Parser

Was ist ein Parser?
In der Computertechnik ist ein Parser ein Programm, das in der Regel Teil eines Compilers ist. Es empfängt Eingaben in Form von sequenziellen Quellprogrammanweisungen, interaktiven Online-Befehlen, Markup-Tags oder einer anderen definierten Schnittstelle.
Parser zerlegen die Eingaben, die sie erhalten, in Teile wie Substantive (Objekte), Verben (Methoden) und ihre Attribute oder Optionen. Diese werden dann von anderen Programmierern verwaltet, zum Beispiel von anderen Komponenten eines Compilers. Ein Parser kann auch überprüfen, ob alle erforderlichen Eingaben gemacht wurden.
Wie funktioniert Parsen?
Ein Parser ist ein Programm, das Teil des Compilers ist, und das Parsing ist Teil des Compilier-Prozesses. Das Parsen erfolgt während der Analysephase der Kompilierung.
Beim Parsen wird der Code aus dem Präprozessor entnommen, in kleinere Teile zerlegt und analysiert, damit andere Software ihn verstehen kann. Der Parser tut dies, indem er aus den Eingabeteilen eine Datenstruktur aufbaut.
Genauer gesagt, schreibt eine Person Code in einer für Menschen lesbaren Sprache wie C++ oder Java und speichert ihn als eine Reihe von Textdateien. Der Parser nimmt diese Textdateien als Eingabe und zerlegt sie so, dass sie auf der Zielplattform übersetzt werden können.
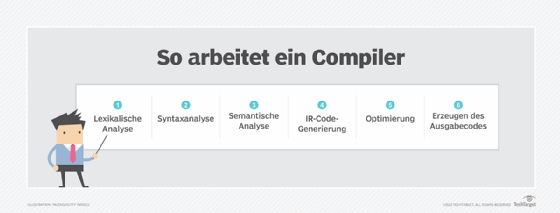
Der Parser besteht aus drei Komponenten, von denen jede eine andere Phase des Parsing-Prozesses übernimmt. Die drei Stufen sind:
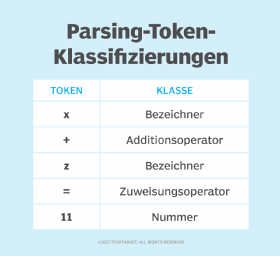
Stufe 1: Lexikalische Analyse
Ein lexikalischer Analysator – oder Scanner – nimmt den Code aus dem Präprozessor und zerlegt ihn in kleinere Teile. Er gruppiert den Eingabecode in Zeichenfolgen, die Lexeme genannt werden und jeweils einem Token entsprechen. Token sind Grammatikeinheiten in der Programmiersprache, die der Compiler versteht. Lexikalische Analysatoren entfernen auch Leerzeichen, Kommentare und Fehler aus der Eingabe.
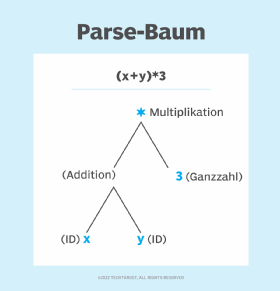
Stufe 2: Syntaktische Analyse
In dieser Phase des Parsings wird die syntaktische Struktur der Eingabe anhand einer Datenstruktur überprüft, die als Parse-Baum oder Ableitungsbaum bezeichnet wird. Ein Syntax-Analysator verwendet Token, um einen Parse-Baum zu konstruieren, der die vordefinierte Grammatik der Programmiersprache mit den Token der Eingabezeichenfolge kombiniert. Der syntaktische Analysator meldet einen Syntaxfehler, wenn die Syntax nicht korrekt ist.
Stufe 3: Semantische Analyse
Die semantische Analyse prüft den Parse-Baum anhand einer Symboltabelle und stellt fest, ob er semantisch konsistent ist. Dieser Prozess wird auch als kontextsensitive Analyse bezeichnet. Er umfasst die Überprüfung des Datentyps, des Labels und der Flusskontrolle.
Wenn der bereitgestellte Code wie folgt aussieht:
float a = 30.2; float b = a*20
dann wird der Analysator 20 als 20,0 behandeln, bevor er die Operation ausführt.
In einigen Quellen wird nur die syntaktische Analyse als Parsing bezeichnet, da sie den Parse-Baum erzeugt. Sie lassen die lexikalische und semantische Analyse außer Acht.
Welches sind die wichtigsten Arten von Parsern?
Wenn eine Softwaresprache entwickelt wird, müssen ihre Schöpfer eine Reihe von Regeln festlegen. Diese Regeln bilden die Grammatik, die benötigt wird, um gültige Aussagen in der Sprache zu konstruieren.
