Natural Language Generation (NLG)
Natural Language Generation, NLG (zu Deutsch: die Generierung natürlicher Sprache) ist die Verwendung von Programmen der künstlichen Intelligenz (KI), um aus einem Datensatz schriftliche oder gesprochene Schilderungen zu erzeugen. NLG ist verwandt mit der Interaktion zwischen Mensch und Maschine und zwischen Maschine und Mensch, einschließlich Computerlinguistik, Natural Language Processing (NLP) und Natural Language Understanding (NLU).
Die Forschung zu NLG konzentriert sich häufig auf die Entwicklung von Computerprogrammen, die Datenpunkte mit Kontext versehen. Hochentwickelte NLG-Software kann große Mengen an numerischen Daten auswerten, Muster erkennen und diese Informationen in einer für Menschen leicht verständlichen Form weitergeben. Die Geschwindigkeit von NLG-Software ist besonders nützlich für die Produktion von Nachrichten und anderen zeitkritischen Beiträgen im Internet. Im besten Fall können NLG-Ergebnisse wortwörtlich als Webinhalte veröffentlicht werden.
Wie NLG funktioniert
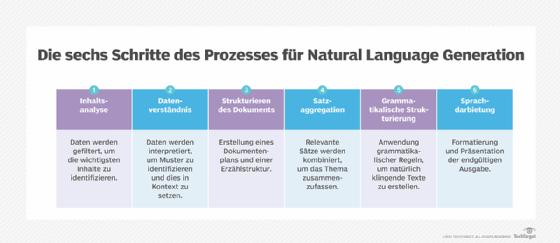
NLG ist ein mehrstufiger Prozess, bei dem die Daten in jeder Stufe weiter verfeinert werden, um Inhalte mit natürlich klingender Sprache zu produzieren. Die sechs Stufen von NLG sind wie folgt:
- Die Daten werden gefiltert, um zu bestimmen, was in den am Ende des Prozesses erstellten Inhalt aufgenommen werden soll. In dieser Phase werden die Hauptthemen des Quelldokuments und die Beziehungen zwischen ihnen identifiziert.
- Verstehen der Daten. Die Daten werden interpretiert, Muster werden identifiziert und sie werden in einen Kontext gestellt. In dieser Phase wird häufig maschinelles Lernen (ML) eingesetzt.
- Strukturierung des Dokuments. Es wird ein Dokumentplan erstellt und eine Erzählstruktur gewählt, die auf der Art der zu interpretierenden Daten basiert.
- Aggregation von Sätzen. Relevante Sätze oder Teile von Sätzen werden so kombiniert, dass sie das Thema genau zusammenfassen.
- Grammatikalische Strukturierung. Grammatikalische Regeln werden angewandt, um einen natürlich klingenden Text zu erzeugen. Das Programm leitet die syntaktische Struktur des Satzes ab. Es nutzt diese Informationen, um den Satz grammatikalisch korrekt umzuschreiben.
- Darstellung der Sprache. Die endgültige Ausgabe wird auf der Grundlage einer Vorlage oder eines Formats erzeugt, das der Benutzer oder Programmierer ausgewählt hat.
Wie wird NLG verwendet?
Natural Language Generation wird auf vielfältige Weise eingesetzt. Zu den zahlreichen Verwendungszwecken gehören unter anderem:
- Generierung der Antworten von Chatbots und Sprachassistenten wie Alexa von Google und Siri von Apple
- Umwandlung von Finanzberichten und anderen Arten von Geschäftsdaten in leicht verständliche Inhalte für Mitarbeiter und Kunden
- die Automatisierung von E-Mail-, Messaging- und Chat-Antworten zur Pflege von Kundenkontakten
- Personalisierung von Antworten auf Kunden-E-Mails und -Nachrichten
- Erstellung und Personalisierung von Skripten, die von Kundenbetreuern verwendet werden
- Aggregieren und Zusammenfassen von Nachrichtenberichten
- Berichterstattung über den Status von IoT-Geräten (Internet der Dinge)
- Erstellung von Produktbeschreibungen für E-Commerce-Webseiten und Kundennachrichten
NLG vs. NLU vs. NLP
NLP ist ein Oberbegriff, der sich auf die Verwendung von Computern zum Verstehen menschlicher Sprache in schriftlicher und mündlicher Form bezieht. NLP basiert auf einem Rahmen von Regeln und Komponenten und wandelt unstrukturierte Daten in ein strukturiertes Datenformat um. Alle drei Prozesse sind dafür konzipiert, die Interaktion zwischen Mensch und Computer zu ermöglichen.
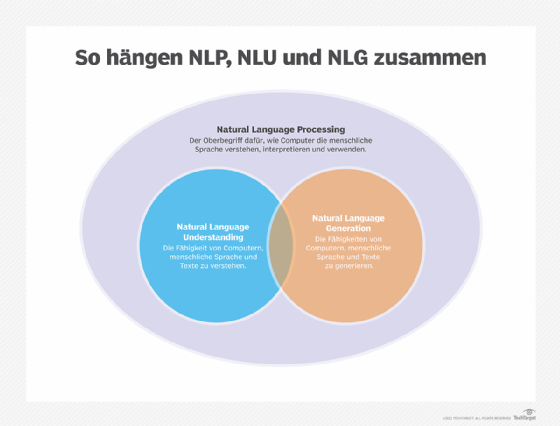
NLP umfasst sowohl NLG als auch NLU, die die folgenden unterschiedlichen, aber verwandten Fähigkeiten haben:
- NLU bezieht sich auf die Fähigkeit eines Computers, mithilfe syntaktischer und semantischer Analyse die Bedeutung von Text oder Sprache zu bestimmen. Kurz gesagt, geht es hier um das Verstehen natürlicher Sprache durch ein Computersystem.
