Transformer

Was ist ein Transformer?
Ein Transformer ist eine neuronale Netzwerkarchitektur, die automatisch eine Art von Eingabe in eine andere Art von Ausgabe umwandeln kann. Der Begriff wurde in dem Google-Papier Attention Is All You Need aus dem Jahr 2017 geprägt. In diesem Forschungsbericht wurde untersucht, wie die acht Wissenschaftler, die ihn verfasst haben, einen Weg gefunden haben, ein neuronales Netzwerk für die Übersetzung von Englisch nach Französisch mit höherer Genauigkeit in einem Viertel der Trainingszeit anderer neuronaler Netzwerke zu trainieren.
Transformer-Modelle sind besonders geschickt darin, Kontext und Bedeutung zu bestimmen, indem sie Beziehungen in sequenziellen Daten herstellen, wie zum Beispiel eine Reihe von gesprochenen oder geschriebenen Wörtern oder die Beziehungen zwischen chemischen Strukturen. Die in Transformer-Modellen verwendeten mathematischen Techniken werden als Aufmerksamkeitsmechanismus bezeichnet und ermöglichen es den Modellen, die Beziehungen zwischen Datenpunkten zu bestimmen.
Der Begriff der Aufmerksamkeit ist seit den 1990er Jahren als Verarbeitungstechnik bekannt. Im Jahr 2017 schlug das Google-Team jedoch vor, den Aufmerksamkeitsmechanismus nutzen zu können, um die Bedeutung von Wörtern und die Struktur einer bestimmten Sprache direkt zu kodieren. Dies war revolutionär, da es das ersetzte, was zuvor einen zusätzlichen Kodierungsschritt unter Verwendung eines dedizierten neuronalen Netzwerks erforderte. Es eröffnete auch die Möglichkeit, jede Art von Information virtuell zu modellieren, und ebnete den Weg für die außergewöhnlichen Durchbrüche, die sich daraus ergaben.
Die Technik erwies sich als verallgemeinerbarer, als die Autoren annahmen, und Transformer haben sich bei der Erstellung von Texten, Bildern und Roboteranweisungen bewährt. Sie können auch Beziehungen zwischen verschiedenen Datenmodi modellieren, was als multimodale künstliche Intelligenz (KI) bezeichnet wird, um Anweisungen in natürlicher Sprache in Bilder oder Roboteranweisungen umzuwandeln. Die breite Verwendung von Transformer-Modellen und die Trends zur Verallgemeinerung von Transformern haben dazu geführt, dass sie als Basismodelle bezeichnet werden, die allgemeine vortrainierte Modelle bereitstellen, die Organisationen viel schneller und einfacher für bestimmte Zwecke anpassen und optimieren können, als wenn sie ein Modell von Grund auf neu erstellen müssten.
Nahezu alle Anwendungen, die natürliche Sprachverarbeitung (Natural Language Processing, NLP) nutzen, verwenden jetzt Transformer, da sie eine bessere Leistung als frühere Ansätze bieten. Forscher haben auch herausgefunden, dass Transformer-Modelle lernen können, mit chemischen Strukturen zu arbeiten, die Proteinfaltung vorherzusagen und medizinische Daten in großem Maßstab zu analysieren. Transformer sind für alle Anwendungen mit großen Sprachmodellen (Large Language Model, LLM) von entscheidender Bedeutung, darunter ChatGPT und Dall-E von OpenAI, die Google-Suche und Microsoft Copilot.
Was können Transformer?
Transformer verdrängen nach und nach bisher beliebte Arten von Deep-Learning-Architekturen für neuronale Netze in vielen Anwendungen, darunter rekurrente neuronale Netze (RNN) und Convolutional Neural Networks (CNN). RNNs waren ideal für die Verarbeitung von Datenströmen wie Sprache, Sätzen und Code. Sie konnten jedoch jeweils nur kürzere Zeichenketten verarbeiten. Neuere Techniken wie Long Short-Term Memory (langes Kurzzeitgedächtnis) waren RNN-Ansätze, die längere Zeichenketten unterstützen konnten, aber immer noch begrenzt und langsam waren. Im Gegensatz dazu können Transformer längere Reihen und Wörter oder Token parallel verarbeiten, wodurch sie effizienter skaliert werden können.
CNNs eignen sich ideal für die Datenverarbeitung, zum Beispiel für die parallele Analyse mehrerer Bereiche eines Fotos auf Ähnlichkeiten bei Merkmalen wie Linien, Formen und Texturen. Diese Netzwerke sind für den Vergleich benachbarter Bereiche optimiert. Transformer-Modelle, wie der 2021 eingeführte Vision Transformer, sind dagegen besser für den Vergleich von Regionen geeignet, die weit voneinander entfernt sind, und haben sich in Computer-Vision-Anwendungen bewährt. Transformer eignen sich auch besser für die Arbeit mit ungelabelten Daten.
