eher in der Lage, Urteile zu fällen, die Menschen nachvollziehen können, da Menschen die Grundlage für Entscheidungen geliefert haben.
- Die Leistungskriterien werden durch die zusätzliche erfahrene Hilfe optimiert.
- Es können Klassifizierungs- und regressive Aufgaben durchgeführt werden.
- Der Benutzer steuert die Anzahl der in den Trainingsdaten verwendeten Klassen.
- Modelle können auf der Grundlage früherer Erfahrungen Vorhersagen treffen.
- Die Klassen von Objekten sind genau markiert.
Zu den Einschränkungen des überwachten Lernens gehören:
- Im Falle einer auf Abfragen basierenden Methode haben Systeme mit überwachtem Lernen Schwierigkeiten, mit neuen Informationen umzugehen. Wenn einem System mit Kategorien für Katzen und Hunde neue Daten vorgelegt werden – zum Beispiel ein Zebra – müsste es fälschlicherweise in die eine oder andere Kategorie eingeordnet werden. Wäre das KI-System hingegen generativ, das heißt unbeaufsichtigt, wüsste es vielleicht nicht, was das Zebra ist, wäre aber in der Lage, es als zu einer eigenen Kategorie gehörig zu erkennen.
- Überwachtes Lernen erfordert in der Regel auch große Mengen korrekt markierter Daten, um ein akzeptables Leistungsniveau zu erreichen, und solche Daten sind nicht immer verfügbar. Unüberwachtes Lernen leidet nicht unter diesem Problem und kann auch mit unmarkierten Daten arbeiten.
- Überwachte Modelle brauchen Zeit, um vor ihrer Verwendung trainiert zu werden.
Halbüberwachtes Lernen
In Fällen, in denen überwachtes Lernen erforderlich ist, es aber an hochwertigen Daten mangelt, kann halbüberwachtes Lernen die geeignete Lernmethode sein. Dieses Lernmodell liegt zwischen dem überwachten und dem unüberwachten Lernen; es akzeptiert Daten, die teilweise markiert sind, das heißt, die meisten Daten sind unmarkiert.
Beim halbüberwachten Lernen werden die Korrelationen zwischen den Datenpunkten ermittelt – genau wie beim unüberwachten Lernen – und dann die markierten Daten verwendet, um diese Datenpunkte zu markieren. Schließlich wird das gesamte Modell auf der Grundlage der neu angelegten Kennzeichnungen trainiert.
Halbüberwachtes Lernen kann genaue Ergebnisse liefern und ist auf viele reale Probleme anwendbar, bei denen die geringe Menge an markierten Daten verhindert, dass überwachte Lernalgorithmen richtig funktionieren. Als Faustregel gilt, dass ein Datensatz mit mindestens 25 Prozent gelabelter Daten für das halbüberwachte Lernen geeignet ist.
Gesichtserkennung beispielsweise ist ideal für halbüberwachtes Lernen; die große Anzahl von Bildern verschiedener Personen wird nach Ähnlichkeit geclustert und dann mit einem markierten Bild verwertet, das den geclusterten Fotos Identität verleiht.
Beispiel für ein Projekt mit überwachtem Lernen
Ein möglicher Anwendungsfall von überwachtem Lernen ist die Kategorisierung von Nachrichten. Ein Ansatz besteht darin, zu bestimmen, zu welcher Kategorie die einzelnen Nachrichten gehören, zum Beispiel Wirtschaft, Finanzen, Technologie oder Sport. Um dieses Problem zu lösen, ist ein überwachtes Modell am besten geeignet.
Der Mensch legt dem Modell verschiedene Nachrichtenartikel und deren Kategorien vor und das Modell lernt, welche Art von Nachrichten zu jeder Kategorie gehört. Auf diese Weise wird das Modell in die Lage versetzt, die Nachrichtenkategorie eines jeden Artikels zu erkennen, den es auf der Grundlage seiner bisherigen Trainingserfahrung betrachtet.
Menschen können jedoch auch zu dem Schluss kommen, dass die Klassifizierung von Nachrichten auf der Grundlage der vorgegebenen Kategorien nicht informativ oder flexibel genug ist, da einige Nachrichten über Klimawandel-Technologien oder die Probleme der Arbeitskräfte in einer Branche berichten können. Es gibt Milliarden von Nachrichtenartikeln, und sie in 40 oder 50 Kategorien einzuteilen, kann eine zu starke Vereinfachung darstellen.
Stattdessen kann ein besserer Ansatz darin bestehen, die Ähnlichkeiten zwischen den Nachrichtenartikeln zu finden und die Nachrichten entsprechend zu gruppieren. Das hieße, stattdessen nach Nachrichtenclustern zu suchen, in denen ähnliche Artikel zusammengefasst werden. Es gibt keine spezifischen Kategorien mehr.
Das ist es, was unüberwachtes Lernen erreicht, indem es die Muster und Ähnlichkeiten innerhalb der Daten bestimmt, im Gegensatz zu einem Bezug zu einer externen Messung.






