Datenwissenschaft (Data Science)

Was ist Datenwissenschaft?
Datenwissenschaft (Data Science) ist der Bereich, in dem fortschrittliche Analysetechniken und wissenschaftliche Prinzipien angewandt werden, um aus Daten wertvolle Informationen für die Entscheidungsfindung, strategische Planung und andere Zwecke zu gewinnen.
Sie ist für Unternehmen zunehmend wichtig: Die mit Datenwissenschaft gewonnenen Erkenntnisse unterstützen Unternehmen unter anderem dabei, die betriebliche Effizienz zu steigern, neue Geschäftsmöglichkeiten zu erkennen und Marketing- und Vertriebsprogramme zu verbessern. Letztendlich können sie zu Wettbewerbsvorteilen gegenüber Konkurrenten führen.
Datenwissenschaft umfasst verschiedene Disziplinen, zum Beispiel Data Engineering, Datenaufbereitung, Data Mining, Predictive Analytics, maschinelles Lernen und Datenvisualisierung, sowie Statistik, Mathematik und Softwareprogrammierung. Sie wird in erster Linie von qualifizierten Datenwissenschaftlern durchgeführt, obwohl auch Datenanalysten der unteren Ebene beteiligt sein können. Darüber hinaus stützen sich viele Unternehmen heute teilweise auf sogenannte Citizen Data Scientists, eine Gruppe, die sich aus Business-Intelligence-Fachleuten (BI), Business-Analysten, datenversierten Geschäftsanwendern, Dateningenieuren und anderen Mitarbeitern zusammensetzt, die keinen formalen Hintergrund in den Datenwissenschaften haben.
In diesem umfassenden Leitfaden zu Data Science wird erläutert, was Data Science ist, warum es für Unternehmen wichtig ist, wie es funktioniert, welche geschäftlichen Vorteile es bietet und welche Herausforderungen es mit sich bringt. Außerdem finden Sie einen Überblick über Anwendungen, Tools und Techniken der Datenwissenschaft sowie Informationen darüber, was Datenwissenschaftler tun und welche Fähigkeiten sie benötigen. Im gesamten Leitfaden finden Sie Hyperlinks zu verwandten TechTarget-Artikeln, in denen die hier behandelten Themen vertieft werden und die Einblicke und Expertenratschläge zu Data Science-Initiativen bieten.
Warum ist Datenwissenschaft wichtig?
Data Science spielt eine wichtige Rolle in praktisch allen Aspekten von Geschäftsabläufen und -strategien. So liefert sie beispielsweise Informationen über Kunden, die Unternehmen dabei unterstützen, stärkere Marketingkampagnen und gezielte Werbung zu entwickeln, um den Produktabsatz zu steigern. Sie hilft beim Management finanzieller Risiken, bei der Aufdeckung betrügerischer Transaktionen und bei der Verhinderung von Ausfällen in Produktionsanlagen und anderen industriellen Bereichen. Sie unterstützt bei der Abwehr von Cyberangriffen und anderen Sicherheitsbedrohungen in IT-Systemen.
Aus betrieblicher Sicht können Data-Science-Initiativen das Management von Lieferketten, Produktbeständen, Vertriebsnetzen und Kundenservice optimieren. Auf einer grundsätzlicheren Ebene weisen sie den Weg zu mehr Effizienz und geringeren Kosten. Data Science ermöglicht es Unternehmen auch, Geschäftspläne und Strategien zu erstellen, die auf einer fundierten Analyse des Kundenverhaltens, der Markttrends und des Wettbewerbs beruhen. Ohne sie können Unternehmen Chancen verpassen und falsche Entscheidungen treffen.
Die Datenwissenschaft ist auch in Bereichen außerhalb des regulären Geschäftsbetriebs von entscheidender Bedeutung. Im Gesundheitswesen wird sie unter anderem zur Diagnose von Krankheiten, zur Bildanalyse, zur Behandlungsplanung und zur medizinischen Forschung eingesetzt. Akademische Einrichtungen nutzen die Datenwissenschaft, um die Leistungen von Studenten zu überwachen und ihr Marketing für Studieninteressierte zu verbessern. Sportmannschaften analysieren die Leistung ihrer Spieler und planen Spielstrategien mit Datenwissenschaft. Auch Regierungsbehörden und politische Organisationen gehören zu den Nutzergruppen.
