Graphdatenbank

Was ist eine Graphdatenbank?
Eine Graphdatenbank, die auch als semantische Datenbank bezeichnet wird, ist eine Softwareanwendung zum Speichern, Abfragen und Ändern von Netzwerkgraphen. Ein Netzwerkdiagramm ist ein visuelles Konstrukt, das aus Knoten und Kanten besteht. Jeder Knoten steht für eine Einheit, zum Beispiel eine Person, und jede Kante für eine Verbindung oder Beziehung zwischen zwei Knoten.
Graphdatenbanken sind eine Art von Datenbankdesign, die es in einigen Variationen schon seit langem gibt. Ein Stammbaum ist zum Beispiel eine einfache Graphdatenbank.
Das Konzept der graphischen Datenbank wird oft dem Mathematiker Leonhard Euler aus dem 18. Jahrhundert zugeschrieben. Das Konzept, Datenbanken zur digitalen Abbildung von Beziehungen zu verwenden, wurde um 2015 in der Wirtschaft populär, als eine höhere Rechenleistung, speicherinterne Datenverarbeitung und vereinbarte Standards das Konzept von der akademischen Welt in die reale Welt der Geschäfts- und Unternehmensdatenverarbeitung brachten.
Graphdatenbanken speichern und repräsentieren Daten in Form von Knoten, Kanten und Eigenschaften. Während Knoten Entitäten und Kanten die Beziehungen zwischen Entitäten darstellen, sind Eigenschaften die mit Knoten und Kanten verbundenen Attribute, die zusätzlichen Kontext liefern. Knoten werden als Datensätze gespeichert, wobei Kanten und Eigenschaften als Zeiger zwischen Knoten dargestellt werden.
Graphdatenbanken eignen sich gut für die Analyse von Zusammenhängen, weshalb sie auch für die Auswertung von Daten aus sozialen Medien verwendet werden. Graphdatenbanken eignen sich auch für die Arbeit mit Daten in Geschäftsbereichen, in denen komplexe Beziehungen und dynamische Schemata eine Rolle spielen, zum Beispiel im Supply Chain Management (SCM), bei der Ermittlung der Ursache eines IP-Telefonie-Problems und bei der Erstellung von Empfehlungsmaschinen nach dem Motto „Kunden, die dies gekauft haben, sahen sich auch ...“.
Wie funktionieren Graphdatenbanken?
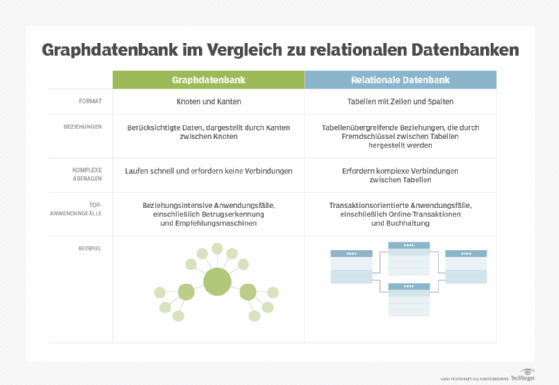
Graphdatenbanken sind nach einem Graphenmodell strukturiert und unterscheiden sich damit von herkömmlichen relationalen Datenbanken. Graphdatenbanken sind einzigartig in ihrer Struktur, der Art und Weise, wie sie Informationen verwalten und speichern und wie sie abgefragt werden.
Die Struktur einer Graphdatenbank
Graphdatenbanken arbeiten mit einem Graphmodell, das aus Knoten, Kanten und Eigenschaften besteht, die die Graphstruktur bilden. Knoten repräsentieren Entitäten wie Personen, Orte oder Dinge, und Kanten stellen Beziehungen zwischen Entitäten dar. Eigenschaften sind die Attribute – die als zusätzliche Metadaten gespeichert werden –, die mit Kanten und Knoten verbunden sind.
Graphendatenbanken, die traditionell als eine Art NoSQL-Datenbank klassifiziert werden, gibt es in verschiedenen Ausführungen, wie zum Beispiel als Triplestore-Datenbanken. Dieser Datenbanktyp verwendet einen speziellen Index, der Informationen über Knoten, Kanten und die Beziehungen zwischen ihnen in Dreiergruppen speichert.
Ein Tripel, das auch als Behauptung bezeichnet wird, hat drei Hauptfelder: ein Subjekt, ein Prädikat und ein Objekt. Jedes Subjekt, Prädikat oder Objekt wird durch einen eindeutigen Ressourcenbezeichner (Uniform Resource Identifier, URI) dargestellt.