Transformer können lernen, die Bedeutung eines Textes effizient darzustellen, indem sie größere Mengen ungelabelter Daten analysieren. Dadurch können Forscher Transformer so skalieren, dass sie Hunderte Milliarden und sogar Billionen von Merkmalen unterstützen. In der Praxis dienen die mit ungelabelten Daten vortrainierten Modelle nur als Ausgangspunkt für die weitere Verfeinerung für eine bestimmte Aufgabe mit gelabelten Daten. Dies ist jedoch akzeptabel, da der zweite Schritt weniger Fachwissen und Rechenleistung erfordert.
Transformer haben sich in einer Vielzahl von direkten KI-Anwendungsfällen bewährt, darunter die folgenden:
- Verarbeitung natürlicher Sprache. Transformer können menschliche Sprachen nahezu in Echtzeit aufnehmen, verstehen, übersetzen und replizieren.
- Finanz- und Sicherheitsaufgaben. Transformer können umfangreiche Finanz- oder Netzwerk-Traffic-Daten verarbeiten und analysieren, um Anomalien zu erkennen und zu melden, und so zur Verhinderung von Betrug und Sicherheitsverletzungen beitragen.
- Ideenanalyse. Transformer-Modelle können umfangreiche Informationen aufnehmen und verarbeiten und geeignete Zusammenfassungen oder Skizzen erstellen.
- Simulierte KI-Einheiten. Softwareprogramme wie Chatbots können Sprach-, Analyse- und Zusammenfassungsfunktionen kombinieren, die für die Interaktion mit Menschen, die Beantwortung von Fragen und die Unterstützung bei der Problemlösung entwickelt wurden. Google Gemini ist ein Beispiel hierfür.
- Pharmazeutische Analyse und Entwicklung. Transformer können Forschern bei der chemischen und DNA-Analyse unterstützen und die Entwicklung und Verfeinerung leistungsfähiger neuer Medikamente beschleunigen.
- Medienerstellung. Transformer-Modelle können generative Bilder, Videos und Musik auf der Grundlage der Textaufforderung des Benutzers erzeugen. Ein Beispiel hierfür ist Dall-E von OpenAI.
- Programmieraufgaben. Transformer-Modelle können Codesegmente vervollständigen, Code analysieren und optimieren und umfangreiche Tests durchführen.
Wie sieht die Architektur eines Transformer-Modells aus?
Eine Transformer-Architektur besteht aus einem Encoder und einem Decoder, die zusammenarbeiten. Der Aufmerksamkeitsmechanismus ermöglicht es dem Transformer, die Bedeutung von Wörtern auf der Grundlage der geschätzten Wichtigkeit anderer Wörter oder Token zu kodieren. Dadurch können Transformer alle Wörter oder Token parallel verarbeiten, um die Leistung zu steigern und das Wachstum immer größerer LLMs voranzutreiben.
Mit Hilfe des Aufmerksamkeitsmechanismus wandelt der Encoder-Block jedes Wort oder jeden Token in Vektoren um, die durch andere Wörter weiter gewichtet werden. In den folgenden zwei Sätzen wird die Bedeutung von ihn beispielsweise unterschiedlich gewichtet, da sich das Wort von füllte zu leerte ändert:
- Er goss den Krug in den Becher und füllte ihn.
- Er goss den Krug in den Becher und leerte ihn.
Der Aufmerksamkeitsmechanismus verbindet ihn mit dem Befüllen des Bechers im ersten Satz und dem Leeren des Kruges im zweiten Satz.
Der Decoder kehrt den Prozess in der Zieldomain im Wesentlichen um. Der ursprüngliche Anwendungsfall war die Übersetzung von Englisch nach Französisch, aber derselbe Mechanismus könnte kurze englische Fragen und Anweisungen in längere Antworten übersetzen. Umgekehrt könnte er einen längeren Artikel in eine prägnantere Zusammenfassung übersetzen.
