Fog Computing
Fog Computing ist eine dezentrale Datenverarbeitungsinfrastruktur, bei der sich Daten, Rechenleistung, Speicher und Anwendungen irgendwo zwischen der Datenquelle und der Cloud befinden. Wie Edge Computing bringt auch Fog Computing die Vorteile und die Leistung der Cloud näher an den Ort, an dem die Daten erstellt und verarbeitet werden. Viele Menschen verwenden die Begriffe Fog Computing und Edge Computing synonym, da es bei beiden darum geht, Intelligenz und Verarbeitung näher an den Ort der Datenerstellung zu bringen. Dies geschieht häufig, um die Effizienz zu steigern, kann aber auch aus Gründen der Sicherheit und der Einhaltung von Vorschriften geschehen.
Die Metapher des Nebels (Fog: im deutschen Nebel) stammt von dem meteorologischen Begriff für eine Wolke in Bodennähe, so wie sich der Nebel am Rande des Netzwerks konzentriert. Der Begriff wird oft mit Cisco in Verbindung gebracht; es wird angenommen, dass Ginny Nichols, die Produktlinienmanagerin des Unternehmens, den Begriff geprägt hat. Cisco Fog Computing ist ein eingetragener Name; Fog Computing ist für die gesamte Community offen.
Wie funktioniert Fog Computing?
Fog Networking ergänzt - nicht ersetzt - Cloud Computing; Fogging ermöglicht kurzfristige Analysen am Edge, während die Cloud ressourcenintensive, längerfristige Analysen durchführt. Obwohl Edge-Geräte und Sensoren die Orte sind, an denen Daten generiert und gesammelt werden, verfügen sie manchmal nicht über die Rechen- und Speicherressourcen, um erweiterte Analysen und maschinelle Lernaufgaben durchzuführen. Cloud-Server sind zwar leistungsfähig, aber oft zu weit entfernt, um die Daten zu verarbeiten und zeitnah zu reagieren.
Darüber hinaus kann die Tatsache, dass alle Endpunkte eine Verbindung zur Cloud herstellen und Rohdaten über das Internet an diese senden, Auswirkungen auf den Datenschutz, die Sicherheit und die Rechtslage haben, insbesondere wenn es sich um sensible Daten handelt, die in verschiedenen Ländern Vorschriften unterliegen. Zu den beliebten Fog-Computing-Anwendungen gehören intelligente Netze (Smart Grid), intelligente Städte (Smart Cities), intelligente Gebäude (Smart Building), Fahrzeugnetze und softwaredefinierte Netze.
Fog Computing vs. Edge Computing
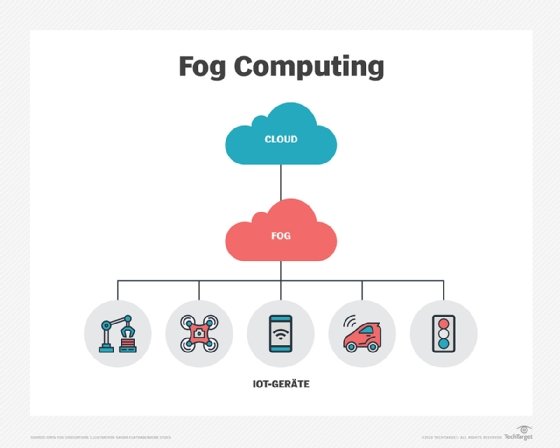
Laut dem von Cisco gegründeten OpenFog-Konsortium besteht der Hauptunterschied zwischen Edge- und Fog-Computing darin, wo die Intelligenz und die Rechenleistung platziert werden. In einer reinen Fog-Umgebung befindet sich die Intelligenz im lokalen Netzwerk (LAN), und die Daten werden von den Endpunkten an ein Fog-Gateway übertragen, wo sie dann an die Quellen zur Verarbeitung und Rückübertragung weitergeleitet werden.
Beim Edge Computing können sich Intelligenz und Leistung entweder im Endpunkt oder in einem Gateway befinden. Befürworter des Edge Computing loben die Verringerung von Fehlerquellen, da jedes Gerät unabhängig arbeitet und entscheidet, welche Daten lokal gespeichert und welche Daten zur weiteren Analyse an ein Gateway oder die Cloud gesendet werden sollen. Befürworter von Fog Computing gegenüber Edge Computing sagen, dass es besser skalierbar ist und einen besseren Überblick über das Netzwerk bietet, da mehrere Datenpunkte Daten einspeisen.
