Disaster-Recovery-Plan (DRP)
Was ist ein Disaster Recovery Plan (DRP, Notfallwiederherstellungsplan)?
Ein Disaster Recovery Plan (DRP) ist ein dokumentierter, strukturierter Ansatz, der beschreibt, wie eine Organisation nach einem ungeplanten Vorfall schnell wieder den Betrieb aufnehmen kann. Ein DRP ist ein wesentlicher Bestandteil eines Business-Continuity-Plan (BCP). Er wird auf die Aspekte einer Organisation angewendet, die von einer funktionierenden IT-Infrastruktur abhängig sind. Ein DRP soll einer Organisation helfen, Datenverluste zu beheben und die Systemfunktionalität wiederherzustellen, um nach einem Vorfall wieder leistungsfähig zu sein, selbst wenn sie nur auf minimalem Niveau arbeitet.
Der Plan besteht aus Schritten zur Minimierung der Auswirkungen einer Katastrophe, damit die Organisation weiterarbeiten oder geschäftskritische Funktionen schnell wieder aufnehmen kann. In der Regel umfasst ein DRP eine Analyse der Geschäftsprozesse und der Kontinuitätsanforderungen. Vor der Erstellung eines detaillierten Plans führt eine Organisation häufig eine Business-Impact-Analyse (BIA) und eine Risikoanalyse durch und legt Wiederherstellungsziele fest.
Da Cyberkriminalität und Sicherheitsverletzungen immer ausgefeilter werden, müssen Organisationen ihre Strategien zur Datenwiederherstellung und zum Datenschutz definieren. Die Fähigkeit, Vorfälle schnell zu bearbeiten, kann Ausfallzeiten reduzieren und finanzielle und rufschädigende Schäden minimieren. DRPs helfen Organisationen auch dabei, Compliance-Anforderungen zu erfüllen, und bieten gleichzeitig einen klaren Fahrplan für die Wiederherstellung.
Kurze Geschichte des DRP
DRP hat sich im Laufe der Jahre erheblich weiterentwickelt und wurde durch verschiedene Faktoren wie technologischen Fortschritt, regulatorische Anforderungen und den Aufstieg des Cloud Computing geprägt.
- Ende der 1970er Jahre. Die meisten Unternehmen begannen, sich stark auf Computerinformationssysteme zu verlassen. Dies führte zur Entwicklung von Notfallwiederherstellungsplänen.
- 1983. Ein entscheidender Schritt zur Formalisierung der DR-Planung wurde unternommen, als die US-Gesetzgebung die nationalen Banken dazu verpflichtete, überprüfbare Backup-Pläne zu erstellen.
- Anfang der 1990er Jahre. Das Disaster Recovery Institute erweiterte seine Flaggschiff-Zertifizierung von der Notfallwiederherstellung auf die Geschäftskontinuität und erkannte damit die zunehmende Bedeutung einer umfassenden Planung an, die über IT-Systeme hinausgeht.
- Gegenwart. Der Aufstieg von Cloud Computing und -Diensten hat es Unternehmen ermöglicht, ihre DRPs an Drittanbieter zu delegieren, was zur Entwicklung von Disaster Recovery as a Service (DRaaS) führte. Dieser Ansatz kommt dem Unternehmenswachstum entgegen und bietet Vorteile in Bezug auf Wiederherstellungszeiten, Flexibilität und Kosten.
Was gilt als Katastrophe?
Eine Katastrophe ist ein Ereignis, das den normalen Betrieb eines Unternehmens oder einer Organisation stark beeinträchtigt. Katastrophen können eine Vielzahl von Ereignissen umfassen, darunter Naturereignisse wie Erdbeben und Überschwemmungen sowie von Menschen verursachte Vorfälle wie Cyberangriffe und Industrieunfälle.