- NLG ermöglicht es Computern, Text und Sprache aus Dateneingaben zu generieren.
Chatbots und „Textvorschläge“ in E-Mail-Clients wie Smart Compose von Google Mail sind Beispiele für Anwendungen, die sowohl NLU als auch NLG nutzen. Das Verstehen natürlicher Sprache ermöglicht es einem Computer, die Bedeutung der Benutzereingaben zu verstehen, und die Generierung natürlicher Sprache liefert die Text- oder Sprachantwort in einer für den Benutzer verständlichen Form.
NLG ist sowohl mit NLU als auch mit Information Retrieval verbunden. Es ist auch mit der Textzusammenfassung, der Spracherzeugung und der maschinellen Übersetzung verbunden. Ein Großteil der Grundlagenforschung im Bereich NLG überschneidet sich auch mit der Computerlinguistik und den Bereichen, die sich mit der Interaktion zwischen Mensch und Maschine und zwischen Maschine und Mensch befassen.
NLG-Modelle und -Methoden
NLG stützt sich auf Algorithmen des maschinellen Lernens und andere Ansätze, um als Reaktion auf Benutzereingaben maschinengenerierten Text zu erstellen. Zu den verwendeten Methoden gehören unter anderem die folgenden:
- Markov-Kette. Das Markov-Modell ist eine mathematische Methode, die in der Statistik und beim maschinellen Lernen verwendet wird, um Systeme zu modellieren und zu analysieren, die in der Lage sind, zufällige Entscheidungen zu treffen, wie zum Beispiel die Sprachgenerierung. Markov-Ketten beginnen mit einem Anfangszustand und erzeugen dann zufällig nachfolgende Zustände auf der Grundlage des vorherigen Zustands. Das Modell lernt über den aktuellen Zustand und den vorherigen Zustand und berechnet dann die Wahrscheinlichkeit des Wechsels in den nächsten Zustand auf der Grundlage der beiden vorherigen Zustände. In einem Kontext des maschinellen Lernens erstellt der Algorithmus Phrasen und Sätze, indem er Wörter auswählt, die statistisch gesehen wahrscheinlich zusammen auftreten.
- Rekurrentes neuronales Netz (RNN). Diese KI-Systeme werden eingesetzt, um sequentielle Daten auf unterschiedliche Weise zu verarbeiten. RNNs können verwendet werden, um Informationen von einem System auf ein anderes zu übertragen, beispielsweise bei der Übersetzung von Sätzen in einer bestimmten Sprache in eine andere. RNNs werden auch eingesetzt, um Muster in Daten zu erkennen, die bei der Identifizierung von Bildern helfen können. Ein RNN kann darauf trainiert werden, verschiedene Objekte in einem Bild zu erkennen oder die verschiedenen Teile der Sprache in einem Satz zu identifizieren.
- Langes Kurzzeitgedächtnis (Long Short-Term Memory, LSTM). Diese Art von RNN wird beim Deep Learningeingesetzt, wenn ein System aus Erfahrungen lernen muss. LSTM-Netze werden häufig für NLP-Aufgaben verwendet, da sie den Kontext lernen können, der für die Verarbeitung von Datenfolgen erforderlich ist. Um langfristige Abhängigkeiten zu lernen, verwenden LSTM-Netzwerke einen Gating-Mechanismus, um die Anzahl der vorherigen Schritte zu begrenzen, die den aktuellen Schritt beeinflussen können.
- Diese neuronale Netzwerkarchitektur ist in der Lage, langfristige Abhängigkeiten in der Sprache zu lernen und Sätze aus den Bedeutungen von Wörtern zu bilden. Transformer ist mit der KI verwandt. Es wurde von OpenAI, einem gemeinnützigen KI-Forschungsunternehmen in San Francisco, entwickelt. Transformer umfasst zwei Kodierer: einen für die Verarbeitung von Eingaben beliebiger Länge und einen weiteren für die Ausgabe der generierten Sätze.
Zu den drei Hauptmodellen von Transformer gehören:
- Generative Pre-trained Transformer (GPT) ist eine Art von NLG-Technologie, die mit Business-Intelligence-(BI)-Software verwendet wird. Wenn GPT in ein BI-System implementiert wird, verwendet es NLG-Technologie oder Algorithmen für maschinelles Lernen, um Berichte, Präsentationen und andere Inhalte zu erstellen. Das System generiert Inhalte auf der Grundlage der ihm zugeführten Informationen, die aus einer Kombination von Daten, Metadaten und Verfahrensregeln bestehen können.
- Bidirectional Encoder Representations from Transformers (BERT) ist der Nachfolger des Transformer-Systems, das Google ursprünglich für seinen Spracherkennungsdienst entwickelt hat. BERT ist ein Sprachmodell, das die menschliche Sprache lernt, indem es die syntaktischen Informationen, also die Beziehungen zwischen den Wörtern, und die semantischen Informationen, also die Bedeutung der Wörter, lernt.
- XLNet ist ein künstliches neuronales Netz, das mit einer Reihe von Daten trainiert wird. Es erkennt Muster, aus denen es eine logische Schlussfolgerung ziehen kann. Eine NLP-Maschine kann Informationen aus einer einfachen natürlich-sprachlichen Abfrage extrahieren. XLNet soll sich selbst beibringen, Texte zu lesen und zu interpretieren und dieses Wissen zu nutzen, um neue Texte zu schreiben. XLNet besteht aus zwei Teilen: einem Encoder und einem Decoder. Der Encoder verwendet die syntaktischen Regeln der Sprache, um Sätze in eine vektorbasierte Darstellung umzuwandeln; der Decoder verwendet diese Regeln, um die vektorbasierte Darstellung wieder in einen sinnvollen Satz zu verwandeln.