Prozess und Lebenszyklus der Datenwissenschaft
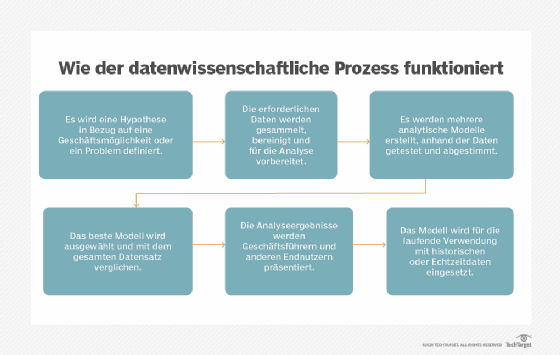
Datenwissenschaftliche Projekte umfassen eine Reihe von Schritten zur Datenerfassung und -analyse. Laut Donald Farmer, Leiter des Analyseberatungsunternehmens TreeHive Strategy, sind die folgenden sechs Schritte Teil des datenwissenschaftlichen Prozesses:
- Identifizierung geschäftsbezogener Hypothese, die getestet werden soll.
- Sammeln von Daten und deren Aufbereitung für die Analyse.
- Experimentieren mit verschiedenen Analysemodellen.
- Auswahl des besten Modells und vergleich mit den Daten.
- Präsentation der Ergebnisse vor den Führungskräften des Unternehmens.
- Einsatz des Modells für den laufende Betrieb mit neuen Daten.
Farmer sagt, dass dieser Prozess die Datenwissenschaft zu einem wissenschaftlichen Unterfangen macht. Die Arbeit der Datenwissenschaft in Unternehmen „konzentriert sich allerdings immer am sinnvollsten auf direkte kommerzielle Realitäten“, die dem Unternehmen zugutekommen können. „Aus diesem Grund sollten Datenwissenschaftler bei Projekten während des gesamten Analyselebenszyklus mit Geschäftsinteressenten zusammenarbeiten“, erklärt Farmer.
Vorteile der Datenwissenschaft
In einem Webinar, das im Oktober 2020 vom Institute for Applied Computational Science der Harvard University organisiert wurde, sagte Jessica Stauth, Managing Director für Data Science in der Abteilung Fidelity Labs bei Fidelity Investments, dass es eine „sehr klare Beziehung“ zwischen Data-Science-Arbeit und Geschäftsergebnissen gebe. Sie nannte als potenzielle Geschäftsvorteile eine höhere Kapitalrendite, Umsatzwachstum, effizientere Abläufe, kürzere Markteinführungszeiten sowie eine höhere Kundenbindung und -zufriedenheit.
Generell besteht einer der größten Vorteile der Datenwissenschaft darin, dass sie eine bessere Entscheidungsfindung erleichtert. Unternehmen, die in diese Technologie investieren, können quantifizierbare, datenbasierte Erkenntnisse in ihre Geschäftsentscheidungen einfließen lassen. Im Idealfall führen solche datengestützten Entscheidungen zu einer besseren Unternehmensleistung, Kosteneinsparungen und reibungsloseren Geschäftsprozessen und Arbeitsabläufen.
Die spezifischen geschäftlichen Vorteile der Datenwissenschaft variieren je nach Unternehmen und Branche. In Unternehmen mit Kundenkontakt hilft Datenwissenschaft beispielsweise dabei, Zielgruppen zu identifizieren und zu verfeinern. Marketing- und Vertriebsabteilungen können Kundendaten auswerten, um die Konversionsraten zu verbessern und personalisierte Marketingkampagnen und Werbeangebote zu erstellen, die zu höheren Umsätzen führen.
In anderen Fällen sind die Vorteile unter anderem: weniger Betrug, effektiveres Risikomanagement, profitablerer Finanzhandel, höhere Betriebszeit in der Fertigung, bessere Leistung der Lieferkette, besserer Schutz vor Cyberangriffen und bessere Ergebnisse für Patienten. Data Science ermöglicht auch die Analyse von Daten in Echtzeit, während diese generiert werden.
