Datenstruktur
Was ist eine Datenstruktur?
Eine Datenstruktur ist ein spezielles Format zum Organisieren, Verarbeiten, Abrufen und Speichern von Daten. Es gibt verschiedene grundlegende und fortgeschrittene Arten von Datenstrukturen, die alle dazu dienen, Daten für einen bestimmten Zweck anzuordnen. Datenstrukturen erleichtern Benutzern den Zugriff auf die benötigten Daten und die Arbeit mit diesen. Am wichtigsten ist jedoch, dass Datenstrukturen die Organisation von Informationen so gestalten, dass Maschinen und Menschen sie besser verstehen können.
In der Informatik und der Computerprogrammierung kann eine Datenstruktur ausgewählt oder entworfen werden, um Daten für die Verwendung mit verschiedenen Algorithmen zu speichern – allgemein als Datenstrukturen und Algorithmen (DSA) bezeichnet. In einigen Fällen sind die grundlegenden Operationen des Algorithmus eng mit dem Entwurf der Datenstruktur verbunden. Jede Datenstruktur enthält Informationen über die Datenwerte, die Beziehungen zwischen den Daten und in einigen Fällen Funktionen, die auf die Daten angewendet werden können.
In einer objektorientierten Programmiersprache sind beispielsweise die Datenstruktur und die damit verbundenen Methoden als Teil einer Klassendefinition miteinander verbunden. In nicht objektorientierten Sprachen können Funktionen definiert sein, die mit der Datenstruktur arbeiten, aber sie sind technisch gesehen nicht Teil der Datenstruktur.
Warum sind Datenstrukturen wichtig?
Typische Basisdatentypen wie Ganzzahlen oder Gleitkommawerte, die in den meisten Programmiersprachen verfügbar sind, reichen im Allgemeinen nicht aus, um die logische Absicht der Datenverarbeitung und -nutzung zu erfassen. Anwendungen, die Informationen aufnehmen, bearbeiten und produzieren, müssen jedoch verstehen, wie Daten organisiert werden sollten, um die Verarbeitung zu vereinfachen. Datenstrukturen führen die Datenelemente auf logische Weise zusammen und erleichtern die effektive Nutzung, Persistenz und gemeinsame Nutzung von Daten. Sie bieten ein formales Modell, das die Art und Weise beschreibt, wie die Datenelemente organisiert sind.
Datenstrukturen sind die Bausteine für anspruchsvollere Anwendungen. Sie werden durch die Zusammensetzung von Datenelementen zu einer logischen Einheit erstellt, die einen abstrakten Datentyp darstellt, der für den Algorithmus oder die Anwendung relevant ist. Ein Beispiel für einen abstrakten Datentyp ist ein Kundenname, der aus den Zeichenketten für Vorname, zweiter Vorname und Nachname besteht.
Es ist nicht nur wichtig, Datenstrukturen zu verwenden, sondern auch, für jede Aufgabe die richtige Datenstruktur auszuwählen. Die Wahl einer ungeeigneten Datenstruktur kann zu langsamen Laufzeiten oder nicht reagierendem Code führen.
Bei der Auswahl einer Datenstruktur sind fünf Faktoren zu berücksichtigen:
- Welche Art von Informationen soll gespeichert werden?
- Wie werden diese Informationen verwendet?
- Wo sollen Daten nach ihrer Erstellung gespeichert oder aufbewahrt werden?
- Wie lassen sich die Daten am besten organisieren?
- Welche Aspekte der Arbeitsspeicher- und Storage-Reservierungsverwaltung sollten berücksichtigt werden?
Wie werden Datenstrukturen verwendet?
Im Allgemeinen werden Datenstrukturen verwendet, um die physischen Formen abstrakter Datentypen zu implementieren. Datenstrukturen sind ein entscheidender Bestandteil bei der Entwicklung effizienter Software. Sie spielen auch eine entscheidende Rolle bei der Entwicklung von Algorithmen und der Art und Weise, wie diese Algorithmen in Computerprogrammen verwendet werden.
In frühen Programmiersprachen wie Fortran, C und C++ konnten Programmierer ihre eigenen Datenstrukturen definieren. Heute enthalten viele Programmiersprachen eine umfangreiche Sammlung integrierter Datenstrukturen, um Code und Informationen zu organisieren. Beispielsweise sind Python-Listen und -Wörterbücher sowie JavaScript-Arrays und -Objekte gängige Codierungsstrukturen, die zum Speichern und Abrufen von Informationen verwendet werden.
