Ensemble Modeling (Ensemblemodellierung)
Was ist Ensemble Modeling (Ensemblemodellierung)?
Beim Ensemble Modeling, auch Ensemblemodellierung, werden zwei oder mehr verwandte, aber unterschiedliche Analysemodelle ausgeführt und die Ergebnisse zu einem einzigen Score oder einer Streuung zusammengefasst. Dadurch wird die Genauigkeit von prädiktiven Analysen und Data-Mining-Anwendungen verbessert. Ensemblemodellierungstechniken werden häufig bei Anwendungen des maschinellen Lernens eingesetzt, um die Gesamtvorhersageleistung zu verbessern.
Analytische und maschinelle Lernmodelle verarbeiten einige Eingaben und identifizieren Muster in diesen Eingaben. Auf Grundlage dieser Muster erzeugen sie dann eine Ausgabe (ein Ergebnis), bei der es sich in der Regel um eine Art Vorhersage handelt.
Bei vielen Anwendungen reicht ein Modell nicht aus, um genaue Vorhersagen zu treffen (das heißt Vorhersagen mit geringem Generalisierungsfehler). Um den Vorhersageprozess zu verbessern und bessere Vorhersageergebnisse zu erzielen, werden mehrere Modelle kombiniert und trainiert. Dieser Ansatz wird als Ensemble Modeling bezeichnet.
Die Kombination mehrerer Modelle ist gleichbedeutend mit der Suche nach dem Wissen der Masse bei der Erstellung von Vorhersagen und der Verringerung des Vorhersage- oder Verallgemeinerungsfehlers. Es ist wichtig zu beachten, dass der Vorhersagefehler des Ensemblemodells nur dann abnimmt, wenn die Basisschätzer sowohl unterschiedlich als auch unabhängig sind.
Die zu kombinierenden Modelle werden als Basisschätzer, Basislerner oder Modelle der ersten Ebene bezeichnet. Unabhängig davon, wie viele Basisschätzer verwendet werden, verhält sich das Ensemblemodell wie ein einziges Modell und erbringt die gleiche Leistung.
Die Notwendigkeit des Ensemble Modeling
Beim maschinellen Lernen, der prädiktiven Modellierung und anderen Arten der Datenanalyse kann ein einzelnes Modell, das auf einer Datenprobe oder einem Datensatz basiert, Verzerrungen aufweisen und somit Ergebnisse liefern, die auf einer Analyse von zu wenigen Merkmalen basieren. Es kann auch eine hohe Variabilität aufweisen, was bedeutet, dass das Modell zu empfindlich auf die Eingaben für die gelernten Merkmale reagiert. Ein weiteres Problem besteht darin, dass es völlige Ungenauigkeiten aufweisen kann, so dass es nicht den gesamten Trainingsdatensatz korrekt abbildet. All diese Probleme können die Zuverlässigkeit der analytischen oder prädiktiven Ergebnisse des Modells beeinträchtigen.
Durch die Kombination verschiedener Modelle oder die Analyse mehrerer Stichproben können Datenwissenschaftler, Datenanalysten und Ingenieure für maschinelles Lernen die Auswirkungen dieser Einschränkungen verringern. Sie können die Gesamtgenauigkeit der Ergebnisse steigern, indem sie Fehler reduzieren und den Entscheidungsträgern bessere Informationen zur Verfügung stellen. Ensemble Modeling steigert auch die Widerstandsfähigkeit gegenüber Unsicherheiten im Datensatz und erhöht die Wahrscheinlichkeit, dass robustere und zuverlässigere Prognosen erstellt werden.
Ensemble Modeling wird immer beliebter, da immer mehr Unternehmen die für die Ausführung solcher Modelle erforderlichen Rechenressourcen und fortschrittliche Analysesoftware einsetzen. Hadoop und andere Big-Data-Technologien haben Unternehmen dazu veranlasst, größere Datenmengen zu speichern und zu analysieren, was zu einem größeren Potenzial für die Ausführung von Analysemodellen auf verschiedenen Datenproben oder, anders ausgedrückt, für Ensemblemodelle führt.
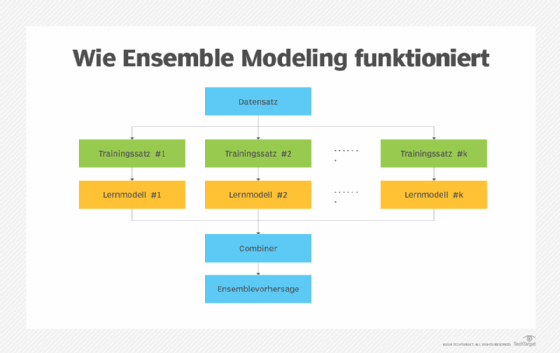
Beispiel für Ensemble Modeling
Ein Random-Forest-Modell ist ein gängiges Beispiel für Ensemble Modeling. Bei diesem Ansatz werden mehrere Entscheidungsbäume verwendet – ein analytisches Modell, das Ergebnisse auf der Grundlage verschiedener Variablen und Regeln vorhersagt. Dabei werden Entscheidungsbäume kombiniert, die möglicherweise unterschiedliche Beispieldaten analysieren, verschiedene Faktoren bewerten oder gemeinsame Variablen unterschiedlich gewichten. Die Ergebnisse der verschiedenen Entscheidungsbäume werden dann entweder in einen einfachen Durchschnitt umgewandelt oder durch weitere Gewichtung aggregiert.
