Failover Cluster

Was ist ein Failover Cluster?
In der Datenverarbeitung bezeichnet ein Failover Cluster eine Gruppe voneinander unabhängiger Server, die gemeinsam daran arbeiten, eine hohe Verfügbarkeit von Anwendungen und Diensten zu gewährleisten. Sollte einer der Server ausfallen, kann ein anderer Knoten des Clusters dessen Arbeitslast mit geringer oder sogar ohne Ausfallzeit übernehmen. Dieser Vorgang wird als Failover bezeichnet.
Die geclusterten Server in einem Failover Cluster können zusammenwirken, um die Verfügbarkeit und Skalierbarkeit von Anwendungen und Diensten zu verbessern. Durch den Failover-Prozess arbeiten die Server gemeinsam daran, entweder eine kontinuierliche Verfügbarkeit oder zumindest eine hohe Verfügbarkeit (HA) sicherzustellen. Failover Cluster können sowohl aus physischen Servern als auch aus virtuellen Maschinen (VMs) bestehen.
Jeder Server in einem Failover Cluster wird als Knoten bezeichnet und ist sowohl über physische Kabel als auch über Software mit den anderen Servern im Cluster verbunden. Ein Failover Cluster besteht aus mindestens zwei Knoten, um Daten zu übertragen, sowie aus Software, um die Daten über die Kabel zu verarbeiten. Darüber hinaus nutzt ein Cluster eine oder mehrere Technologien für Lastausgleich, Speicherung, Parallelverarbeitung und andere Funktionen.
Die Anwendungen und Dienste in einem Failover Cluster werden gelegentlich als Cluster-Rollen bezeichnet. Der Cluster sorgt dafür, dass diese Rollen auch dann betriebsbereit bleiben, wenn ein Server ausfällt. Gleichzeitig wird jede Rolle proaktiv überwacht, um sicherzustellen, dass sie ordnungsgemäß funktioniert. Sollte dies nicht der Fall sein, wird sie möglicherweise neu gestartet oder die Rolle wird auf einen anderen Knoten verschoben.
Wann sind Failover Cluster notwendig?
Serverausfälle verursachen Anwendungsausfälle, was wiederum die Benutzererfahrung gefährdet. Failover-Cluster bieten kontinuierliche Verfügbarkeit oder Hochverfügbarkeit und ermöglichen es den Benutzern, die von ihnen benötigten Anwendungen und Dienste weiterhin zu nutzen, selbst wenn ein Server ausfällt. Bei Hochverfügbarkeits-Clustern kommt es manchmal während des Failover-Prozesses zu einer kurzen Serviceunterbrechung. Das System erholt sich jedoch in der Regel schnell und mit geringem oder gar keinem Datenverlust und minimaler Ausfallzeit.
Failover-Cluster spielen eine wichtige Rolle bei der Sicherstellung der ständigen Verfügbarkeit von geschäftskritischen Anwendungen und Systemen wie Online-Transaktionsverarbeitung (OLTP), die eine sehr hohe – nahezu 100-prozentige – Verfügbarkeit erfordern. Datenbankreplikation und Disaster Recovery (DR) erfordern ebenfalls Failover-Cluster. Diese Cluster bieten eine geografische Replikation, so dass bei einem Ausfall eines Servers an einem Standort die Daten weiterhin auf Failover-Servern an anderen Standorten verfügbar sind.
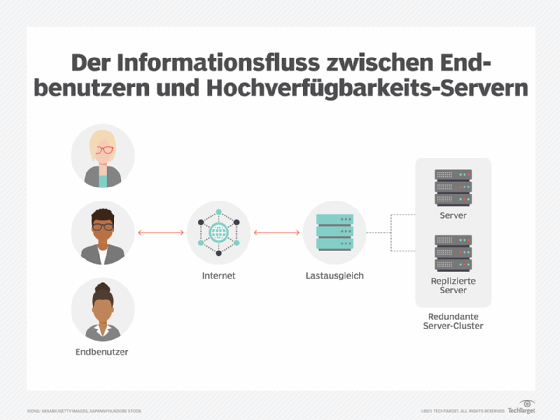
Die Funktionsweise von Failover Clustern
In einem Hochverfügbarkeits-Failover-Cluster teilen sich Gruppen von unabhängigen Servern Daten und Ressourcen, einschließlich Speicher. Zu jedem Zeitpunkt ist mindestens ein Knoten aktiv und mindestens ein Knoten passiv. Diese Cluster verfügen über eine Überwachungsverbindung, die es jedem Server ermöglicht, den Zustand der anderen Server zu überprüfen. Fällt in einem Cluster mit zwei Knoten (der einfachsten möglichen Konfiguration) ein Knoten aus, erkennt der andere Knoten den Ausfall über die Überwachungsverbindung und konfiguriert sich selbst als aktiven Knoten. Größere Konfigurationen verwenden in der Regel dedizierte Server, die feststellen, ob ein Knoten ausfällt und dann einen anderen Knoten anweisen, die Last zu übernehmen und am Failover-Prozess teilzunehmen.
