Hadoop Distributed File System (HDFS)

Das Hadoop Distributed File System (HDFS) ist das primäre Datenspeichersystem, das von Hadoop-Anwendungen verwendet wird. HDFS nutzt eine NameNode- und DataNode-Architektur, um ein verteiltes Dateisystem zu implementieren, das einen hochleistungsfähigen Zugriff auf Daten in hochskalierbaren Hadoop-Clustern ermöglicht.
Hadoop selbst ist ein Open-Source-Framework für verteilte Verarbeitung, das die Datenverarbeitung und -speicherung für Big-Data-Anwendungen verwaltet. HDFS ist ein wichtiger Bestandteil der zahlreichen Technologien des Hadoop-Ökosystems. Es bietet ein zuverlässiges Mittel zur Verwaltung von Big-Data-Pools und unterstützt damit verbundene Big-Data-Analyseanwendungen.
Wie funktioniert HDFS?
HDFS ermöglicht die schnelle Übertragung von Daten zwischen Rechenknoten. Zu Beginn war es eng mit MapReduce gekoppelt, einem Framework für die Datenverarbeitung, das die Arbeit filtert und auf die Knoten in einem Cluster aufteilt und die Ergebnisse zu einer zusammenhängenden Antwort auf eine Abfrage organisiert und verdichtet. In ähnlicher Weise zerlegt HDFS bei der Aufnahme von Daten die Informationen in einzelne Blöcke und verteilt sie auf verschiedene Knoten in einem Cluster.
Mit HDFS werden die Daten einmal auf den Server geschrieben und danach mehrfach gelesen und wiederverwendet. HDFS hat eine primäre NameNode, die den Überblick darüber behält, wo die Dateidaten im Cluster gespeichert sind.
HDFS verfügt außerdem über mehrere DataNodes auf einem Standard-Hardware-Cluster - in der Regel einen pro Knoten in einem Cluster. Die DataNodes sind in der Regel innerhalb desselben Racks im Rechenzentrum organisiert. Die Daten werden in einzelne Blöcke aufgeteilt und zur Speicherung auf die verschiedenen DataNodes verteilt. Die Blöcke werden auch über die Knoten hinweg repliziert, was eine hocheffiziente parallele Verarbeitung ermöglicht.
Die NameNode weiß, welche DataNode welche Blöcke enthält und wo sich die DataNodes innerhalb des Maschinen-Clusters befinden. Die NameNode verwaltet auch den Zugriff auf die Dateien, einschließlich Lese-, Schreib-, Erstellungs- und Löschvorgänge sowie die Replikation von Datenblöcken über die DataNodes hinweg.
Die NameNode arbeitet in Verbindung mit den DataNodes. Dadurch kann sich der Cluster dynamisch und in Echtzeit an die Nachfrage nach Serverkapazitäten anpassen, indem bei Bedarf Knoten hinzugefügt oder entfernt werden.
Die DataNodes stehen in ständiger Kommunikation mit der NameNode, um festzustellen, ob die DataNodes bestimmte Aufgaben erledigen müssen. Folglich ist die NameNode immer über den Status der einzelnen DataNodes informiert. Wenn der NameNode feststellt, dass eine DataNode nicht ordnungsgemäß funktioniert, kann sie die Aufgabe dieser DataNodes sofort einem anderen Knoten zuweisen, der denselben Datenblock enthält. Die DataNodes kommunizieren auch untereinander, so dass sie bei normalen Dateioperationen zusammenarbeiten können.
Darüber hinaus ist das HDFS auf hohe Fehlertoleranz ausgelegt. Das Dateisystem repliziert - oder kopiert - jeden Datenblock mehrfach und verteilt die Kopien auf einzelne Knoten, wobei mindestens eine Kopie auf einem anderen Server-Rack als die anderen Kopien platziert wird.
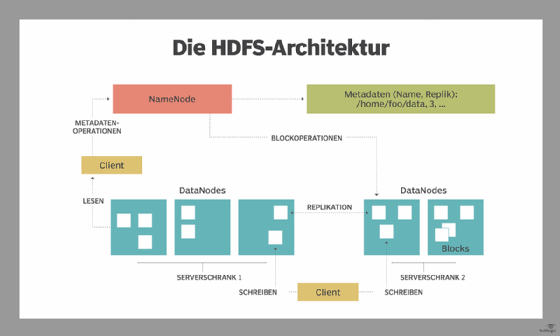
HDFS-Architektur, NameNodes und DataNodes
HDFS verwendet eine primäre/sekundäre Architektur. Die NameNode des HDFS-Clusters ist der primäre Server, der den Namespace des Dateisystems verwaltet und den Client-Zugriff auf Dateien kontrolliert. Als zentrale Komponente des verteilten Dateisystems von Hadoop pflegt und verwaltet die NameNode den Namensraum des Dateisystems und stattet die Clients mit den richtigen Zugriffsberechtigungen aus. Die DataNodes des Systems verwalten den Speicher, der mit den Knoten verbunden ist, auf denen sie laufen.