Im Folgenden finden Sie eine Reihe von grammatikalischen Regeln für eine einfache fiktive Sprache, die nur wenige Wörter enthält:
<Satz> ::= <Subjekt> <Verb> <Objekt>
<Subjekt> ::= <Artikel> <Substantiv>
<Artikel> ::= der | die
<Substantiv> ::= Hund | Katze | Mensch
<Verb> ::= laufen | füttern
<Objekt> ::= <Artikel> <Nomen>
In dieser Sprache muss ein Satz ein Subjekt, ein Verb und ein Substantiv in dieser Reihenfolge enthalten, und bestimmte Wörter werden den Wortarten zugeordnet. Ein Subjekt ist ein Artikel, gefolgt von einem Substantiv. Ein Substantiv kann eines der folgenden drei Wörter sein: Hund, Katze oder Mensch. Und ein Verb kann nur laufen oder füttern sein.
Beim Parsing wird eine vom Benutzer eingegebene Aussage anhand dieser Regeln geprüft, um zu beweisen, dass die Aussage gültig ist. Verschiedene Parsing-Algorithmen prüfen in unterschiedlicher Reihenfolge. Es gibt zwei Haupttypen von Parsern:
- Top-down-Parser. Diese beginnen mit einer Regel an der Spitze, wie <Satz> ::= <Subjekt> <Verb> <Objekt>. Bei der Eingabe Die Person hat eine Katze gefüttert würde der Parser mit der ersten Regel beginnen und sich dann durch alle Regeln arbeiten, um sicherzustellen, dass sie korrekt sind. In diesem Fall ist das erste Wort ein <Subjekt>, es folgt der Subjektregel, und der Parser liest den Satz weiter und sucht nach einem <Verb>.
- Bottom-up-Parser. Diese beginnen mit der Regel am Ende. In diesem Fall würde der Parser zuerst nach einem <Objekt> suchen, dann nach einem <Verb> und so weiter.
Einfacher ausgedrückt: Top-Down-Parser beginnen ihre Arbeit beim Startsymbol der Grammatik am oberen Ende des Parse-Baums. Sie arbeiten sich dann von der Regel bis zum Satz vor. Bottom-up-Parser arbeiten sich vom Satz bis zur Regel vor.
Neben diesen Typen ist es wichtig, die beiden Arten der Ableitung zu kennen. Die Ableitung ist die Reihenfolge, in der die Grammatik die eingegebene Zeichenkette zusammensetzt. Sie sind:
- LL-Parser. Diese parsen die Eingabe von links nach rechts und verwenden die Ableitung von links, um die Regeln in der Grammatik mit der Eingabe abzugleichen. Durch diesen Prozess wird eine Zeichenkette abgeleitet, die die Eingabe validiert, indem das am weitesten links stehende Element des Parse-Baums erweitert wird.
- LR-Parser. Diese parsen die Eingabe von links nach rechts unter Verwendung der Ableitung von rechts. Bei diesem Verfahren wird eine Zeichenkette abgeleitet, indem das äußerste rechte Element des Parse-Baums erweitert wird.
Darüber hinaus gibt es noch andere Arten von Parsern, darunter:
- Rekursiver Abstieg. Rekursiv absteigende Parser gehen nach jedem Entscheidungspunkt zurück, um die Genauigkeit zu überprüfen. Rekursive Abstieg-Parser verwenden Top-Down-Parsing.
- Earley-Parser. Diese parsen alle kontextfreien Grammatiken, im Gegensatz zu LL- und LR-Parsern. Die meisten realen Programmiersprachen verwenden keine kontextfreien Grammatiken.
- Shift-Reduce-Parser. Diese Parser verschieben und reduzieren eine Eingabezeichenkette. In jeder Phase der Zeichenkette wird das Wort auf eine Grammatikregel reduziert. Bei diesem Ansatz wird die Zeichenkette so lange reduziert, bis sie vollständig überprüft wurde.
Welche Technologien verwenden Parsing?
Parser werden eingesetzt, wenn Eingabedaten aus dem Quellcode abstrakt als Datenstruktur dargestellt werden müssen, damit sie auf die korrekte Syntax geprüft werden können. Programmiersprachen und andere Technologien verwenden zu diesem Zweck eine Art von Parsing.
Zu den Technologien, die Parsing zur Überprüfung von Code-Eingaben verwenden, gehören:
Programmiersprachen. Parser werden in allen höheren Programmiersprachen verwendet, einschließlich der folgenden:
- C++
- Extensible Markup Language (XML)
- Hypertext Markup Language (HTML)
- Hypertext Preprocessor (PHP)
- Java
- JavaScript
- JavaScript Object Notation (JSON)
- Perl
- Python
Datenbanksprachen. Datenbanksprachen wie Structured Query Language (SQL) verwenden ebenfalls Parser.
Protokolle. Protokolle wie das Hypertext Transfer Protocol (HTTP) und Internet Remote Function Calls (RFC) verwenden Parser.
Parser-Generator. Parser-Generatoren nehmen eine Grammatik als Eingabe und generieren Quellcode, also Parsing in umgekehrter Form. Sie konstruieren Parser aus regulären Ausdrücken, das heißt speziellen Zeichenketten, die zur Verwaltung und zum Abgleich von Mustern im Text verwendet werden.





