Redundanz (redundant)
Was ist Redundanz (redundant)?
Datenredundanz beschreibt die Praxis, Informationen an mehreren Stellen innerhalb einer Datenbank oder eines Storage-Systems zu speichern, sei es lokal oder in geografisch verteilten Systemen. Diese Strategie gewährleistet, dass ein Unternehmen seine Abläufe und Dienstleistungen auch dann aufrechterhalten kann, wenn es zu Problemen mit den Daten kommt, etwa bei einer Beschädigung oder einem Verlust. Das Konzept der Datenredundanz findet Anwendung in verschiedenen Bereichen wie Datenbanken, Speichermedien und Dateisystemen.
Absichtliche und unbeabsichtigte Redundanz
Datenredundanz kann in Organisationen sowohl absichtlich als auch unbeabsichtigt entstehen. Bei absichtlicher Redundanz werden identische Daten an unterschiedlichen Orten gespeichert, wobei das Unternehmen aktiv darauf achtet, diese Informationen zu schützen und ihre Konsistenz zu wahren. Solche Daten werden häufig für Backups oder zur Unterstützung von Disaster-Recovery-Strategien genutzt.
Im Gegensatz dazu kann unbeabsichtigte Redundanz zu Inkonsistenzen führen. Obwohl Datenredundanz dazu beiträgt, das Risiko eines Datenverlusts zu verringern, können Probleme durch redundante Daten auftreten, insbesondere bei umfangreichen Datensätzen. Daten, die an mehreren Standorten gespeichert sind, beanspruchen wertvollen Speicherplatzund erschweren es dem Unternehmen, den Überblick darüber zu behalten, auf welche Informationen zugegriffen oder welche aktualisiert werden sollten.
Technische Aspekte der Redundanz
Der Begriff redundant wird auch in verschiedenen technischen Kontexten verwendet:
- Backup-Systeme: Computer- oder Netzwerksystemkomponenten, die als Sicherheitsmaßnahme für primäre Ressourcen installiert sind, um im Falle eines Ausfalls einspringen zu können.
- Überflüssige Informationen: Daten, die nicht benötigt werden oder mehrfach vorhanden sind.
- Redundante Bits: Zusätzliche binäre Ziffern, die während der Datenübertragung erzeugt werden, um sicherzustellen, dass keine Bits verloren gehen.
- Schutz vor Festplattenausfällen: Redundante Daten in einem Speicher-Array, die dazu dienen, im Falle eines Festplattenausfalls einen Verlust von Informationen zu verhindern.
Insgesamt ist die Verwaltung von Datenredundanz ein wichtiger Aspekt der Datensicherheit und -integrität in modernen Informationssystemen.
Funktionsweise der Datenredundanz
Daten müssen an zwei oder mehr Stellen gespeichert werden, damit sie als redundant gelten. Wenn die primären Daten beschädigt werden oder die Festplatte, auf der sich die Daten befinden, ausfällt, bietet der zusätzliche Datensatz eine Ausfallsicherung, auf die das Unternehmen ausweichen kann.
Bei den redundanten Daten kann es sich entweder um eine vollständige Kopie der Originaldaten oder um ausgewählte Daten handeln. Die Aufbewahrung ausgewählter Daten ermöglicht es einem Unternehmen, verlorene oder beschädigte Daten zu rekonstruieren. Festplatten mit Datenkopien werden in einem Array gespeichert, so dass im Falle eines Schadens an den Originaldaten das Array mit geringer oder gar keiner Ausfallzeit einspringen kann. Darüber hinaus können Redundanzmaßnahmen durch Backups oder RAID-Systeme erreicht werden.
Die Vor- und Nachteile der Datenredundanz im Vergleich
Die Datenredundanz hat je nach Umsetzung Vorteile oder Risiken. Zu den möglichen Vorteilen gehören folgende:
- Sie trägt zum Schutz der Daten bei. Wenn auf Daten nicht zugegriffen werden kann, können redundante Daten dazu beitragen, fehlende Daten zu ersetzen oder wiederherzustellen.
- Das Hosting mehrerer Speicherorte für dieselben Daten bedeutet, dass ein Datenverwaltungssystem etwaige Unterschiede auswerten kann, wodurch die Genauigkeit der Daten gewährleistet wird.