Anwendungen und Anwendungsfälle der Datenwissenschaft
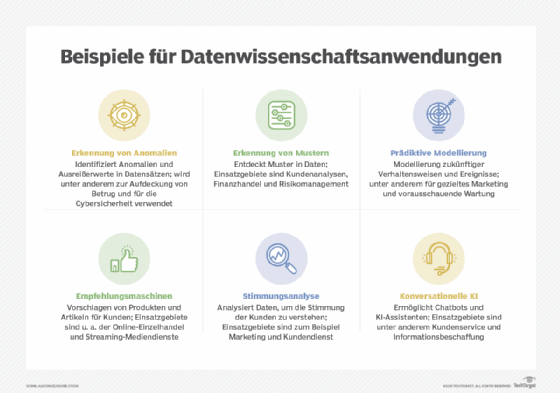
Zu den gängigen Anwendungen, mit denen sich Datenwissenschaftler beschäftigen, gehören prädiktive Modellierung, Mustererkennung, Anomalieerkennung, Klassifizierung, Kategorisierung und Stimmungsanalyse sowie die Entwicklung von Technologien wie Empfehlungsmaschinen, Personalisierungssysteme und KI-Tools (künstliche Intelligenz) wie Chatbots und autonome Fahrzeuge und Maschinen.
Diese Anwendungen führen zu einer Vielzahl von Anwendungsfällen in Unternehmen, darunter:
- Kundenanalyse
- Betrugserkennung
- Risikomanagement
- Aktienhandel
- gezielte Werbung
- Personalisierung von Websites
- Kundenbetreuung
- Vorausschauende Wartung
- Logistik und Lieferkettenmanagement
- Bilderkennung
- Spracherkennung
- Verarbeitung natürlicher Sprache
- Cybersicherheit
- medizinische Diagnose
Herausforderungen der Datenwissenschaft
Datenwissenschaft ist von Natur aus eine Herausforderung, da es sich dabei um fortschrittliche Analysen handelt. Die riesigen Datenmengen, die in der Regel analysiert werden, erhöhen die Komplexität und die Zeit, die für die Durchführung von Projekten benötigt wird. Darüber hinaus arbeiten Datenwissenschaftler häufig mit großen Datenmengen, die eine Vielzahl von strukturierten, unstrukturierten und halbstrukturierten Daten enthalten können, was den Analyseprozess zusätzlich erschwert.

Eine der größten Herausforderungen ist die Beseitigung von Verzerrungen in Datensätzen und Analyseanwendungen. Dazu gehören Probleme mit den zugrunde liegenden Daten selbst und solche, die Datenwissenschaftler unbewusst in Algorithmen und Vorhersagemodelle einbauen. Solche Verzerrungen können die Analyseergebnisse verfälschen, wenn sie nicht erkannt und behoben werden, und zu fehlerhaften Ergebnissen führen, die wiederum falsche Geschäftsentscheidungen nach sich ziehen. Schlimmer noch, sie können sich schädlich auf bestimmte Personengruppen auswirken, wie zum Beispiel bei rassistischen Vorurteilen in KI-Systemen.
Eine weitere Herausforderung besteht darin, die richtigen Daten für die Analyse zu finden. In einem im Januar 2020 veröffentlichten Bericht nannten der Gartner-Analyst Afraz Jaffri und vier seiner Kollegen vom Beratungsunternehmen auch die Auswahl der richtigen Tools, die Verwaltung der Bereitstellung von Analysemodellen, die Quantifizierung des Geschäftswerts und die Wartung der Modelle als bedeutende Hürden.
Was machen Datenwissenschaftler und welche Fähigkeiten benötigen sie?
Die Hauptaufgabe von Datenwissenschaftlern besteht in der Analyse von Daten, oft in großen Mengen, um nützliche Informationen zu finden, die an Führungskräfte, Manager und Mitarbeiter von Unternehmen, aber auch an Regierungsbeamte, Ärzte, Forscher und viele andere weitergegeben werden können. Datenwissenschaftler entwickeln auch KI-Tools und -Technologien für den Einsatz in verschiedenen Anwendungen. In beiden Fällen sammeln sie Daten, entwickeln Analysemodelle und trainieren, testen und führen die Modelle anhand der Daten aus.
Daher müssen Datenwissenschaftler über eine Kombination aus Datenaufbereitung, Data Mining, prädiktiver Modellierung, maschinellem Lernen, statistischer Analyse und Mathematik sowie über Erfahrung mit Algorithmen und Kodierung verfügen – zum Beispiel Programmierkenntnisse in Sprachen wie Python, R und SQL. Viele sind auch mit der Erstellung von Datenvisualisierungen, Dashboards und Berichten zur Veranschaulichung der Analyseergebnisse betraut.

