Feature Engineering

Was ist Feature Engineering?
Beim Feature Engineering werden Rohdaten in Feature (Merkmale) umgewandelt, die zur Erstellung eines Vorhersagemodells mit Unterstützung des maschinellen Lernens oder statistischer Modellierung, zum Beispiel Deep Learning, verwendet werden können. Ziel des Feature Engineering ist es, einen Eingabedatensatz vorzubereiten, der am besten zum Algorithmus für maschinelles Lernen passt, und die Leistung von Modellen für maschinelles Lernen zu verbessern.
Feature Engineering kann Datenwissenschaftler unterstützen, indem es die Zeit beschleunigt, die für die Extraktion von Variablen aus Daten benötigt wird, und so die Extraktion von mehr Variablen ermöglicht. Die Automatisierung des Feature Engineering unterstützt Unternehmen und Datenwissenschaftler, Modelle mit höherer Genauigkeit zu erstellen.
Wie Feature Engineering funktioniert
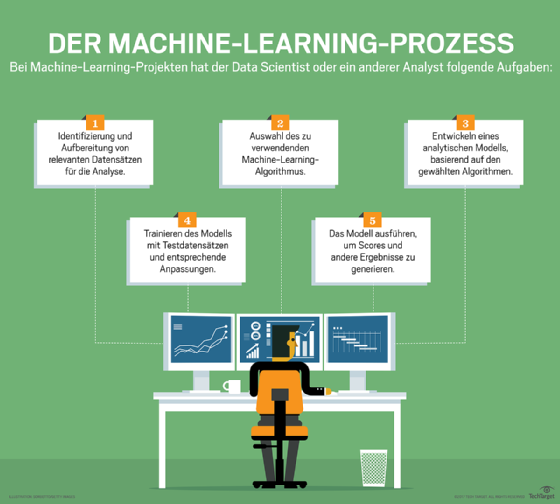
Der Feature-Engineering-Prozess umfasst:
- Feature entwickeln: Untersuchen Sie eine große Menge an Daten, analysieren Sie das Feature Engineering bei anderen Problemen und finden Sie heraus, was Sie davon verwenden können.
- Feature definieren: Dies umfasst zwei Prozesse: Die Feature-Extraktion beinhaltet, einen Satz von Features zu definieren und zu extrahieren, die Daten repräsentieren, welche für die Analyse wichtig sind. Die Feature-Konstruktion beinhaltet die Umwandlung eines bestimmten Satzes von Eingangsmerkmalen in einen neuen Satz effektiverer Features, die für die Vorhersage verwendet werden können. Je nach Problemstellung kann der Benutzer entscheiden, ob er die automatische Feature-Extraktion, die manuelle Feature-Konstruktion oder eine Kombination aus beidem verwenden möchte.
- Feature auswählen: Wenn die Benutzer etwas über die Daten wissen und die potenziellen Merkmale definiert haben, besteht der nächste Schritt darin, die richtigen Merkmale auszuwählen. Dies besteht aus zwei Elementen: der Feature-Auswahl, das heißt der Auswahl einer Teilmenge der für eine bestimmte Aufgabe relevantesten Features, und der Feature-Bewertung, das heißt der Beurteilung, wie nützlich ein Feature für die Vorhersage ist.
- Feature evaluieren: Evaluierung von Merkmalen durch die Bewertung der Genauigkeit des Modells bei ungesehenen Daten unter Verwendung der ausgewählten Merkmale.
Feature-Engineering-Techniken
Zu den Techniken des Feature Engineering gehören:
- Imputation: ein typisches Problem beim maschinellen Lernen sind fehlende Werte in den Datensätzen, was sich auf die Art und Weise auswirkt, wie Machine-Learning-Algorithmen eingesetzt werden. Imputation ist der Prozess des Ersetzens fehlender Daten durch statistische Schätzungen der fehlenden Werte, wodurch ein vollständiger Datensatz entsteht, der zum Trainieren von Modellen des maschinellen Lernens verwendet wird.
- One-Hot-Codierung: ein Prozess, bei dem kategoriale Daten in eine Form umgewandelt werden, die der Algorithmus für maschinelles Lernen versteht, damit er bessere Vorhersagen machen kann.
- Bag of words: ein Zählalgorithmus, der berechnet, wie oft ein Wort in einem Dokument wiederholt wird. Er kann verwendet werden, um Ähnlichkeiten und Unterschiede in Dokumenten für Anwendungen wie die Suche und die Klassifizierung von Dokumenten zu bestimmen.
- Automatisiertes Feature Engineering: mit dieser Technik werden nützliche und aussagekräftige Merkmale herausgezogen, wobei ein Framework verwendet wird, das auf jedes Problem angewendet werden kann. Automatisiertes Feature Engineering ermöglicht es Datenwissenschaftlern, produktiver zu sein, da sie mehr Zeit für andere Komponenten des maschinellen Lernens aufwenden können. Diese Technik ermöglicht es auch Citizen Data Scientists, also Laien in der Datenwissenschaft, Feature Engineering mit einem Framework- Ansatz auszuführen.
- Binning: Binning oder das Gruppieren von Daten ist der Schlüssel zur Vorbereitung numerischer Daten für maschinelles Lernen. Diese Technik kann verwendet werden, um eine Zahlenspalte durch kategorische Werte zu ersetzen, die bestimmte Bereiche repräsentieren.