Zu den Arten von Katastrophen, auf die Organisationen sich vorbereiten können, gehören:
- Anwendungsfehler
- Kommunikationsfehler
- Stromausfall
- Naturkatastrophe
- Malware oder andere Cyberangriffe
- Transportunfälle
- Netzwerkausfälle
- Katastrophen in Rechenzentren
- Gebäudekatastrophen
- Campus-Katastrophen
- Stadtweite Katastrophen
- Regionale Katastrophen
- Nationale Katastrophen
- Multinationale Katastrophen
Was Sie bei einem Disaster-Recovery-Plan beachten sollten
Wenn eine Katastrophe eintritt, sollte die Wiederherstellungsstrategie auf Unternehmensebene beginnen, um zu bestimmen, welche Anwendungen für den Betrieb der Organisation am wichtigsten sind. Das Recovery Time Objective(RTO) beschreibt die Zeit, die kritische Anwendungen ausfallen können, in der Regel gemessen in Stunden, Minuten oder Sekunden. Das Recovery Point Objective (RPO) beschreibt das Alter der Dateien, die aus dem Backup-Speicherwiederhergestellt werden müssen, damit der normale Betrieb wieder aufgenommen werden kann.
Wiederherstellungsstrategien definieren die Pläne einer Organisation für die Reaktion auf einen Vorfall, während DR-Pläne beschreiben, wie die Organisation reagieren sollte. Wiederherstellungspläne werden aus Wiederherstellungsstrategien abgeleitet.

Bei der Festlegung einer Wiederherstellungsstrategie sollten Organisationen die folgenden Punkte berücksichtigen:
- Budget.
- Versicherungsschutz.
- Ressourcen – Mitarbeiter und physische Einrichtungen.
- Die Einstellung des Managementteams zu Risiken.
- Technologie.
- Daten und Datenspeicher.
- Lieferanten.
- Compliance-Anforderungen.
Die Genehmigung von Wiederherstellungsstrategien durch das Management ist wichtig. Alle Strategien sollten auf die Ziele der Organisation abgestimmt sein. Sobald DR-Strategien entwickelt und genehmigt wurden, können sie in DR-Pläne umgesetzt werden.
Arten von Disaster-Recovery-Plänen
DRPs können auf eine bestimmte Umgebung zugeschnitten werden. Zu den spezifischen Arten von Plänen gehören die folgenden:
- Virtualisierter DR-Plan. Die Virtualisierung bietet Organisationen die Möglichkeit, das DR effizienter und einfacher durchzuführen. Eine virtualisierte Umgebung kann innerhalb von Minuten neue virtuelle Maschineninstanzen hochfahren und eine Anwendungswiederherstellung durch hohe Verfügbarkeit ermöglichen. Auch das Testen ist einfacher, aber der Plan muss sicherstellen, dass Anwendungen im DR-Modus ausgeführt und innerhalb der RPO und RTO wieder in den Normalbetrieb zurückgeführt werden können.
- Netzwerk-DR-Plan. Die Entwicklung eines Plans zur Wiederherstellung eines Netzwerks wird mit zunehmender Komplexität des Netzwerks immer komplizierter. Es ist wichtig, ein detailliertes, schrittweises Wiederherstellungsverfahren bereitzustellen, dieses ordnungsgemäß zu testen und auf dem neuesten Stand zu halten. Der Plan sollte netzwerkspezifische Informationen enthalten, zum Beispiel zur Leistung und zu den Netzwerkmitarbeitern.
- Cloud-DR-Plan. Cloud-Notfallwiederherstellung kann von Dateisicherungsverfahren in der Cloud bis hin zur vollständigen Replikation reichen. Cloud-DR kann platz-, zeit- und kosteneffizient sein, aber die Pflege des DRPs erfordert eine ordnungsgemäße Verwaltung. Der Manager muss den Standort der physischen und virtuellen Serverkennen. Der Plan muss die Sicherheit berücksichtigen, die ein häufiges Problem in der Cloud darstellt und durch Tests gemildert werden kann.
- Disaster-Recovery-Plan für Rechenzentren. Diese Art von Plan konzentriert sich ausschließlich auf die Einrichtung und Infrastruktur des Rechenzentrums. Eine betriebliche Risikobewertung ist ein wichtiger Bestandteil eines DRP für Rechenzentren. Dabei werden Schlüsselkomponenten wie der Standort des Gebäudes, Stromversorgungssysteme und -schutz, Sicherheit und Büroräume analysiert. Der Plan muss eine Vielzahl möglicher Szenarien abdecken.