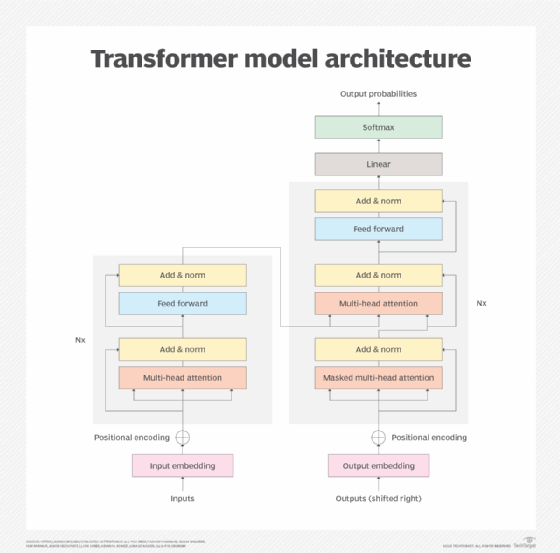
Ein typisches Transformer-Modell besteht aus sechs Hauptelementen, wobei ein Modell mehrere Instanzen einiger Elemente enthalten kann:
- Eingabe. Die Eingabeeinbettung wandelt einen Rohdatenstrom in einen Datensatz um, den das Modell verarbeiten kann. Beispielsweise können gesprochene oder geschriebene Wörter in Daten umgewandelt werden. Die aus dieser Umwandlung resultierenden Daten erfassen Merkmale der Eingabe, wie zum Beispiel die Semantik und Syntax von Wörtern. Die bei dieser Umwandlung erzeugten Daten sind ein Merkmal des Modelltrainingsprozesses. Der Rest des Modells kann die resultierenden Daten verarbeiten.
- Positionskodierung. Transformer-Modelle enthalten keine native Erfassung der Eingabeposition oder -reihenfolge, sodass die Positionskodierung diese Datenlücke füllt und Informationen über die Position der eingegebenen Daten ableitet. Beispielsweise kennen Transformer die Reihenfolge der Wörter in einem Satz nicht, sodass die Positionskodierung dem Modell die Position der Wörter innerhalb des Satzes mitteilt. Dies bringt zusätzliche Erkenntnisse und ermöglicht es dem Modell, die Reihenfolge der Wörter zu bewerten.
- Aufmerksamkeitsmechanismus. Das Herzstück des Transformer-Modells ist der Aufmerksamkeitsmechanismus, bei dem es sich in der Regel um einen fortgeschrittenen Multihead-Selbstaufmerksamkeitsmechanismus handelt. Dieser Mechanismus ermöglicht es dem Modell, die Wichtigkeit jedes Datenelements zu verarbeiten und zu bestimmen oder zu überwachen. Multihead bedeutet, dass mehrere Iterationen des Mechanismus parallel ablaufen, sodass das Modell verschiedene Beziehungen zwischen den Daten untersuchen und die wahrscheinlichste oder sinnvollste Beziehung bestimmen kann.
- Feedforward-Netzwerke. Ein nichtlineares neuronales Netz wandelt dann die durch den Aufmerksamkeitsmechanismus erstellten Darstellungen um. Diese neuronalen Netze ermöglichen es dem Transformer-Modell, komplexe Muster und Nuancen in den Daten zu lernen, die detaillierter und genauer sind als der Aufmerksamkeitsmechanismus allein.
- Normalisierung. Die Datennormalisierung ermöglicht es dem Modell, die von ihm verarbeiteten Datenwerte zu standardisieren oder mit Leitplanken zu versehen. Dadurch wird das Modell vor extremen Datenwerten oder ungewöhnlichen Schwankungen geschützt, die den Transformer-Prozess verzerren und zu einer schlechten Ausgabe führen können. Zusätzliche Normalisierungstechniken, wie zum Beispiel Residual-Verbindungen, werden eingesetzt, um das Problem der verschwindenden Gradienten (Vanishing Gradient) zu lösen, wenn das Modell schwer zu trainieren ist.
- Ausgabe. Der Ausgabemechanismus ist für die Generierung der endgültigen Ausgabe für das Modell verantwortlich. Dies umfasst in der Regel eine lineare Transformation zusammen mit einer Softmax-Funktion, die Vektornummern in eine Wahrscheinlichkeitsverteilung umwandelt. Beispielsweise wählt ein Englisch-Deutsch-Übersetzer die Wörter auf Deutsch aus und ordnet sie an. Während die Ausgabe in der Regel Wort für Wort erstellt wird, können fortgeschrittene Transformer ganze Sätze oder Absätze gleichzeitig produzieren. Text kann direkt angezeigt werden, oder Sprache kann durch zusätzliche Text-zu-Sprache-Umwandlung erzeugt werden.
Training des Transformer-Modells
Das Training eines Transformers umfasst zwei wichtige Phasen. In der ersten Phase verarbeitet ein Transformer eine große Menge unmarkierter Daten, um die Struktur der Sprache oder eines Phänomens, wie zum Beispiel die Proteinfaltung, zu erlernen und zu verstehen, wie sich benachbarte Elemente gegenseitig zu beeinflussen scheinen. Dies ist ein kostspieliger und energieintensiver Aspekt des Prozesses.