Wie die Informationen indiziert werden
In einem Triplestore enthält das erste Feld in der Datenbank den URI für das Subjekt, das zweite Feld den URI für das Prädikat und das dritte Feld den URI für das Objekt. Es gibt zwar mehrere Strategien, die Graphdatenbanken für die Speicherung von Triples verwenden können, aber die meisten verwenden einen Index, der die drei Primärfelder zu ?s, ?p und ?o abkürzt.
Wenn das visuelle Konstrukt für einen Graphen zum Beispiel wie folgt aussieht:
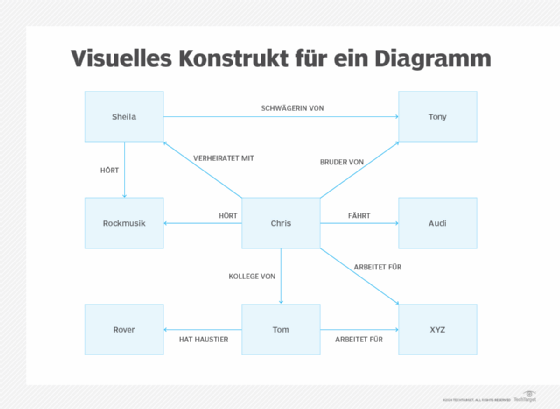
Dann sieht der Index wie folgt aus:
| Zeile | ?s | ?p | ?o |
| 1 | :Chris | :VERHEIRATETMIT | :Sheila |
| 2 | :Chris | :BRUDERVON | :Tony |
| 3 | :Chris | :HÖRT | :Rockmusik |
| 4 | :Sheila | :HÖRT | :Rockmusik |
| 5 | :Sheila | :SCHWÄGERINVON | :Tony |
| 6 | :Tom | :ARBEITFÜR | :XYZ |
| 7 | :Tom | :HATHAUSTIER | :Rover |
| 8 | :Chris | :FÄHRT | :Audi |
| 9 | :Chris | :KOLLEGEVON | :Tom |
| 10 | :Chris | :ARBEITETFÜR | :XYZ |
Knoten können auch in Clustern gespeichert werden. Beim Clustering in Graphdatenbanken werden Gruppen, auch Communities genannt, von Knoten identifiziert, die benachbarte Verbindungen in einem Graphen aufweisen. Diese Knotencluster stehen in enger Beziehung zueinander, verglichen mit Knoten, die nicht im Cluster enthalten sind.
Wie Informationen in einer Graphdatenbank abgefragt werden
Graphenalgorithmen werden verwendet, um die Beziehungen von miteinander verbundenen Graphdaten zu analysieren. Sie führen Aufgaben wie die Suche nach Mustern, kürzesten zusammenhängenden Pfaden und Abständen zwischen Knoten sowie die Wichtigkeit der Knoten und die Bildung von Clustern durch.
Graphabfragesprachen sind Programmiersprachen, die für die Interaktion mit Graphdatenbanken verwendet werden. Sie ermöglichen es den Benutzern, Graphdaten abzurufen, zu bearbeiten und zu analysieren. Graphenabfragesprachen verfügen über Funktionen, die es den Benutzern ermöglichen, Daten hinzuzufügen, zu bearbeiten und abzufragen, und können komplexe Abfragen effizient verarbeiten. Die im April 2024 veröffentlichte Norm ISO/IEC 39075:2024 beispielsweise beschreibt Datenstrukturen und grundlegende Operationen für Eigenschaftsgraphen.
Jedes Tripel in einer Graphdatenbank wird nur einmal im Index gespeichert. Genau wie bei relationalen Datenbanken ist es ein einfacher Prozess, eine direkte Abfrage in einer Graphdatenbank durchzuführen. Wenn die Abfrage darauf abzielt, welche Informationen über Chris bekannt sind, muss die Indexierungsprogrammierung nur die Zeilen 1-3 der Datenbank durchsuchen.
Die wahre Stärke und Geschwindigkeit einer Graphdatenbank ergibt sich aus der Indizierung von Tripelkombinationen. Nachfolgend ein paar Beispiele:
- Wenn die Abfrage lautet, mit wem Chris verheiratet ist, sucht der Indexer nach dem Prädikat :verheiratetMit in den Zeilen 1-3 und ruft dann das passende Objekt ab. Chris ist mit Sheila verheiratet.
- Wenn die Abfrage lautet, alle Personen zu identifizieren, die die gleiche Art von Musik hören wie Chris, wird der Indexer zuerst { :Chris :hört ?o } abfragen und :Rockmusik als Objekt identifizieren.