- DRaaS. Disaster Recovery as a Service (DraaS) ist die kommerzielle Adaption der cloudbasierten Notfallwiederherstellung. Bei diesem Modell übernimmt ein externer Dienstleister die Replikation und das Hosting der physischen und virtuellen Maschinen eines Unternehmens. Der Anbieter ist an eine Service-Level-Vereinbarung (SLA) gebunden und übernimmt die Aufgabe, den DR-Plan in Notfällen auszuführen.
Umfang und Zielsetzung der DR-Planung
Das Hauptziel eines DRP besteht darin, die negativen Auswirkungen eines Vorfalls auf den Geschäftsbetrieb zu minimieren. Der Umfang eines Notfallwiederherstellungsplans kann von grundlegend bis umfassend reichen. Einige DRPs können bis zu 100 Seiten lang sein.
Die Budgets für das Disaster Recovery variieren stark und schwanken im Laufe der Zeit. Organisationen können kostenlose Ressourcen nutzen, wie zum Beispiel Online-DRP-Vorlagen, einschließlich der Business Continuity Test Template von TechTarget.
Mehrere Organisationen, darunter das Business Continuity Institute und das Disaster Recovery Institute International, stellen ebenfalls kostenlose Informationen und Online-Inhalte zur Verfügung.
Eine Checkliste für einen IT-DRP enthält in der Regel Folgendes:
- Festlegung des Umfangs oder Ausmaßes der erforderlichen Maßnahmen und Aktivitäten – den Umfang der Wiederherstellung.
- Sammlung relevanter Dokumente zur Netzwerkinfrastruktur.
- Ermittlung der schwerwiegendsten Bedrohungen und Schwachstellen sowie der wichtigsten Vermögenswerte.
- Mitarbeiter, die für diese Systeme und Netzwerke verantwortlich sind.
- RTO- und RPO-Informationen.
- Standorte für die Notfallwiederherstellung – zum Beispiel Hot Sites, Warm Sites und Cold Sites.
- Überprüfung der Historie ungeplanter Vorfälle und Ausfälle sowie der Art und Weise, wie diese gehandhabt wurden.
- Festlegen der aktuellen Verfahren und Strategien für das Disaster Recovery.
- Festlegen des DR-Teams.
- Schritte zum Neustart, zur Neukonfiguration und zur Wiederherstellung von Systemen und Netzwerken.
- Sonstige Notfallmaßnahmen, die im Katastrophenfall erforderlich sind.
- Überprüfung und Genehmigung des DRP durch die Geschäftsführung.
- Testen des Plans.
- Aktualisieren des Plans.
- Erstellen eines DRP- oder BCP-Audits.
Der Standort eines Disaster-Recovery-Standorts sollte in einem DRP sorgfältig abgewogen werden. Die Entfernung ist ein wichtiges, aber oft übersehenes Element des DRP-Prozesses. Ein externer Standort in der Nähe des primären Rechenzentrums mag ideal erscheinen – in Bezug auf Kosten, Bequemlichkeit, Bandbreite und Tests. Allerdings unterscheiden sich Ausfälle stark in ihrem Umfang. Ein schwerwiegendes regionales Ereignis kann das primäre Datenzentrum und seinen DR-Standort zerstören, wenn beide zu nahe beieinander liegen.
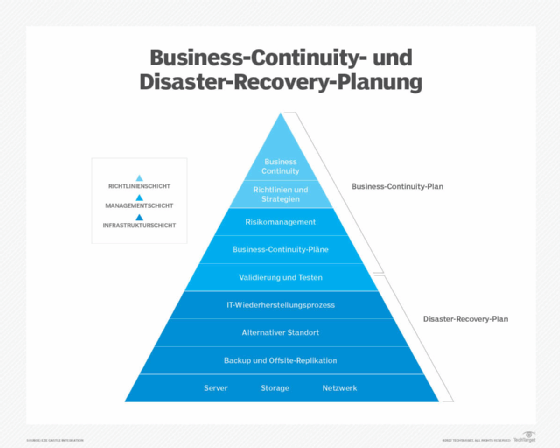
So legen Sie einen Disaster-Recovery-Plan an
Der Prozess der Erstellung eines DRPs umfasst mehr als nur das Schreiben des Dokuments. Vor dem Verfassen des DRP können eine Risikoanalyse und eine Analyse der geschäftlichen Auswirkungen dabei helfen, festzulegen, worauf sich die Ressourcen während des DR-Prozesses konzentrieren sollten.