Neben diesen technischen Fähigkeiten benötigen Datenwissenschaftler auch eine Reihe von Soft Skills, darunter Geschäftskenntnisse, Neugier und kritisches Denken. Eine weitere wichtige Fähigkeit ist, dass sie Datenerkenntnisse präsentieren und ihre Bedeutung so erklären, dass sie für Geschäftsanwender leicht zu verstehen sind. Dazu gehört auch die Fähigkeit, Datenvisualisierungen und erzählenden Text in einer vorbereiteten Präsentation zu kombinieren.
Datenwissenschaftliches Team
Viele Unternehmen haben ein separates Team oder mehrere Teams eingerichtet, die sich mit Data-Science-Aktivitäten befassen. Diese Teams umfassen zum Teil folgende Positionen:
- Dateningenieur. Zu seinen Aufgaben gehören die Einrichtung von Datenpipelines und die Unterstützung bei der Datenaufbereitung und Modellbereitstellung, wobei er eng mit Datenwissenschaftlern zusammenarbeitet.
- Datenanalyst. Dies ist eine niedrigere Position für Analytiker, die nicht über das Erfahrungsniveau oder die fortgeschrittenen Fähigkeiten von Datenwissenschaftlern verfügen.
- Ingenieur für maschinelles Lernen. Diese programmierorientierte Tätigkeit umfasst die Entwicklung von Modellen für maschinelles Lernen, die für datenwissenschaftliche Anwendungen benötigt werden.
- Entwickler für Datenvisualisierung. Diese Person arbeitet mit Datenwissenschaftlern zusammen, um Visualisierungen und Dashboards zu erstellen, die zur Präsentation von Analyseergebnissen für Geschäftsanwender verwendet werden.
- Datenübersetzer. Auch Analytikübersetzer genannt, ist dies eine aufstrebende Rolle, die als Bindeglied zu den Geschäftsbereichen dient und dabei hilft, Projekte zu planen und Ergebnisse zu kommunizieren.
- Datenarchitekt. Ein Datenarchitekt entwirft und überwacht die Implementierung der zugrunde liegenden Systeme, die zur Speicherung und Verwaltung von Daten für Analysezwecke verwendet werden.
Das Team wird in der Regel von einem Director of Data Science, Data Science Manager oder Lead Data Scientist geleitet, der entweder dem Chief Data Officer, Chief Analytics Officer oder Vice President of Analytics unterstellt ist; der Chief Data Scientist ist eine weitere Managementposition, die in einigen Unternehmen entstanden ist. Einige Data-Science-Teams sind auf Unternehmensebene zentralisiert, während andere dezentral in einzelnen Geschäftsbereichen tätig sind oder eine hybride Struktur haben, die diese beiden Ansätze kombiniert.
Business Intelligence versus Datenwissenschaft
Wie Data Science zielen auch Business Intelligence und Reporting darauf ab, die operative Entscheidungsfindung und strategische Planung zu unterstützen. BI konzentriert sich jedoch in erster Linie auf deskriptive Analysen: Was ist passiert oder geschieht gerade, worauf ein Unternehmen reagieren oder sich damit befassen sollte? BI-Analysten und Self-Service-BI-Nutzer arbeiten meist mit strukturierten Transaktionsdaten, die aus operativen Systemen extrahiert, bereinigt und umgewandelt werden, um sie konsistent zu machen, und dann zur Analyse in ein Data Warehouse oder einen Data Mart geladen werden. Die Überwachung von Unternehmensleistung, Prozessen und Trends ist ein häufiger BI-Anwendungsfall.
Data Science umfasst fortgeschrittenere Analyseanwendungen. Neben der deskriptiven Analyse umfasst sie auch die prädiktive Analyse, die zukünftige Verhaltensweisen und Ereignisse vorhersagt, sowie die präskriptive Analyse, die darauf abzielt, die beste Vorgehensweise für das analysierte Problem zu bestimmen.
Unstrukturierte oder halbstrukturierte Datentypen, zum Beispiel Protokolldateien, Sensordaten und Text, sind bei Data-Science-Anwendungen ebenso üblich wie strukturierte Daten. Außerdem möchten Datenwissenschaftler oft auf Rohdaten zugreifen, bevor diese bereinigt und konsolidiert wurden, um den gesamten Datensatz zu analysieren oder ihn für bestimmte Analysezwecke zu filtern und vorzubereiten. Infolgedessen können die Rohdaten in einem auf Hadoop basierenden Data Lake, einem Cloud-Objektspeicherdienst, einer NoSQL-Datenbank oder einer anderen Big-Data-Plattform gespeichert werden.