HDFS stellt einen Dateisystem-Namensraum zur Verfügung und ermöglicht die Speicherung von Benutzerdaten in Dateien. Eine Datei wird in einen oder mehrere Blöcke aufgeteilt, die in einer Reihe von DataNodes gespeichert werden. Die NameNode führt Dateisystem-Namensraumoperationen durch, einschließlich Öffnen, Schließen und Umbenennen von Dateien und Verzeichnissen. Die NameNode regelt auch die Zuordnung von Blöcken zu den DataNodes. Die DataNodes bedienen Lese- und Schreibanfragen von den Clients des Dateisystems. Darüber hinaus führen sie die Erstellung, Löschung und Replikation von Blöcken durch, wenn die NameNode sie dazu anweist.
HDFS unterstützt eine traditionelle hierarchische Dateiorganisation. Eine Anwendung oder ein Benutzer kann Verzeichnisse erstellen und dann Dateien innerhalb dieser Verzeichnisse speichern. Die Namespace-Hierarchie des Dateisystems ist wie bei den meisten anderen Dateisystemen - ein Benutzer kann Dateien erstellen, entfernen, umbenennen oder von einem Verzeichnis in ein anderes verschieben.
Die NameNode zeichnet jede Änderung des Dateisystem-Namensraumes oder seiner Eigenschaften auf. Eine Anwendung kann die Anzahl der Replikate einer Datei festlegen, die das HDFS verwalten soll. Der NameNode speichert die Anzahl der Kopien einer Datei, den sogenannten Replikationsfaktor dieser Datei.
Eigenschaften von HDFS
Es gibt mehrere Funktionen, die HDFS besonders nützlich machen, darunter:
- Damit wird sichergestellt, dass die Daten immer verfügbar sind und ein Datenverlust verhindert wird. Wenn zu Beispiel ein Knoten abstürzt oder ein Hardwarefehler auftritt, können replizierte Daten von einer anderen Stelle innerhalb eines Clusters abgerufen werden, so dass die Verarbeitung fortgesetzt wird, während die Daten wiederhergestellt werden.
- Fehlertoleranz und Zuverlässigkeit. Die Fähigkeit von HDFS, Dateiblöcke zu replizieren und sie über Knoten in einem großen Cluster hinweg zu speichern, gewährleistet Fehlertoleranz und Zuverlässigkeit.
- Hochverfügbarkeit. Wie bereits erwähnt, sind die Daten dank der Replikation zwischen den Knoten auch dann verfügbar, wenn die NameNode oder ein DataNode ausfällt.
- Da HDFS Daten auf verschiedenen Knoten im Cluster speichert, kann ein Cluster bei steigenden Anforderungen auf Hunderte von Knoten skaliert werden.
- Hoher Durchsatz. Da HDFS Daten in einer verteilten Weise speichert, können die Daten parallel auf einem Cluster von Knoten verarbeitet werden. Dies und die Datenlokalität (siehe nächster Punkt) verkürzen die Verarbeitungszeit und ermöglichen einen hohen Durchsatz.
- Datenlokalität. Mit HDFS finden die Berechnungen auf den Datenknoten statt, auf denen sich die Daten befinden, anstatt die Daten dorthin zu verschieben, wo sich die Recheneinheit befindet. Durch die Minimierung der Entfernung zwischen den Daten und dem Rechenprozess verringert dieser Ansatz die Netzwerküberlastung und steigert den Gesamtdurchsatz eines Systems.
Was sind die Vorteile von HDFS?
Die Verwendung von HDFS bietet fünf Hauptvorteile, darunter:
Kosteneffizienz. Die DataNodes, auf denen die Daten gespeichert werden, basieren auf preiswerter Standardhardware, was die Speicherkosten senkt. Da HDFS Open Source ist, fallen auch keine Lizenzgebühren an.