In der Regel umfasst die Erstellung eines DRP die folgenden Schritte:
- Durchführung einer BIA. Die Business Impact Analysis identifiziert die Auswirkungen von Störereignissen und ist der Ausgangspunkt für die Identifizierung von Risiken im Rahmen der DR. Sie generiert auch die RTO und RPO.
- Erstellen Sie eine Risikoanalyse. Die Risikoanalyse identifiziert Bedrohungen und Schwachstellen, die den Betrieb der in der BIA hervorgehobenen Systeme und Prozesse stören könnten. Sie bewertet die Wahrscheinlichkeit eines Störfalls und skizziert dessen potenziellen Schweregrad.
- Entwickeln Sie eine Zielerklärung. Eine Zielerklärung beschreibt die Ziele, die eine Organisation während oder nach einer Katastrophe erreichen möchte, und umfasst sowohl die RTO als auch die RPO.
- Bestimmen Sie das DRP-Team. Notfallwiederherstellungspläne sind dynamische Dokumente. Die Einbeziehung von Mitarbeitern – vom Management bis zum Berufsanfänger – erhöht den Wert des Plans. Jeder DR-Plan sollte die Personen benennen, die mit der Ausführung betraut sind, und Maßnahmen enthalten, die bei Abwesenheit von Schlüsselpersonal zu ergreifen sind.
- Erstellen Sie eine IT-Bestandsliste. Legen Sie ein Inventar an, das die Kosten, das Modell, die Seriennummer, den Hersteller und die Angabe, ob es sich um ein gemietetes oder ein eigenes Gerät handelt, für jedes Gerät enthält.
- Erstellen Sie eine interne Kommunikationsstrategie. Ein weiterer Bestandteil des DRP ist der Kommunikationsplan. Diese Strategie sollte detailliert beschreiben, wie sowohl die interne als auch die externe Krisenkommunikation gehandhabt wird. Zur internen Kommunikation gehören Warnmeldungen, die per E-Mail, über Lautsprecheranlagen in Gebäuden, Sprachnachrichten und Textnachrichten an Mobilgeräte gesendet werden können. Beispiele für interne Kommunikation sind Anweisungen zur Evakuierung des Gebäudes und zur Versammlung an bestimmten Orten, Aktualisierungen zum Fortschritt der Situation und Mitteilungen, wann die Rückkehr ins Gebäude sicher ist.
- Erstellen Sie eine Strategie für die externe Kommunikation. Die externe Kommunikation ist für den BCP noch wichtiger und umfasst Anweisungen, wie Familienmitglieder im Falle einer Verletzung oder eines Todesfalls benachrichtigt werden können, wie wichtige Kunden und Interessengruppen über den Stand der Katastrophe informiert und auf dem Laufenden gehalten werden können und wie Katastrophen mit den Medien besprochen werden können.
- Erstellen Sie einen Plan für Backup, Recovery und Redundanz. Ein detaillierter Plan für Datensicherung, Systemwiederherstellung und Wiederherstellung des Betriebs sollte vorgeschrieben werden. Der Plan sollte auch Redundanz- und Failover-Mechanismen für kritische Infrastrukturen und Systeme hervorheben.
- Testen Sie den DR-Plan. Der DR-Plan sollte regelmäßig getestet werden, um Schwachstellen und Verbesserungsmöglichkeiten zu ermitteln. Im Rahmen der Tests sollten auch Schulungen durchgeführt werden, um die Mitarbeiter mit ihren Rollen und Verantwortlichkeiten im Katastrophenfall vertraut zu machen.
- Regelmäßige Überprüfung und Überarbeitung des Plans. Der DR-Plan sollte regelmäßig überprüft und überarbeitet werden, um Änderungen in der Unternehmenstechnologie, im Betrieb und bei potenziellen Risikofaktoren zu berücksichtigen.