Technologien, Techniken und Methoden der Datenwissenschaft
Datenwissenschaft stützt sich stark auf Algorithmen des maschinellen Lernens. Maschinelles Lernen ist eine Form der fortgeschrittenen Analytik, bei der Algorithmen über Datensätze lernen und dann nach Mustern, Anomalien oder Erkenntnissen in ihnen suchen. Dabei wird eine Kombination aus überwachten, nicht überwachten, halbüberwachten und verstärkenden Lernmethoden verwendet, wobei die Algorithmen in unterschiedlichem Maße von Datenwissenschaftlern geschult und beaufsichtigt werden.
Es gibt auch Deep Learning, einen fortgeschritteneren Ableger des maschinellen Lernens, bei dem in erster Linie künstliche neuronale Netze zur Analyse großer Mengen ungelabelter Daten eingesetzt werden.
Vorhersagemodelle sind eine weitere Kerntechnologie der Datenwissenschaft. Datenwissenschaftler erstellen sie, indem sie maschinelles Lernen, Data Mining oder statistische Algorithmen auf Datensätze anwenden, um Geschäftsszenarien und wahrscheinliche Ergebnisse oder Verhaltensweisen vorherzusagen. Bei der prädiktiven Modellierung und anderen fortgeschrittenen Analyseanwendungen werden häufig Datenstichproben gezogen, um eine repräsentative Teilmenge von Daten zu analysieren. Dies ist eine Data-Mining-Technik, die den Analyseprozess überschaubarer und weniger zeitaufwändig machen soll.
Zu den gängigen statistischen und analytischen Techniken, die in Data-Science-Projekten zum Einsatz kommen, gehören:
- Klassifizierung, bei der die Elemente eines Datensatzes in verschiedene Kategorien eingeteilt werden;
- Regression, bei der die optimalen Werte verwandter Datenvariablen in einer Linie oder Ebene dargestellt werden, und
- Clustering, bei dem Datenpunkte mit einer Affinität oder gemeinsamen Attributen gruppiert werden.

Tools und Plattformen für die Datenwissenschaft
Für Datenwissenschaftler stehen zahlreiche Tools für den Analyseprozess zur Verfügung, darunter sowohl kommerzielle als auch Open-Source-Optionen:
- Datenplattformen und Analysemaschinen, wie Apache Spark, Hadoop und NoSQL-Datenbanken;
- Programmiersprachen, wie Python, R, Julia, Scala und SQL;
- statistische Analysewerkzeuge wie SAS und IBM SPSS;
- Plattformen und Bibliotheken für maschinelles Lernen, darunter TensorFlow, Weka, Scikit-learn, Keras und PyTorch;
- Jupyter Notebook, eine Webanwendung zur gemeinsamen Nutzung von Dokumenten mit Code, Gleichungen und anderen Informationen; und
- Datenvisualisierungs-Tools und -bibliotheken, wie Tableau, D3.js und Matplotlib.
Darüber hinaus bieten Softwareanbieter eine Reihe von Data-Science-Plattformen mit unterschiedlichen Merkmalen und Funktionen an. Dazu gehören Analyseplattformen für erfahrene Datenwissenschaftler, automatisierte Plattformen für maschinelles Lernen, die auch von Laien verwendet werden können, sowie Workflow- und Kollaborationsanwendungen für Datenwissenschaftsteams.
Die Liste der Anbieter umfasst Alteryx, AWS, Databricks, Dataiku, DataRobot, Domino Data Lab, Google, H2O.ai, IBM, Knime, MathWorks, Microsoft, RapidMiner, SAS Institute, Tibco Software und andere.
Karrieren in der Datenwissenschaft
Mit der zunehmenden Menge an Daten, die von Unternehmen erzeugt und gesammelt werden, steigt auch der Bedarf an Datenwissenschaftlern. Dies hat zu einer hohen Nachfrage nach Arbeitskräften mit Erfahrung oder Ausbildung in den Datenwissenschaften geführt, was es für einige Unternehmen schwierig macht, verfügbare Stellen zu besetzen.