Softwareentwickler verwenden Algorithmen, die eng mit den Datenstrukturen verbunden sind, wie zum Beispiel Listen, Warteschlangen und Zuordnungen von einem Wertesatz zu einem anderen. Dieser Ansatz kann in einer Vielzahl von Anwendungen eingesetzt werden, zum Beisopiel bei der Verwaltung von Datensammlungen in einer relationalen Datenbank und der Erstellung eines Index dieser Datensätze mithilfe einer Datenstruktur, die als Binärbaum bezeichnet wird.
Beispiele für die Verwendung von Datenstrukturen sind:
- Speichern von Daten. Datenstrukturen werden für eine effiziente Datenpersistenz verwendet, zum Beispiel für die Angabe der Sammlung von Attributen und entsprechenden Strukturen, die zum Speichern von Datensätzen in einem Datenbankmanagementsystem verwendet werden.
- Verwalten von Ressourcen und Diensten. Kernressourcen und -dienste des Betriebssystems werden mithilfe von Datenstrukturen wie verknüpften Listen für die Speicherzuweisung, Dateiverzeichnisverwaltung und Dateistrukturbäumen sowie Prozessplanungswarteschlangen aktiviert.
- Datenaustausch. Datenstrukturen definieren die Organisation von Informationen, die zwischen Anwendungen ausgetauscht werden, zum Beispiel TCP/IP-Pakete.
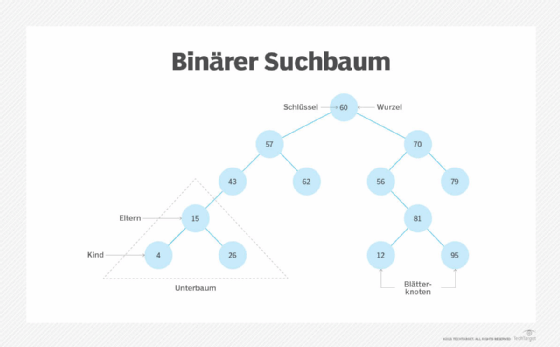
- Ordnen und Sortieren. Datenstrukturen wie binäre Suchbäume – auch als geordnete oder sortierte binäre Bäume bekannt – bieten effiziente Methoden zum Sortieren von Objekten, wie zum Beispiel Zeichenketten, die als Tags verwendet werden. Mit Datenstrukturen wie Vorrangwarteschlangen können Programmierer Elemente verwalten, die nach einer bestimmten Priorität organisiert sind.
- Indizierung. Noch ausgefeiltere Datenstrukturen wie B-Bäume werden zur Indizierung von Objekten verwendet, die zum Beispiel in einer Datenbank gespeichert sind.
- Suche. Mit Binärsuchbäumen, B-Bäumen oder Hash-Tabellen erstellte Indizes beschleunigen das Auffinden eines bestimmten gesuchten Elements.
- Skalierbarkeit. Big-Data-Anwendungen verwenden Datenstrukturen für die Zuweisung und Verwaltung von Datenspeichern an verteilten Speicherorten, um Skalierbarkeit und Leistung sicherzustellen. Bestimmte Big-Data-Programmierumgebungen – wie Apache Spark – bieten Datenstrukturen, die die zugrunde liegende Struktur von Datenbankeinträgen widerspiegeln, um die Abfrage zu vereinfachen.
Merkmale von Datenstrukturen
Datenstrukturen werden häufig nach ihren Merkmalen klassifiziert:
- Linear oder nichtlinear. Dies beschreibt, ob die Datenelemente in einer sequenziellen Reihenfolge angeordnet sind, wie zum Beispiel bei einem Array, oder in einer ungeordneten Reihenfolge, wie zum Beispiel bei einem Diagramm.
- Homogen oder heterogen. Dies beschreibt, ob alle Datenelemente in einem bestimmten Repository vom gleichen Typ sind. Ein Beispiel ist eine Sammlung von Elementen in einem Array oder von verschiedenen Typen, wie zum Beispiel ein abstrakter Datentyp, der als Struktur in C definiert ist, oder eine Klassenspezifikation in Java.
- Statisch und dynamisch. Dies beschreibt, wie die Datenstrukturen kompiliert werden. Statische Datenstrukturen haben feste Größen, Strukturen und Speicherorte zum Zeitpunkt der Kompilierung. Dynamische Datenstrukturen haben Größen, Strukturen und Speicherorte, die je nach Verwendung schrumpfen oder sich ausdehnen können.