In der zweiten Abfrage werden die Ergebnisse :Rockmusik in den Zeilen 3 und 4 zurückgegeben. Das Subjekt in Zeile 3 ist Chris selbst, also ist derjenige, der das Subjekt in Zeile 4 ist, die andere Person, die Rockmusik hört. Es handelt sich um Sheila, die Frau von Chris.
Arten von Graphdatenbanken
Es gibt mehrere Arten von Graphdatenbanken, darunter:
- Wissensgraphen. Wissensgraphen wie der obige konzentrieren sich auf die semantischen Aspekte von Daten und speichern Informationen in Tripeln.
- Eigenschaftsgraphen. Eigenschaftsgraphen unterstützen Knoten, Kanten und modellieren Beziehungen zwischen Datenpunkten, mit detaillierten Informationen über den Gegenstand und die Art und Weise, wie diese Daten miteinander in Beziehung stehen.
- Resource Description Framework-Graphen. RDF-Graphen drücken Daten in Graphen mit Objekt-, Prädikat- und Subjektteilen aus. Sie werden zur Verwaltung der Verknüpfung von Ressourcen und Metadaten verwendet und entsprechen den Standards des World Wide Web Consortium.
- Triplestore. Triplestore-Graphdatenmodelle speichern Daten im Triple-Format, das aus einer Subjekt-Prädikat-Objekt-Datenstruktur besteht. Sie werden für die Speicherung und Abfrage von Daten, einschließlich semantischer Beziehungen, verwendet.
- Hypergraphdatenbanken. Hypergraphenmodelle ermöglichen Hyperedges, das heißt Beziehungen, die zwei oder mehr Knoten miteinander verbinden. Sie werden für Graphen verwendet, die komplexere Many-to-Many-Beziehungen aufweisen.
Anwendungsfälle für Graphdatenbanken
Zu den aktuellen Anwendungsfällen für Graphdatenbanken gehören:
- Datenanalysten können Datensätze zusammenführen, ohne komplexe Abfragen erstellen und ausführen zu müssen, die Kombinationen von Tabellen miteinander verbinden, wie es im relationalen Datenbankmodell der Fall ist.
- Unterstützung von Entwicklern bei der Erstellung des Backends für Sprachassistenten durch Zuordnung möglicher Benutzerfragen zu den richtigen Antworten.
- Untersuchung direkter Verbindungen, um potenzielle indirekte Verbindungen für Empfehlungsmaschinen zu identifizieren.
- Erkennung von Betrugsfällen durch die schnelle Analyse von Mustern und Verbindungen zwischen Entitäten wie zum Beispiel Benutzern, Konten oder Transaktionen. Anomales Verhalten wird durch die Erkennung ungewöhnlicher Muster im Graphen identifiziert.
- Modellierung von Beziehungen zwischen Interaktionen auf Social-Media-Plattformen, zum Beispiel zwischen Nutzern, Beiträgen, Kommentaren und Likes. Dies ermöglicht eine effizientere Abfrage und Analyse sozialer Verbindungen und eine bessere Personalisierung von Social-Media-Funktionen.
Die Zukunft von Graphdatenbanken
Graphdatenbank-Tools wie Amazon Neptune und Neo4j werden zunehmend verfügbar. Darüber hinaus bieten sie Vorteile wie flexiblere Datenmodellierung, effiziente Abfragen, Echtzeiteinblicke und vereinfachte Datenintegration. So wird es für Entwickler immer einfacher, Graphanalysen zu bestehenden Anwendungen hinzuzufügen und gleichzeitig die Datenintegrität, Skalierbarkeit und Konsistenz zu wahren.
Es wird erwartet, dass Graphdatenbanken in Bereichen wie maschinellem Lernen, Bayes'scher Analyse, Data Science und künstlicher Intelligenz (KI) sowie bei der Verwaltung von Unternehmensdaten und dem Datenaustausch im nächsten Jahrzehnt eine größere Rolle spielen werden.
Eine weitere potenzielle Auswirkung auf diesen Datenbanktyp sind Verbesserungen bei der Datenföderation. Wenn Wissensgraphen problemlos zusammengeführt werden können, kann eine Datenbank feststellen, dass sie Daten benötigt, die sie nicht hat, und diese Daten automatisch aus anderen Wissensgraphen abrufen. Mit dieser Fähigkeit ist es möglich, dass die Föderation Entwicklern helfen kann, Blockchains zu erstellen, die relevante Metadaten zur Authentifizierung von Transaktionen im Bank- und Finanzwesen, bei Abstimmungen und Smart Contracts verwenden.