In einer Umfrage, die 2020 von der Google-Tochter Kaggle durchgeführt wurde, die eine Online-Community für Datenwissenschaftler betreibt, gaben 51 Prozent der 2.675 Befragten, die als Datenwissenschaftler beschäftigt sind, an, dass sie über einen Master-Abschluss verfügen, während 24 Prozent einen Bachelor-Abschluss und 17 Prozent einen Doktortitel haben. Viele Universitäten bieten inzwischen Bachelor- und Master-Studiengänge im Bereich Datenwissenschaft an, die einen direkten Einstieg in das Berufsleben ermöglichen können.
Ein alternativer Karriereweg besteht darin, dass Personen, die in anderen Funktionen tätig sind, zu Datenwissenschaftlern umgeschult werden – eine beliebte Option für Unternehmen, die Schwierigkeiten haben, erfahrene Mitarbeiter zu finden. Neben akademischen Programmen können angehende Data Scientists an Data Science Bootcamps und Online-Kursen auf Bildungswebsites wie Coursera und Udemy teilnehmen. Verschiedene Anbieter und Branchengruppen bieten auch Kurse und Zertifizierungen für Datenwissenschaftler an, und Online-Quizze für Datenwissenschaftler können grundlegende Kenntnisse testen und vermitteln.
Wie Branchen auf Datenwissenschaft setzen
Bevor sie selbst zu Technologieanbietern wurden, waren Google und Amazon frühe Nutzer von Datenwissenschaft und Big-Data-Analysen für interne Anwendungen, ebenso wie andere Internet- und E-Commerce-Unternehmen wie Facebook, Yahoo und eBay. Heute ist Data Science in Unternehmen aller Art weit verbreitet. Im Folgenden finden Sie einige Beispiele für den Einsatz in verschiedenen Branchen:
- Unterhaltung. Mit Datenwissenschaft können Streaming-Dienste verfolgen und analysieren, was die Nutzer sehen, und so die neuen Fernsehsendungen und Filme bestimmen, die sie produzieren. Datengesteuerte Algorithmen werden auch verwendet, um personalisierte Empfehlungen auf der Grundlage der Sehgewohnheiten der Nutzer zu erstellen.
- Finanzdienstleistungen. Banken und Kreditkartenunternehmen werten Daten aus und analysieren sie, um betrügerische Transaktionen zu erkennen, finanzielle Risiken bei Darlehen und Kreditlinien zu verwalten und Kundenportfolios zu bewerten, um Upselling-Möglichkeiten zu erkennen.
- Gesundheitswesen. Krankenhäuser und andere Gesundheitsdienstleister nutzen Modelle des maschinellen Lernens und zusätzliche Datenwissenschaftkomponenten, um die Röntgenanalyse zu automatisieren und Ärzte bei der Diagnose von Krankheiten und der Planung von Behandlungen auf der Grundlage früherer Patientenergebnisse zu unterstützen.
- Fertigung. Zu den Einsatzmöglichkeiten der Datenwissenschaft bei Herstellern gehören die Optimierung des Lieferkettenmanagements und des Vertriebs sowie die vorausschauende Wartung, um potenzielle Geräteausfälle in Anlagen zu erkennen, bevor sie auftreten.
- Einzelhandel. Einzelhändler analysieren das Kundenverhalten und die Kaufmuster, um personalisierte Produktempfehlungen und gezielte Werbung, Marketing und Verkaufsförderungsmaßnahmen zu entwickeln. Datenwissenschaft hilft ihnen auch bei der Verwaltung von Produktbeständen und ihrer Lieferketten, um Artikel auf Lager zu halten.
- Transportwesen. Lieferunternehmen, Spediteure und Logistikdienstleister nutzen Datenwissenschaft zur Optimierung von Lieferrouten und -plänen sowie der besten Transportmittel für Sendungen.
- Reisen. Datenwissenschaft unterstützt Fluggesellschaften bei der Flugplanung, um Routen, Crew-Einsatz und Passagierzahlen zu optimieren. Algorithmen steuern auch die variable Preisgestaltung für Flüge und Hotelzimmer.
Andere Anwendungen der Datenwissenschaft, etwa in den Bereichen Cybersicherheit, Kundendienst und Geschäftsprozessmanagement, sind in verschiedenen Branchen üblich. Ein Beispiel für letzteres ist die Unterstützung bei der Einstellung von Mitarbeitern und der Gewinnung von Talenten: Mit Analysen können gemeinsame Merkmale von Leistungsträgern ermittelt, die Effektivität von Stellenausschreibungen gemessen und weitere Informationen für den Einstellungsprozess bereitgestellt werden.