In hochverfügbaren Failover-Clustern mit VMs werden die VMs zusammen mit den physischen Servern, auf denen sie sich befinden, in einem Cluster zusammengefasst. Bei einem Ausfall werden die VMs auf dem ausgefallenen Host auf alternativen Hosts neu gestartet.
In einem Continuous-Availability-Failover-Cluster – auch als fehlertolerantes Cluster bezeichnet – teilen sich mehrere Systeme eine Kopie des Betriebssystems (OS) eines Computers. Somit werden die von einem System ausgegebenen Befehle gleichzeitig auch auf den anderen Systemen ausgeführt. Der Cluster erfordert eine ständig verfügbare und nahezu exakte Kopie eines Rechners, auf dem der Dienst läuft (physisch oder virtuell). Dieses Redundanzmodell wird als 2N bezeichnet. Es erkennt automatisch Ausfälle von Festplatten, Netzteilen, Netzwerkkomponenten und CPUs. Wenn der Cluster einen Fehler feststellt, nimmt eine Sicherungskomponente – oder ein Verfahren – sofort und ohne Dienstunterbrechung dessen Platz ein.
Hochverfügbarkeits-Failover-Cluster versus Continuous-Availability-Failover-Cluster
Hochverfügbarkeitscluster streben eine Verfügbarkeit von 99,999 Prozent an (fünf 9s Verfügbarkeit). Diese Cluster sind im Allgemeinen für die meisten Anwendungen und Dienste ausreichend. Für Dienste oder Anwendungen, die eine 100-prozentige Verfügbarkeit erfordern, sind jedoch Failover-Cluster mit kontinuierlicher Verfügbarkeit erforderlich. Dazu gehören unternehmenskritische Anwendungen wie elektronischer Aktienhandel, ATM-Banking, Auftragsverwaltung, Zeiterfassungssysteme für Mitarbeiter und Reservierungssysteme. Viele Anwendungen in den Bereichen Fertigung, Logistik und E-Commerce erfordern ebenfalls kontinuierlich verfügbare Failover-Cluster.

Verschiedene Typen von Failover Cluster
Failover Clustering ist eine beliebte Funktion in Windows Server und Azure Stack HCI. Mit diesen Betriebssystemen erstellen Unternehmen hochverfügbaren oder kontinuierlich verfügbaren Dateifreigabespeicher für Anwendungen wie Microsoft SQL Server und Hyper-V VMs erstellen. Ein anderer Ansatz besteht darin, hochverfügbare geclusterte Rollen auf physischen Servern oder VMs zu erstellen, die auf Servern mit Hyper-V installiert sind.
Failover-Cluster in Windows bieten Cluster Shared Volume (CSV) Funktionalität. CSV bietet ein universelles, geclustertes Dateisystem, das über NTFS oder ReFS geschichtet ist. Mehrere Clusterknoten lassen sich von derselben LUN (Teil eines Laufwerks oder einer Sammlung von Laufwerken), die als NTFS-Volume bereitstellen, lesen oder darauf schreiben. CSVs bieten einen konsistenten verteilten Namensraum, der von Cluster-Rollen verwendet werden kann, um von allen Knoten aus auf gemeinsamen Speicher zuzugreifen, und vereinfachen die Verwaltung einer großen Anzahl von LUNs in einem Failover-Cluster.
Failover-Cluster sind auch in VMWare, SQL Server und Red Hat Enterprise Linux verfügbar. VMware bietet zahlreiche Virtualisierungs-Tools für VM-Failover-Cluster. So repliziert beispielsweise vSphere vMotion eine VMware-VM und ihr Netzwerk, um eine kontinuierliche Verfügbarkeit zu gewährleisten. VMware vSphere bündelt VMs und ihre Hosts in einem Cluster für automatisches Failover und hohe Verfügbarkeit.
SQL Server 2017 verfügt über eine hochverfügbare Failover-Clustering-Lösung namens Always On, die SQL Server-Komponenten als Cluster-Ressourcen registriert und ein automatisches Failover auf einen anderen Knoten ermöglicht, wenn ein Knoten ausfällt. Red Hat Enterprise Linux bietet ebenfalls einen Failover-Cluster-Mechanismus, mit dem Benutzer hochverfügbare Failover-Cluster mit dem Red Hat Global File System (GFS/GFS2) erstellen.
Was ist Cluster-Affinität?
Affinität bezieht sich auf eine Regel, die ein Benutzer einrichten würde, um eine Beziehung zwischen zwei oder mehr Rollen herzustellen, um sie zusammenzuhalten. Zu diesen Rollen gehören VMs, Ressourcengruppen oder andere Entitäten. Anti-Affinität ist ebenfalls eine Regel, allerdings eine, die dazu dient, die angegebenen Rollen voneinander zu trennen.
Diese Regeln sind erforderlich, da ein Failover-Cluster oft viele Rollen enthält, die zwischen den Knoten verschoben und ausgeführt werden. Wenn jedoch bestimmte Rollen nicht auf demselben Knoten laufen sollen, müssen sie voneinander getrennt werden. Affinitäts- und Anti-Affinitätsregeln helfen dabei, Leistungsprobleme zu vermeiden, die auftreten, wenn Rollen, die auf demselben Knoten ausgeführt werden, mehr Ressourcen oder Speicher verwenden, als sie sollten.