- Schneller Zugriff. In einer Organisation, die sich über verschiedene physische Bereiche erstreckt, kann der Zugriff auf bestimmte Datenstandorte einfacher sein als auf andere. Eine Person innerhalb einer Organisation kann auf Daten aus redundanten Quellen zugreifen, um schneller auf dieselben Daten zugreifen zu können.
Zu den möglichen Nachteilen gehören jedoch die folgenden:
- Vergrößerung der Datenbank. Es wird mehr Speicherplatz für eine redundante Kopie einer großen Datenmenge benötigt. Eine größere Datenbank kann auch zu längeren Ladezeiten führen oder Verwirrung stiften, wenn die Mitarbeiter nicht wissen, wo bestimmte Daten gespeichert sind.
- Ein höherer Speicherbedarf bedeutet auch höhere Kosten, abgesehen von den zusätzlichen Gemeinkosten oder Ressourcen, die für die Pflege und Aktualisierung der redundanten Daten benötigt werden.
- Die Speicherung von Daten an mehreren Orten kann zu Diskrepanzen führen, zum Beispiel zu fehlenden Datensätzen oder falschen Werten, wenn die Daten nicht ständig aktualisiert werden.
- Die Speicherung mehrerer Kopien derselben Daten erhöht das Risiko einer Datenbeschädigung. Beschädigte Daten können durch Fehler beim Schreiben, Lesen, Speichern oder Verarbeiten von Daten entstehen.
Redundanz in Storage-Systemen
Wenn es um die Nutzung von Speicher geht, kann Redundanz ein Schutz sein oder die Form von unerwünschtem Overhead annehmen. Datenvolumen enthalten oft redundante Speicherblöcke. Ein Deduplizierungsprozess kann diese redundanten Blöcke entfernen, um den Speicherverbrauch innerhalb der Daten zu reduzieren oder das Volumen der zu sichernden Daten zu minimieren.
Viele Unternehmen erstellen absichtlich redundante Kopien von Daten, um das Risiko eines Datenverlustes zu minimieren. Diese Redundanz kann in Form von gespiegelten virtuellen Maschinen (VMs), Speicher-Volumes oder einer externen, synchronisierten Datenkopie vorliegen.
Backup vs. Datenredundanz
Datenredundanz und Backups sollen beide Datenverluste verhindern, aber die Technologien unterscheiden sich leicht. Die Datenredundanz erfolgt häufig in Form einer synchronisierten Kopie der Unternehmensdaten. Ein Unternehmen kann zum Beispiel eine redundante VM oder ein redundantes Speicher-Volume erstellen.
Datenredundanz kann dazu beitragen, Serviceausfälle zu verhindern. Wenn zum Beispiel eine VM ausfällt, kann eine Replik-VM schnell online gebracht werden, um die Serviceunterbrechung zu minimieren.
Backups hingegen sind Kopien von Daten und anderen Ressourcen. Backups dienen speziell der Erstellung von Datenkopien für den Fall, dass ein Unternehmen einen Datenverlust erleidet, zum Beispiel durch fehlerhafte Software, Datenbeschädigung, Hardwarefehler, böswillige Hackerangriffe, Benutzerfehler oder andere unvorhergesehene Ereignisse. Während es bei der Redundanz darum geht, die Kontinuität der Dienste eines Unternehmens zu gewährleisten, geht es bei der Datensicherung eher darum, ein System in einen früheren Zustand zurückzubringen.
Es gibt jedoch Überschneidungen zwischen Redundanz und Backups. Backups und einige Datenredundanzprodukte bieten Point-in-Time-Wiederherstellungsfunktionen, aber Redundanzprodukte haben im Allgemeinen weniger Optionen für die Wiederherstellungspunkte. Backups sind auch eine gute Wahl für eine granulare Wiederherstellung, die es einem Unternehmen ermöglicht, mit einem einzigen Backup-Vorgang sowohl Dateien als auch Images wiederherzustellen. Im Gegensatz dazu sind redundante Systeme besser für Situationen geeignet, in denen das Unternehmen kritische Systeme online halten muss und keine lange Wiederherstellungszeit tolerieren kann.