Geschichte der Datenwissenschaft
In einem 1962 veröffentlichten Aufsatz schrieb der amerikanische Statistiker John W. Tukey, dass die Datenanalyse an sich eine empirische Wissenschaft ist. Vier Jahre später schlug Peter Naur, ein dänischer Pionier der Softwareprogrammierung, die Datenwissenschaft – die Wissenschaft von Daten und Datenprozessen – als Alternative zur Informatik vor. Später verwendete er den Begriff Datenwissenschaft in seinem 1974 erschienenen Buch Concise Survey of Computer Methods, in dem er sie als „die Wissenschaft vom Umgang mit Daten“ bezeichnete – allerdings wiederum im Kontext der Informatik, nicht der Analytik.
Im Jahr 1996 nahm die International Federation of Classification Societies den Begriff Data Science in den Namen der Konferenz auf, die sie in diesem Jahr veranstaltete. In einem Vortrag auf der Veranstaltung erklärte der japanische Statistiker Chikio Hayashi, dass Datenwissenschaft drei Phasen umfasst: Design für Daten, Sammlung von Daten und Analyse von Daten. Ein Jahr später schlug C. F. Jeff Wu, ein in Taiwan geborener Universitätsprofessor in den USA, vor, die Statistik in Datenwissenschaft umzubenennen und die Statistiker als Datenwissenschaftler zu bezeichnen.
Der amerikanische Informatiker William S. Cleveland hat 2001 in einem Artikel mit dem Titel Data Science: An Action Plan for Expanding the Technical Areas of Statistics die Datenwissenschaft als umfassende analytische Disziplin beschrieben. In den folgenden zwei Jahren wurden zwei Forschungszeitschriften mit dem Schwerpunkt Datenwissenschaft gegründet.
Die erste Verwendung des Begriffs Data Scientist als Berufsbezeichnung wird DJ Patil und Jeff Hammerbacher zugeschrieben, die 2008 bei LinkedIn beziehungsweise Facebook gemeinsam beschlossen, diese Bezeichnung zu übernehmen. Im Jahr 2012 bezeichnete ein Artikel in der Harvard Business Review, der von Patil und dem amerikanischen Wissenschaftler Thomas Davenport verfasst wurde, den Datenwissenschaftler als den sexiesten Job des 21. Jahrhunderts. Seitdem hat die Datenwissenschaft weiter an Bedeutung gewonnen, was zum Teil auf den verstärkten Einsatz von KI und maschinellem Lernen in Unternehmen zurückzuführen ist.
Die Zukunft der Datenwissenschaft
Mit der zunehmenden Verbreitung der Datenwissenschaft in Unternehmen wird erwartet, dass Citizen Data Scientists eine größere Rolle im Analyseprozess übernehmen werden. In seinem Bericht über den Magic Quadrant 2020 für Data-Science- und Machine-Learning-Plattformen stellt Gartner fest, dass die Notwendigkeit, eine breite Palette von Data-Science-Nutzern zu unterstützen, zunehmend zur Norm wird. Ein wahrscheinliches Ergebnis ist die verstärkte Nutzung von automatisiertem maschinellem Lernen, auch durch erfahrene Datenwissenschaftler, die ihre Arbeit rationalisieren und beschleunigen möchten.
Gartner erwähnte auch das Aufkommen von Machine Learning Operations (MLOps), einem Konzept, das DevOps-Praktiken aus der Softwareentwicklung adaptiert, um die Entwicklung, Bereitstellung und Wartung von Machine-Learning-Modellen besser zu verwalten. MLOps-Methoden und -Tools zielen darauf ab, standardisierte Arbeitsabläufe zu schaffen, damit Modelle effizienter geplant, erstellt und in Produktion gebracht werden können.
Weitere Trends, die sich auf die Arbeit von Datenwissenschaftlern auswirken werden, sind der zunehmende Druck auf erklärbare KI, die Informationen bereitstellt, die den Menschen helfen, zu verstehen, wie KI und maschinelle Lernmodelle funktionieren und inwieweit man ihren Ergebnissen bei der Entscheidungsfindung vertrauen kann, sowie ein damit verbundener Fokus auf verantwortungsvolle KI-Prinzipien, die sicherstellen sollen, dass KI-Technologien fair, unvoreingenommen und transparent sind.