Kostenlose DRP-Vorlage
Eine Organisation kann ihren Notfallwiederherstellungsplan mit einer Zusammenfassung der wichtigsten Handlungsschritte und einer Liste wichtiger Kontaktinformationen beginnen. So sind die wichtigsten Informationen schnell und einfach zugänglich.
Der Plan sollte die Rollen und Verantwortlichkeiten der Mitglieder des DR-Teams definieren und die Kriterien für die Umsetzung des Plans darlegen. Der Plan sollte die Maßnahmen zur Reaktion auf Vorfälle und die Wiederherstellungsaktivitäten detailliert beschreiben. Sobald die Vorlage erstellt ist, wird empfohlen, sie an einem sicheren und zugänglichen Ort außerhalb des Unternehmens aufzubewahren.
Zu den weiteren wichtigen Elementen einer Vorlage für einen Notfallwiederherstellungsplan gehören:
- Absichtserklärung und DR-Richtlinienerklärung.
- Planungsziele.
- Authentifizierungs-Tools, wie zum Beispiel Passwörter.
- Geografische Risiken und Faktoren
- Tipps für den Umgang mit den Medien
- Finanzielle und rechtliche Informationen und Handlungsschritte
- Planhistorie
Testen des Disaster-Recovery-Plans
DRPs werden durch Tests untermauert, um Mängel zu identifizieren und Organisationen die Möglichkeit zu geben, Probleme zu beheben, bevor ein Notfall eintritt. Tests können den Nachweis erbringen, dass der Notfallplan wirksam ist und die RPOs und RTOs erfüllt. Da sich IT-Systeme und -Technologien ständig ändern, helfen DR-Tests auch dabei, sicherzustellen, dass ein DR-Plan auf dem neuesten Stand ist.
Zu den Gründen, die gegen das Testen von DRPs sprechen, gehören Budgetbeschränkungen, Ressourcenknappheit und fehlende Genehmigung durch das Management. DR-Tests erfordern Zeit, Ressourcen und Planung. Sie können auch riskant sein, wenn der Test die Verwendung von Live-Daten umfasst.
DR-Tests sind unterschiedlich komplex. In der Regel gibt es vier Arten von DRP-Tests:
- Planprüfung. Eine Planprüfung umfasst eine detaillierte Diskussion des DRP und sucht nach fehlenden Elementen und Inkonsistenzen.
- Tabletop-Übung. Bei einem Tabletop-Test durchlaufen die Teilnehmer Schritt für Schritt Katastrophenszenarien und geplante Aktivitäten, um zu zeigen, ob die Mitglieder des DR-Teams ihre Aufgaben im Notfall kennen. Dies hilft, Lücken im DR-Plan zu identifizieren und zu verstehen, wie verschiedene Interessengruppen auf die Situation reagieren würden.
- Paralleltests. Bei Paralleltests werden sowohl das Primärsystem als auch das Backup- oder Wiederherstellungssystem gleichzeitig ausgeführt, um ihre Leistung zu vergleichen und die Effektivität des Backup-Systems sicherzustellen. Mit diesem Test können Organisationen beurteilen, ob das Backup-System die Arbeitslast bewältigen und die Datenintegrität aufrechterhalten kann, während das Primärsystem noch in Betrieb ist.
- Simulationstests. Bei einem Simulationstest werden Ressourcen wie Wiederherstellungsstandorte und Backup-Systeme in einem umfassenden Test ohne tatsächliches Failover verwendet. In einer kontrollierten Umgebung werden verschiedene Katastrophenszenarien simuliert, um die Wirksamkeit des DR-Plans zu überprüfen und zu ermitteln, wie schnell ein Unternehmen nach einer Katastrophe den Geschäftsbetrieb wieder aufnehmen kann.
Incident-Management-Plan und Disaster-Recovery-Plan im Vergleich
Ein Incident-Management-Plan (IMP oder IRP) – oder Incident-Response-Plan – sollte ebenfalls in den DRP integriert werden; zusammen bilden die beiden eine umfassende Data-Protection-Strategie. Das Ziel beider Pläne besteht darin, die negativen Auswirkungen eines unerwarteten Vorfalls zu minimieren, sich davon zu erholen und die Organisation so schnell wie möglich wieder auf ihr normales Produktionsniveau zu bringen. Sie sind jedoch nicht dasselbe.