Datentypen
Wenn Datenstrukturen die Bausteine von Algorithmen und Computerprogrammen sind, sind die primitiven oder Basisdatentypen die Bausteine von Datenstrukturen. Zu den typischen Basisdatentypen gehören:
- Boolean speichert logische Werte, die entweder wahr oder falsch sind.
- Integer speichert einen Bereich mathematischer Ganzzahlen oder Zählzahlen. Ganzzahlen unterschiedlicher Größe enthalten einen unterschiedlichen Wertebereich. Eine vorzeichenbehaftete 8-Bit-Ganzzahl enthält Werte von -128 bis 127, und eine vorzeichenlose 32-Bit-Ganzzahl enthält Werte von 0 bis 4.294.967.295.
- Gleitkommazahlen speichern eine formelhafte Darstellung reeller Zahlen.
- Festkommazahlen werden in einigen Programmiersprachen verwendet und enthalten reelle Werte, werden jedoch als Ziffern links und rechts vom Dezimalpunkt verwaltet.
- Zeichen verwenden Symbole aus einer definierten Zuordnung von Ganzzahlwerten zu Symbolen.
- Zeiger sind Referenzwerte, die auf andere Werte verweisen.
- Ein String ist eine Reihe von Zeichen, die von einem Stoppcode – normalerweise dem Wert 0 – gefolgt werden, oder wird mithilfe eines Längenfelds verwaltet, das ein ganzzahliger Wert ist.
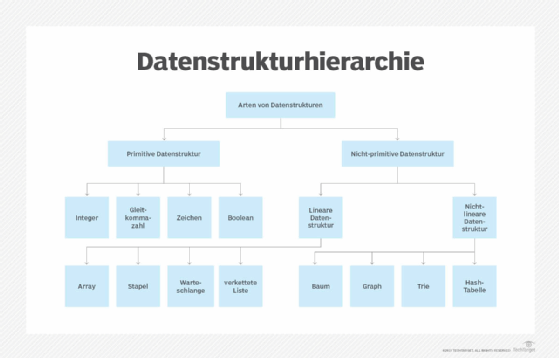
Arten von Datenstrukturen
Der in einer bestimmten Situation verwendete Datenstrukturtyp wird durch die Art der erforderlichen Operationen oder die Art der anzuwendenden Algorithmen bestimmt. Zu den verschiedenen gängigen Datenstrukturen gehören die folgenden:
- Array. Ein Array speichert eine Sammlung von Elementen an angrenzenden Speicherorten. Elemente desselben Typs werden zusammen gespeichert, sodass die Position jedes Elements einfach über einen Index berechnet oder abgerufen werden kann. Arrays können eine feste oder flexible Länge haben.
- Stack. Ein Stack speichert eine Sammlung von Elementen in der linearen Reihenfolge, in der die Operationen angewendet werden. Diese Reihenfolge kann Last In, First Out (LIFO) oder First In, First Out (FIFO) sein.
- Warteschlange. Eine Warteschlange speichert eine Sammlung von Elementen wie ein Stapel. Die Betriebsreihenfolge kann jedoch nur FIFO sein.
- Verknüpfte Liste. Eine verkettete Liste speichert eine Sammlung von Elementen in einer linearen Reihenfolge. Jedes Element oder jeder Knoten in einer verknüpften Liste enthält ein Datenelement sowie einen Verweis oder eine Verknüpfung zum nächsten Element in der Liste.
- Baum. Ein Baum speichert eine Sammlung von Elementen auf abstrakte, hierarchische Weise. Jeder Knoten ist mit einem Schlüsselwert verknüpft, wobei übergeordnete Knoten mit untergeordneten Knoten oder Unterknoten verknüpft sind. Es gibt einen Wurzelknoten, der der Vorfahre aller Knoten im Baum ist. Das Durchlaufen einer solchen Baumstruktur vom Wurzelknoten aus, um auf alle nachfolgenden Knoten zuzugreifen, wird als Traversierung bezeichnet und kann in einer Vielzahl von Reihenfolgen erfolgen, von denen einige die Leistung des Baum-DSA beeinflussen können.
- Heap. Ein Heap ist eine baumartige Struktur, in der der Schlüsselwert jedes Elternknotens größer oder gleich den Schlüsselwerten seiner Kinderknoten ist.