Der Random-Forest-Algorithmus ist ein beliebter Algorithmus des maschinellen Lernens. Er gehört zu den Bagging-Techniken, die zur Erstellung von Ensemblemodellen verwendet werden, bei denen verschiedene Modelle eine Teilmenge des Trainingsdatensatzes verwenden, um Varianz und Overfitting zu minimieren.
Techniken des Ensemble Modelings
Zur Erstellung von Ensemblemodellen werden viele Techniken verwendet, insbesondere beim maschinellen Lernen. Dies sind die beliebtesten Techniken: Stacking, Bagging, Blending und Boosting.
Stacking
Stacking, auch bekannt als Stacked-Ensembles-Methode oder Stacked-Generalisierung, ist ein Prozess, bei dem die Vorhersagen von mehreren Basisschätzern kombiniert werden, um ein neues Modell zu erstellen, das bessere (das heißt genauere) Vorhersagen liefert.
Wie das funktioniert: Mehrere Basismodelle (manchmal auch als weak learners – schwacher Lerner – bezeichnet) werden mit demselben Trainingsdatensatz trainiert. Ihre Vorhersagen werden dann in ein übergeordnetes Modell eingespeist, um die endgültige Vorhersage zu treffen. Letzteres, auch als Metamodell oder Modell der zweiten Ebene bezeichnet, kombiniert die Vorhersagen aller Basismodelle, um die endgültige Vorhersage zu erstellen.
Bagging
Wie beim Stacking werden auch beim Bagging die Ergebnisse mehrerer Modelle kombiniert, um ein verallgemeinertes Ergebnis zu erhalten. Dabei ist zu beachten, dass die verschiedenen Modelle auf leicht unterschiedlichen Teilmengen des ursprünglichen Datensatzes trainiert werden.
Wie das funktioniert: Es werden mehrere Sätze der ursprünglichen Trainingsdaten mit Ersetzungen erstellt. Alle Teilmengen haben die gleiche Größe. Diese Teilmengen werden auch als Bags bezeichnet, und die Methode wird als Bootstrap-Aggregation bezeichnet. Hier werden die Bags verwendet, um eine faire Vorstellung von der Gesamtmenge zu erhalten und die Modelle parallel zu trainieren.
Blending
Blending ist wie Stacking. Ein wesentlicher Unterschied besteht darin, dass das endgültige Modell sowohl mit Trainings- als auch mit Validierungsdaten (Holdout) trainiert wird.
Wie das funktioniert: Beim Blending werden sowohl der Validierungssatz als auch die Vorhersagen verwendet, um ein Modell zu erstellen. Das Modell wird auf den Trainingssatz angepasst, während die Vorhersagen auf dem Validierungssatz und dem Testsatz gemacht werden. Die Merkmale werden erweitert, um den Validierungssatz einzubeziehen, und das Modell wird zur Erstellung der endgültigen Vorhersagen verwendet.
Boosting
Boosting ist eine sequenzielle Ensemblemodellierungstechnik, bei der die Fehler eines Modells durch das nachfolgende Modell korrigiert werden. Die Modelle, deren Fehler korrigiert werden, werden als weak learners bezeichnet. Adaptives Boosting ist die beliebteste Version der Boosting-Ensemblemodellierungstechnik beim maschinellen Lernen.
Wie das funktioniert: Es wird eine Teilmenge der ursprünglichen Trainingsdaten erstellt, wobei alle Datenpunkte gleich gewichtet werden. Diese Teilmenge wird verwendet, um ein Basismodell zu erstellen, das Vorhersagen für den gesamten Datensatz macht. Auf der Grundlage der tatsächlichen und der vorhergesagten Werte werden die Fehler berechnet, und die falsch vorhergesagten Beobachtungen werden höher gewichtet. Es wird ein neues Modell erstellt, das versucht, die Fehler zu korrigieren, und es werden neue Vorhersagen für den Datensatz getroffen. Dieser Prozess wird fortgesetzt, wobei jedes neue Modell versucht, die Fehler des vorherigen Modells zu korrigieren, bis ein endgültiges Modell oder ein strong learner (starker Lerner) erstellt wird. Dieses Modell ist das gewichtete Mittel aller schwachen Lernmodelle und verbessert die Gesamtleistung des Ensembles.