Der Hauptunterschied zwischen einem Incident-Management-Plan und einem Disaster-Recovery-Plan sind ihre Hauptziele, die Folgendes umfassen:
- Ein IMP konzentriert sich auf den Schutz sensibler Daten während eines Ereignisses und definiert den Umfang der während des Vorfalls zu ergreifenden Maßnahmen, einschließlich der spezifischen Rollen und Verantwortlichkeiten des Incident-Response-Teams.
- Das Ziel eines DRP ist es, die Auswirkungen eines unerwarteten Vorfalls zu minimieren, sich von ihm zu erholen und die Organisation so schnell wie möglich zu ihrem normalen Geschäftsbetrieb zurückzuführen.
- Ein IMP ist eine organisierte Reaktion auf Sicherheitsvorfälle, die Verfahren zur Erkennung, Analyse, Eindämmung, Beseitigung und Wiederherstellung umfasst. Er identifiziert die wahrscheinlichsten Bedrohungen und dokumentiert Schritte zu deren Vermeidung. Ein DRP konzentriert sich auf die Definition der Wiederherstellungsziele und der Schritte, die unternommen werden müssen, um die Organisation nach einem Vorfall wieder in einen betriebsfähigen Zustand zu versetzen.
- Ein IMP konzentriert sich darauf, wie ein Unternehmen einen Cyberangriff erkennt und bewältigt, um potenzielle Schäden und Folgen für das Unternehmen zu reduzieren.
- Ein DRP befasst sich mit den größeren Fragen im Zusammenhang mit einem potenziellen Cyberangriff und legt fest, wie das Unternehmen nach einem Sicherheitsvorfall wiederhergestellt wird und den normalen Geschäftsbetrieb wieder aufnimmt.
Beispiele für einen Disaster-Recovery-Plan
Eine Organisation kann einen DR-Plan für verschiedene Situationen verwenden. Im Folgenden finden Sie Beispiele für spezifische Szenarien und die entsprechenden Maßnahmen, die in einem DRP beschrieben sind:
Beispiel 1. Ausfall des Rechenzentrums
Szenario: In einem Rechenzentrum kommt es zu einem Strom- oder Hardwareausfall.
Reaktion:
- Aktivieren Sie Notstromaggregate, um eine kontinuierliche Stromversorgung sicherzustellen.
- Leiten Sie ein Failover auf redundante Systeme oder sekundäre Rechenzentren ein.
- Stellen Sie Daten aus Backups wieder her, die außerhalb des Standorts oder in der Cloud gespeichert sind.
- Informieren Sie die Beteiligten über den Status der Situation und die voraussichtliche Wiederherstellungszeit.
Beispiel 2. Cyberangriff
Szenario: Bei einem Ransomware-Angriff werden kritische Systeme und Daten einer Organisation verschlüsselt.
Reaktion:
- Isolieren Sie betroffene Systeme, um eine weitere Ausbreitung des Angriffs zu verhindern.
- Beauftragen Sie Cybersicherheitsexperten mit der Identifizierung und Eindämmung der Angriffsquelle.
- Stellen Sie Systeme aus sauberen Backups wieder her, um Datenverluste und Ausfallzeiten zu minimieren.
- Ergreifen Sie zusätzliche Sicherheitsmaßnahmen, um zukünftige Angriffe zu verhindern.
Beispiel 3. Menschliches Versagen oder versehentlicher Datenverlust
Szenario: Ein Mitarbeiter löscht versehentlich wichtige Dateien oder Datenbankeinträge.
Reaktion:
- Unterbrechen Sie sofort alle laufenden Vorgänge, die das Problem verschlimmern könnten.
- Versuchen Sie, die gelöschten Daten aus Backups oder Schattenkopien wiederherzustellen.
- Verwenden Sie bei Bedarf Datenwiederherstellungs-Tools oder -dienste, um verlorene Informationen abzurufen.
- Überprüfen Sie die Zugriffskontrollen und Berechtigungen, um das Risiko ähnlicher Vorfälle in Zukunft zu minimieren.