- N-Gramme: unterstützen bei der Vorhersage des nächsten Elements in einer Sequenz. In der Stimmungsanalyse hilft das N-Gramm-Modell bei der Analyse der Stimmung eines Textes oder Dokuments.
- Feature-Kreuzungen: eine Möglichkeit, zwei oder mehr kategoriale Merkmale zu einem einzigen zu kombinieren. Diese Technik ist besonders nützlich, wenn bestimmte Feature zusammen eine Eigenschaft besser beschreiben als sie es alleine tun.
Es gibt einige Open-Source-Python-Bibliotheken, die Feature-Engineering-Techniken unterstützen, darunter die Featuretools Library zur automatischen Erstellung von Features aus einem Satz zusammengehöriger Tabellen unter Verwendung von Deep Feature Synthesis, einem Algorithmus, der automatisch Merkmale für relationale Datensätze erzeugt.
Anwendungsfälle des Feature Engineering
Nachfolgend finden Sie Beispiele für Feature Engineering-Anwendungsfälle:
- Berechnung des Alters einer Person aus ihrem Geburtsdatum und dem aktuellen Datum
- Ermittlung der durchschnittlichen und medianen Retweet-Anzahl bestimmter Tweets
- Erfassen von Wort- und Phrasenzahlen aus Nachrichtenartikeln
- Extrahieren von Pixelinformationen aus Bildern
- Tabellarische Erfassung der Häufigkeit, mit der Lehrer verschiedene Noten eingeben
Feature Engineering für maschinelles Lernen
Beim Feature Engineering werden betriebswirtschaftliche Kenntnisse, Mathematik und Statistik angewandt, um Daten in eine Form umzuwandeln, die Machine-Learning-Modelle nutzen können.
Algorithmen sind auf Daten angewiesen, um maschinelles Lernen zu steuern. Ein Benutzer, der sich mit historischen Daten auskennt, kann das Muster erkennen und dann eine Hypothese entwickeln. Auf der Grundlage dieser Hypothese kann der Benutzer das wahrscheinliche Ergebnis vorhersagen, zum Beispiel welche Kunden in einem bestimmten Zeitraum wahrscheinlich bestimmte Produkte kaufen werden. Beim Feature Engineering geht es darum, die bestmögliche Kombination von Hypothesen herauszufinden.
Das Feature Engineering ist von entscheidender Bedeutung, denn wenn der Benutzer die falsche Hypothese als Eingabe angibt, ist das maschinelle Lernen nicht in der Lage, genaue Vorhersagen zu treffen. Die Qualität der Hypothesen, die dem Algorithmus für maschinelles Lernen zur Verfügung gestellt werden, ist der Schlüssel zum Erfolg eines maschinellen Lernmodells.
Darüber hinaus beeinflusst das Feature Engineering die Leistung und die Genauigkeit von Modellen für maschinelles Lernen. Es hilft dabei, die verborgenen Muster in den Daten aufzudecken und die Vorhersagekraft des Machine-Learning-Modells zu erhöhen.
Damit maschinelle Algorithmen richtig funktionieren, müssen die Benutzer die richtigen Daten eingeben, die die Algorithmen verstehen können. Feature Engineering wandelt diese Eingabedaten in eine einzige aggregierte Form um, die für maschinelles Lernen optimiert ist. Mit Feature Engineering kann maschinelles Lernen seine Aufgabe erfüllen, zum Beispiel die Vorhersage von Kundenabwanderung für Einzelhändler oder die Verhinderung von Betrug für Finanzinstitute.
Feature Engineering in der prädiktiven Modellierung
Eine effektive Methode zur Verbesserung von Vorhersagemodellen ist das Feature Engineering, der Prozess der Erstellung neuer Input-Features für maschinelles Lernen.
Eines der Hauptziele der prädiktiven Modellierung ist es, eine wirksame und zuverlässige Vorhersagebeziehung zwischen einem verfügbaren Satz von Features und einem Ergebnis zu finden: zum Beispiel wie wahrscheinlich es ist, dass ein Kunde eine gewünschte Aktion ausführt.
Feature Engineering ist der Prozess der Auswahl und Umwandlung von Variablen bei der Erstellung eines Vorhersagemodells durch maschinelles Lernen. Es ist eine gute Methode zur Verbesserung von Vorhersagemodellen, da sie die Isolierung von Schlüsselinformationen, die Hervorhebung von Mustern und die Einbeziehung von Fachleuten beinhaltet.
Die Daten, die zur Erstellung eines Vorhersagemodells verwendet werden, bestehen aus einer Ergebnisvariablen, die Daten enthält, die vorhergesagt werden müssen, und einer Reihe von Vorhersagevariablen, das heißt Features, die Daten enthalten, die ein bestimmtes Ergebnis vorhersagen können.
In einem Modell zur Vorhersage des Preises eines bestimmten Hauses sind die Ergebnisvariable beispielsweise die Daten, die den tatsächlichen Preis zeigen. Die Vorhersagevariablen sind Daten, die zum Beispiel die Größe des Hauses, die Anzahl der Schlafzimmer und die Lage angeben, Merkmale, von denen angenommen wird, dass sie den Wert des Hauses bestimmen.