Sobald das Modell trainiert ist, ist es hilfreich, es für eine bestimmte Aufgabe zu optimieren. Ein Technologieunternehmen möchte möglicherweise einen Chatbot so einstellen, dass er auf verschiedene Kundendienst- und technische Support-Anfragen mit unterschiedlichem Detaillierungsgrad reagiert, je nach Wissensstand des Benutzers. Eine Anwaltskanzlei könnte ein Modell für die Analyse von Verträgen anpassen. Ein Entwicklungsteam könnte das Modell auf seine umfangreiche Code-Bibliothek und einzigartigen Codierungskonventionen abstimmen.
Der Feinabstimmungsprozess erfordert deutlich weniger Fachwissen und Rechenleistung. Befürworter des Transformer-Modells argumentieren, dass sich die hohen Kosten für die Schulung größerer Allzweckmodelle oder Basismodelle auszahlen können, da sie Zeit und Geld bei der Anpassung des Modells für so viele verschiedene Anwendungsfälle sparen.
Die Anzahl der Funktionen in einem Modell wird manchmal als Ersatz für seine Leistung verwendet, anstatt aussagekräftigere Metriken zu verwenden. Die Anzahl der Funktionen – oder die Größe des Modells – korreliert jedoch nicht direkt mit der Leistung oder dem Nutzen. Es ist möglich, ein Modell mit mehr Parametern zu trainieren und dennoch Ergebnisse zu erzielen, die weniger präzise sind als das gleiche Modell, das mit weniger Parametern trainiert wurde. In der Praxis sind Modelle, die mit großen Datenmengen trainiert wurden, oft hilfreich für breitere Einsatzmöglichkeiten, bei denen eine geringere Präzision akzeptabel ist.
Beispiele für Transformer
Transformer-Implementierungen werden immer besser, was die Größe und die Unterstützung neuer Anwendungsfälle oder verschiedener Bereiche wie Medizin, Wissenschaft oder Geschäftsanwendungen angeht. Im Folgenden sind einige der vielversprechendsten Transformer-Implementierungen aufgeführt:
- Bidirectional Encoder Representations from Transformers (BERT) von Google war eines der ersten LLMs, das auf Transformer basierte. Es gibt unzählige verschiedene BERT-Versionen, darunter BERT base, BERT large, RoBERTa, DistilBERT, TinyBERT, ALBERT, ELECTRA und FinBERT.
- Die GPT-Modelle von OpenAI folgten diesem Beispiel und durchlief mehrere Iterationen, darunter GPT-2, GPT-3, GPT-3.5, GPT-4 und GPT-4o. GPT-5 befindet sich derzeit in der Entwicklung.
- Llama von Meta erreicht eine vergleichbare Leistung mit Modellen, die zehnmal so groß sind. Llama 3.3, das im Dezember 2024 veröffentlicht wurde, konnte seine Fähigkeiten noch einmal ausbauen.
- Das Pathways Language Model (PaLM) von Google verallgemeinert und führt Aufgaben in mehreren Bereichen aus, darunter Text, Bild und Robotersteuerungen. PaLM 2 ist zusammen mit den beliebten Gemini-Modellen verfügbar.
- Dall-E 3 erstellt Bilder aus einer kurzen Textbeschreibung.
- Die University of Florida und Nvidias Gatortron analysieren unstrukturierte Daten aus medizinischen Aufzeichnungen. Dabei wird das Transformer-basierte Sprachmodellierungs-Framework Nvidias Megatron auf einem DGX SuperPOD mit über 1.000 A100-Grafikprozessoren verwendet.
- Google DeepMinds AlphaFold 3 beschreibt, wie sich Proteine falten, und kann Wechselwirkungen zwischen Proteinen und anderen Molekülen vorhersagen.
- MegaMolBART von AstraZeneca und Nvidia generiert neue kleinmolekulare Arzneimittelkandidaten auf der Grundlage chemischer Strukturdaten.
Erfahren Sie mehr über Künstliche Intelligenz (KI) und Machine Learning (ML)
-
![]()
Basiswissen GPT-4o: Funktionen und Einschränkungen im Überblick
Von: Sean Kerner
-
![]()
Convolutional versus Recurrent Neural Networks: ein Vergleich
Von: David Petersson
-
![]()
Die Geschichte der künstlichen Intelligenz: eine Zeitleiste
Von: Ron Karjian
-
![]()
Was sind die Unterschiede zwischen ChatGPT und GPT?
Von: George Lawton