- Graph. Ein Graph speichert eine Sammlung von Elementen auf nichtlineare Weise. Graphen bestehen aus einer endlichen Menge von Knoten, auch als Knoten bezeichnet, und Linien, die sie verbinden, auch als Kanten bezeichnet. Diese sind nützlich für die Darstellung realer Systeme wie Computernetzwerke.
- Trie. Ein Trie, auch als Schlüsselwortbaum bekannt, ist eine Datenstruktur, die Zeichenketten als Datenelemente speichert, die in einem visuellen Diagramm organisiert werden können.
- Hash-Tabelle. Eine Hash-Tabelle – auch als Hash-Map bekannt – speichert eine Sammlung von Elementen in einem assoziativen Array, das Schlüssel zu Werten darstellt. Eine Hash-Tabelle verwendet eine Hash-Funktion, um einen Index in ein Array von Buckets umzuwandeln, die das gewünschte Datenelement enthalten. Hashing bringt eine eigene Komplexität mit sich, die zu einer Kollision führt – zwei Schlüssel, die zum gleichen Wert führen, wobei ein neuer Schlüssel einem bereits belegten Speicherort in der Tabelle zugeordnet wird. Durch Verkettung wird dies behoben, indem eine lokale verknüpfte Liste generiert wird, um jedes der gehashten Elemente an derselben Stelle zu speichern.
Diese werden als komplexe Datenstrukturen betrachtet, da sie große Mengen miteinander verbundener Daten speichern können.
Wie man eine Datenstruktur auswählt
Bei der Auswahl einer Datenstruktur für ein Programm oder eine Anwendung sollten Entwickler ihre Antworten auf die folgenden Fragen berücksichtigen:
- Welche Funktionen und Operationen benötigt das Programm?
- Welche Rechenleistung ist akzeptabel? In Bezug auf die Geschwindigkeit ist eine Datenstruktur, deren Operationen in einer Zeit ausgeführt werden, die linear zur Anzahl der verwalteten Elemente ist – in der Notation O(n) – schneller als eine Datenstruktur, deren Operationen in einer Zeit ausgeführt werden, die proportional zum Quadrat der Anzahl der verwalteten Elemente ist – O(n2).
- Wie lange braucht ein Algorithmus, um Daten innerhalb einer Struktur zu verarbeiten (das heißt wie lange braucht ein Programm, um eine bestimmte Eingabe zu verarbeiten)? Die Zeitkomplexität ist oft ein Faktor bei der Auswahl von Strukturen, die für Anwendungen des maschinellen Lernens geeignet sind.
- Ist die Organisation der Datenstruktur und ihrer funktionalen Schnittstelle einfach zu bedienen?
- Ist das Löschen von Daten, die in einer Datenstruktur gespeichert sind, unkompliziert? Es gibt Fälle, in denen auch dies komplex sein kann. In verketteten Listen können Elemente beispielsweise durch Löschen eines Schlüssels oder durch Löschen eines Schlüssels an einer bestimmten Position gelöscht werden.
- Wie einfach ist es, die Datenstruktur zu visualisieren? Dies kann ein wichtiges Kriterium bei der Auswahl sein, da die grafische Darstellung von Daten im Allgemeinen nützlich ist, um die Problemlösung in der Praxis zu verstehen.
Einige Beispiele aus der Praxis sind:
- Verkettete Listen sind am besten geeignet, wenn ein Programm eine Sammlung von Elementen verwaltet, die nicht geordnet werden müssen, wenn für das Hinzufügen oder Entfernen eines Elements aus der Sammlung eine konstante Zeit erforderlich ist und wenn eine längere Suchzeit akzeptabel ist.
- Stapel sind am besten geeignet, wenn das Programm eine Sammlung verwaltet, die eine LIFO-Reihenfolge unterstützen muss.
- Warteschlangen sollten verwendet werden, wenn das Programm eine Sammlung verwaltet, die eine FIFO-Reihenfolge unterstützen muss.
- Binäre Bäume eignen sich gut für die Verwaltung einer Sammlung von Elementen mit einer Eltern-Kind-Beziehung, wie zum Beispiel ein Stammbaum.
- Binäre Suchbäume eignen sich für die Verwaltung einer sortierten Sammlung, bei der das Ziel darin besteht, die Zeit zu optimieren, die benötigt wird, um bestimmte Elemente in der Sammlung zu finden.
- Diagramme eignen sich am besten, wenn die Anwendung die Konnektivität und Beziehungen zwischen einer Sammlung von Personen in einem Social-Media-Netzwerk analysiert.