Speicherung großer Datenmengen. HDFS speichert eine Vielzahl von Daten jeder Größe - von Megabyte bis Petabyte - und in jedem Format, einschließlich strukturierter und unstrukturierter Daten.
Schnelle Wiederherstellung nach Hardwareausfällen. HDFS ist so konzipiert, dass es Fehler erkennt und sich automatisch selbst wiederherstellt.
Portabilität. HDFS ist über alle Hardwareplattformen hinweg portabel und mit verschiedenen Betriebssystemenkompatibel, darunter Windows, Linux und Mac OS/X.
Streaming-Datenzugriff. HDFS ist auf einen hohen Datendurchsatz ausgelegt, was für den Zugriff auf Streaming-Daten optimal ist.
HDFS-Anwendungsfälle und Beispiele
Das Hadoop Distributed File System entstand bei Yahoo als Teil der Anforderungen des Unternehmens an die Online-Anzeigenschaltung und die Suchmaschine. Wie andere webbasierte Unternehmen jonglierte Yahoo mit einer Vielzahl von Anwendungen, auf die eine wachsende Zahl von Nutzern zugriff, die immer mehr Daten erzeugten.
Ebay, Facebook, LinkedIn und Twitter gehören zu den Unternehmen, die HDFS zur Unterstützung von Big-Data-Analysen einsetzen, um ähnliche Anforderungen wie Yahoo zu erfüllen.
HDFS wird nicht nur zur Erfüllung der Anforderungen von Adserving und Suchmaschinen eingesetzt. Die New York Times nutzte es für groß angelegte Bildkonvertierungen, Media6Degrees für die Protokollverarbeitung und maschinelles Lernen, LiveBet für die Protokollspeicherung und Quotenanalyse, Joost für die Sitzungsanalyse und Fox Audience Network für die Protokollanalyse und das Data Mining. HDFS ist auch das Herzstück vieler Open Source Data Lakes.
Ganz allgemein nutzen Unternehmen in verschiedenen Branchen HDFS, um große Datenbestände zu verwalten, darunter:
- Elektrizitätswerke. Die Stromwirtschaft setzt überall in ihren Übertragungsnetzen Phasenmessgeräte (PMUs) ein, um den Zustand der intelligenten Netze zu überwachen. Diese Hochgeschwindigkeitssensoren messen Strom und Spannung nach Amplitude und Phase an ausgewählten Übertragungsstationen. Diese Unternehmen analysieren die PMU-Daten, um Systemfehler in Netzsegmenten zu erkennen und das Netz entsprechend anzupassen. So können sie beispielsweise auf eine Reservestromquelle umschalten oder eine Lastanpassung vornehmen. Da PMU-Netzwerke Tausende von Datensätzen pro Sekunde verarbeiten, können Energieversorgungsunternehmen von kostengünstigen, hochverfügbaren Dateisystemen wie HDFS profitieren.
- Gezielte Marketingkampagnen setzen voraus, dass Marketingteams viel über ihre Zielgruppen wissen. Diese Informationen können aus verschiedenen Quellen stammen, zum Beispiel aus CRM-Systemen, Direktmailing-Antworten, Kassensystemen, Facebook und Twitter. Da viele dieser Daten unstrukturiert sind, ist ein HDFS-Cluster der kosteneffizienteste Ort, um die Daten vor der Analyse zu speichern.
- Öl- und Gasanbieter. Öl- und Gasunternehmen arbeiten mit einer Vielzahl von Datenformaten mit sehr großen Datensätzen, darunter Videos, 3D-Erdmodelle und maschinelle Sensordaten. Ein HDFS-Cluster kann eine geeignete Plattform für die erforderlichen Big-Data-Analysen bieten.
- Auch hier bieten HDFS-Cluster eine kostengünstige Möglichkeit zur Speicherung, Verarbeitung und Analyse großer Datenmengen.
HDFS-Datenreplikation
Die Datenreplikation ist ein wichtiger Bestandteil des HDFS-Formats, da sie sicherstellt, dass die Daten auch bei einem Knoten- oder Hardwareausfall verfügbar bleiben. Wie bereits erwähnt, werden die Daten in Blöcke aufgeteilt und über zahlreiche Knoten im Cluster repliziert. Wenn also ein Knoten ausfällt, kann der Benutzer von anderen Rechnern aus auf die Daten zugreifen, die sich auf diesem Knoten befanden. HDFS führt den Replikationsprozess in regelmäßigen Abständen durch.