Es sei jedoch darauf hingewiesen, dass einige Netzwerktechniker Fog Computing lediglich als eine Cisco-Marke für einen Ansatz des Edge Computing betrachten.
Wie und warum wird Fog Computing eingesetzt?
Es gibt eine Vielzahl von potenziellen Anwendungsfällen für Fog Computing. Ein zunehmend häufiger Anwendungsfall für Fog Computing ist die Verkehrsüberwachung. Da Sensoren – zum Beispiel zur Verkehrsüberwachung – häufig mit Mobilfunknetzen verbunden sind, stellen Städte manchmal Rechenressourcen in der Nähe der Mobilfunkmasten bereit. Diese Rechenkapazitäten ermöglichen die Echtzeitanalyse von Verkehrsdaten, so dass Verkehrssignale in Echtzeit auf veränderte Bedingungen reagieren können.
Dieses Grundkonzept wird nun auch auf autonome Fahrzeuge ausgedehnt. Autonome Fahrzeuge fungieren aufgrund ihrer enormen Rechenleistung an Bord im Wesentlichen als Edge-Geräte. Diese Fahrzeuge müssen in der Lage sein, Daten von einer großen Anzahl von Sensoren zu erfassen, Datenanalysen in Echtzeit durchzuführen und dann entsprechend zu reagieren.
Da ein autonomes Fahrzeug so konzipiert ist, dass es ohne Cloud-Konnektivität funktioniert, ist es verlockend, autonome Fahrzeuge als nicht verbundene Geräte zu betrachten. Auch wenn ein autonomes Fahrzeug in der Lage sein muss, auch ohne Cloud-Konnektivität sicher zu fahren, ist es dennoch möglich, Konnektivität zu nutzen, wenn sie verfügbar ist. Einige Städte überlegen, wie ein autonomes Fahrzeug mit denselben Rechenressourcen betrieben werden könnte, die auch für die Steuerung von Ampeln verwendet werden. Ein solches Fahrzeug könnte beispielsweise als Edge-Gerät fungieren und seine eigenen Rechenkapazitäten nutzen, um Echtzeitdaten an das System weiterzuleiten, das Verkehrsdaten aus anderen Quellen aufnimmt. Die zugrundeliegende Computerplattform kann diese Daten dann nutzen, um Ampeln effektiver zu steuern.
Was sind die Vorteile von Fog Computing?
Wie jede andere Technologie hat auch Fog Computing seine Vor- und Nachteile. Zu den Vorteilen des Fog Computing gehören unter anderem folgende:
- Fog Computing reduziert das Datenvolumen, das an die Cloud gesendet wird, und verringert so den Bandbreitenverbrauch und die damit verbundenen Kosten.
- Verbesserte Reaktionszeit. Da die anfängliche Datenverarbeitung in der Nähe der Daten stattfindet, wird die Latenzzeit verringert und die Reaktionszeit insgesamt verbessert. Ziel ist es, eine Reaktionszeit im Millisekundenbereich zu erreichen, so dass die Daten nahezu in Echtzeit verarbeitet werden können.
- Netzwerkunabhängig. Obwohl beim Fog Computing die Rechenressourcen im Allgemeinen auf der LAN-Ebene platziert werden - im Gegensatz zur Geräteebene, wie es beim Edge Computing der Fall ist - könnte das Netzwerk als Teil der Fog Computing-Architektur betrachtet werden. Gleichzeitig ist Fog Computing jedoch netzwerkunabhängig, das heißt das Netzwerk kann kabelgebunden, Wi-Fi oder sogar 5G sein.
Was sind die Nachteile des Fog Computing?
Natürlich hat Fog Computing auch seine Nachteile, von denen einige die folgenden sind:
- Physischer Standort. Da Fog Computing an einen physischen Standort gebunden ist, untergräbt es einige der Vorteile des Cloud Computing, die mit „jederzeit und überall“ verbunden sind.