RAID-Technologie für Datenredundanz nutzen
RAID ist eine der gängigsten Formen der Datenredundanz. RAID-Arrays sind so konzipiert, dass sie eine bessere Leistung und Zuverlässigkeit bieten, als dies mit einer einzelnen Festplatte möglich ist.
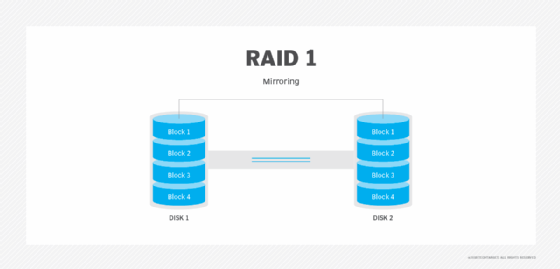
RAID bezieht sich auf verschiedene Speicherarchitekturen, die als RAID-Level bezeichnet werden. Nicht alle RAID-Level bieten Datenredundanz, die meisten jedoch schon. RAID 1 zum Beispiel spiegelt Festplatten, so dass eine exakte Kopie der Festplatte verwendet werden kann, wenn die primäre Kopie ausfällt.
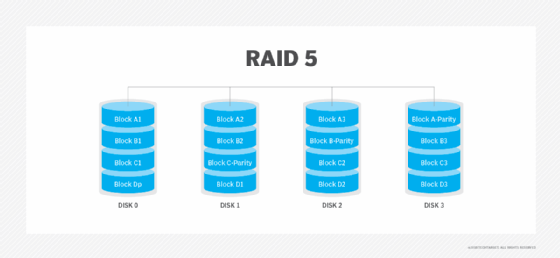
RAID 5 bietet Redundanz durch die Verwendung von Parität. Die Daten werden über alle Festplatten im Array verteilt, so dass weniger Daten auf mehrere Festplatten verteilt werden. Jede Festplatte enthält außerdem Paritätsinformationen, die das Array im Falle eines Festplattenausfalls funktionsfähig halten können. Wenn eine ausgefallene Platte ersetzt wird, werden die Paritätsinformationen verwendet, um den Inhalt der ausgefallenen Platte auf der neuen Platte zu rekonstruieren.
Es gibt viele andere RAID-Level, die Daten durch Redundanz schützen. Parität und Spiegelung sind zwei der gängigsten Beispiele.
Alternative Verfahren für die Implementierung von Datenredundanz
Wenn sich ein Unternehmen nicht ausschließlich auf die Datenredundanz verlassen möchte, gibt es andere Alternativen für den Schutz oder die Wiederherstellung von Daten. So gibt es beispielsweise Backups, Continuous Data Protection(CDP), Snapshots und Image-basierte Backups.
- Backups bringen ein System in einen früheren Zustand zurück. Ziel ist es, im Bedarfsfall eine schnelle und zuverlässige Datenwiederherstellung zu gewährleisten.
- CDP schützt Daten auf einer nahezu kontinuierlichen Basis. Bei CDP-Produkten werden die Daten zunächst blockweise auf ein plattenbasiertes Backup repliziert. Die Software überwacht dann die Daten auf Änderungen an den gespeicherten Blöcken oder auf die Erstellung neuer Blöcke. Wenn ein Block erstellt oder geändert wird, wird er gesichert. Ein Index verfolgt die Versionsinformationen und die Datendeduplizierung stellt sicher, dass nur eindeutige Blöcke auf dem Sicherungsmedium gespeichert werden.
- Snapshots erstellen niemals eine Kopie der Daten. Stattdessen erstellen sie ein Teilabbild einer VM, Datei oder Anwendung zu einem bestimmten Zeitpunkt. Snapshots ermöglichen es einem Unternehmen, Daten auf einen früheren Zeitpunkt zurückzusetzen, wenn etwas schiefläuft.
- Image-basierte Backups sind ähnlich wie Snapshots, erfassen aber ein Image einer VM als Ganzes. Wenn ein Wiederherstellungsvorgang erforderlich ist, wird normalerweise eine Kopie der VM in einer Sandbox-Umgebung gemountet, damit die Daten extrahiert werden können.






