Retrieval-augmented Generation (RAG)

Was ist Retrieval-augmented Generation (RAG)?
Retrieval-augmented Generation (RAG) ist ein Framework für künstliche Intelligenz (KI), das Daten aus externen Wissensquellen abruft, um die Qualität der Antworten von zum Beispiel KI-Chatbots zu verbessern. Diese Technik zur Verarbeitung natürlicher Sprache wird häufig verwendet, um große Sprachmodelle (Large Language Model, LLM) genauer und aktueller zu machen.
LLMs sind KI-Modelle, die Chatbots wie ChatGPT von OpenAI und Google Bard antreiben. LLMs können neue Inhalte verstehen, zusammenfassen, generieren und vorhersagen. Dennoch können sie inkonsistent sein und bei einigen wissensintensiven Aufgaben versagen – insbesondere bei Aufgaben, die außerhalb ihrer ursprünglichen Trainingsdaten liegen oder aktuelle Informationen und Transparenz darüber erfordern, wie sie ihre Entscheidungen treffen. Wenn dies geschieht, kann das LLM falsche Informationen liefern, auch bekannt als KI-Halluzination.
Durch das Abrufen von Informationen aus externen Quellen, wenn die trainierten Daten des LLM nicht ausreichen, verbessert sich die Qualität der LLM-Antworten. Das Abrufen von Informationen aus einer Online-Quelle ermöglicht es dem LLM beispielsweise, auf aktuelle Informationen zuzugreifen, auf die er ursprünglich nicht trainiert wurde.
Was macht die RAG?
LLMs werden in der Regel offline trainiert, so dass das Modell von Daten, die nach dem Training des Modells erstellt wurden, nichts weiß. Retrieval-augmented Generation (RAG) wird verwendet, um Daten von außerhalb des LLMs abzurufen, das dann die Eingabeaufforderungen des Benutzers ergänzt, indem es die relevanten abgerufenen Daten in seine Antwort einfügt.
Dieser Prozess hilft, offensichtliche Wissenslücken und KI-Halluzinationen zu reduzieren. Dies kann in Bereichen wichtig sein, in denen möglichst viele aktuelle und genaue Informationen benötigt werden, wie zum Beispiel im Gesundheitswesen.
Wie man RAG mit LLMs verwendet
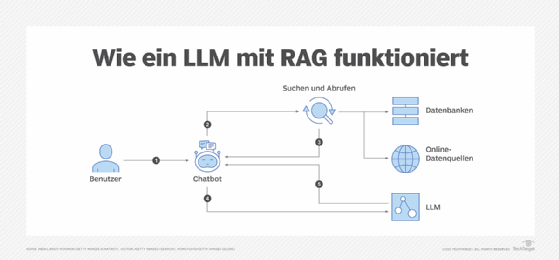
RAG kombiniert die Informationsbeschaffung mit einem Textgeneratormodell. Externes Wissen kann aus Datenquellen, Online-Quellen, Programmierschnittstellen, Datenbanken oder Dokumentenspeichern abgerufen werden.
Am Beispiel eines Chatbots: Sobald ein Benutzer eine Frage eingibt, fasst RAG diese Frage mit Hilfe von Schlüsselwörtern oder semantischen Daten zusammen. Die umgewandelten Daten werden anschließend an eine Suchplattform gesendet, um die angeforderten Daten abzurufen, die dann auf der Grundlage der Relevanz sortiert werden.
Das LLM synthetisiert dann die abgerufenen Daten mit der erweiterten Eingabeaufforderung und seinen internen Trainingsdaten, um eine generierte Antwort zu erstellen, die an den Chatbot mit entsprechenden Links für den Benutzer weitergegeben werden kann.
Was sind die Vorteile von RAG?
Zu den Vorteilen eines RAG-Modells gehören:
- Bietet aktuelle Informationen. RAG bezieht Informationen aus relevanten, zuverlässigen und aktuellen Quellen.
- Erhöht das Vertrauen der Benutzer. Die Nutzer können auf die Quellen des Modells zugreifen, was die Transparenz und das Vertrauen in den Inhalt fördert und es den Nutzern ermöglicht, dessen Richtigkeit zu überprüfen.
- Reduziert KI-Halluzinationen. Da sich LLMs auf externe Daten stützen, hat das Modell weniger Chancen, falsche Informationen zu erfinden oder zu liefern.
- Reduziert die Rechen- und Finanzkosten. Unternehmen müssen keine Zeit und Ressourcen aufwenden, um das Modell ständig mit neuen Daten zu trainieren.
- Synthetisiert Informationen. RAG synthetisiert Daten, indem es relevante Informationen aus Retrieval- und generativen Modellen kombiniert, um eine Antwort zu geben.
- Leichter zu trainieren. Da RAG auf abgerufenes Wissen zurückgreift, ist es weniger notwendig, das LLM mit einer großen Menge an Trainingsdaten zu trainieren.
- Kann für mehrere Aufgaben verwendet werden. Abgesehen von Chatbots kann RAG für eine Vielzahl spezifischer Anwendungsfälle, wie zum Beispiel Textzusammenfassung und Dialogsysteme, fein abgestimmt werden.