- Potenzielle Sicherheitsprobleme. Unter den richtigen Umständen kann Fog Computing Sicherheitsproblemen unterliegen, zum Beispiel dem Spoofing von IP-Adressen oder Man-in-the-Middle-Angriffen (MitM).
- Fog Computing ist eine Lösung, die sowohl Edge- als auch Cloud-Ressourcen nutzt, was bedeutet, dass entsprechende Hardwarekosten anfallen.
- Zweideutiges Konzept. Obwohl es Fog Computing schon seit einigen Jahren gibt, ist die Definition von Fog Computing immer noch unklar, da verschiedene Anbieter Fog Computing unterschiedlich definieren.
| Vorteile |
Nachteile |
| Reduziert die Menge der an die Cloud gesendeten Daten |
Der Vorteil der Cloud, dass Daten jederzeit und überall verfügbar sind, wird durch den physischen Standort beeinträchtigt. |
| Schont die Netzwerkbandbreite |
Sicherheitsprobleme durch Spoofing von IP-Adressen oder Man-in-the-Middle-Attacken |
| Verbessert die Reaktionszeit |
Datenschutzprobleme |
| Verbessert die Sicherheit, da die Daten näher am Edge bleiben |
Verfügbarkeit/Ausstattungskosten für Fog Computing/Hardware |
| Unterstützt Mobilität |
Bedenken hinsichtlich des Vertrauens und der Authentifizierung |
| Minimiert Netzwerk- und Internetlatenz |
Sicherheitsbedenken bei drahtlosen (Wireless) Netzen |
Fog Computing und das Internet der Dinge
Da Cloud Computing für viele Anwendungen des Internets der Dinge (IoT) nicht praktikabel ist, wird häufig Fog Computing eingesetzt. Sein verteilter Ansatz ist auf die Anforderungen des IoT und des industriellen IoT (IIoT) sowie auf die immensen Datenmengen ausgerichtet, die von intelligenten Sensoren und IoT-Geräten generiert werden und deren Verarbeitung und Analyse in der Cloud kostspielig und zeitaufwändig wäre. Fog Computing verringert die benötigte Bandbreite und reduziert die Hin- und Her-Kommunikation zwischen Sensoren und der Cloud, die sich negativ auf die IoT-Leistung auswirken kann.
Fog Computing und 5G
Fog Computing ist eine Computerarchitektur, bei der eine Reihe von Knotenpunkten Daten von IoT-Geräten in Echtzeit empfängt. Diese Knoten verarbeiten die empfangenen Daten in Echtzeit mit einer Reaktionszeit von Millisekunden. Die Knoten senden in regelmäßigen Abständen analytische Übersichtsinformationen an die Cloud. Eine Cloud-basierte Anwendung analysiert dann die von den verschiedenen Knotenpunkten empfangenen Daten mit dem Ziel, verwertbare Erkenntnisse zu liefern.
Diese Architektur erfordert mehr als nur Rechenleistung. Sie erfordert eine Hochgeschwindigkeitsverbindung zwischen IoT-Geräten und -Knotenpunkten. Denken Sie daran, dass das Ziel darin besteht, Daten innerhalb weniger Millisekunden zu verarbeiten. Natürlich variieren die Konnektivitätsoptionen je nach Anwendungsfall. Ein IoT-Sensor in einer Fabrikhalle zum Beispiel kann wahrscheinlich eine Kabelverbindung nutzen. Eine mobile Ressource, wie zum Beispiel ein autonomes Fahrzeug, oder eine isolierte Ressource, wie eine Windturbine in der Mitte eines Feldes, benötigt jedoch eine andere Form der Konnektivität. 5G ist eine besonders überzeugende Option, da es die Hochgeschwindigkeitsverbindung bietet, die für die Analyse von Daten in nahezu Echtzeit erforderlich ist.
Was ist die Geschichte des Fog Computing?
Im Jahr 2015 schloss sich Cisco mit Microsoft, Dell, Intel, Arm und der Princeton University zusammen, um das OpenFog Consortium zu gründen. Andere Unternehmen, darunter General Electric (GE), Foxconn und Hitachi, trugen ebenfalls zu diesem Konsortium bei. Die Hauptziele des Konsortiums waren die Förderung und Standardisierung von Fog Computing. Das Konsortium fusionierte 2019 mit dem Industrial Internet Consortium (IIC).







