Datenpipeline

Was ist eine Datenpipeline?
Eine Datenpipeline umfasst eine Reihe von Netzwerkverbindungs- und Verarbeitungsschritten, die Daten von einem Quellsystem an einen Zielort verschieben und sie für geplante Geschäftszwecke transformieren. Datenpipelines werden in der Regel eingerichtet, um Endanwendern Daten zur Analyse bereitzustellen, aber sie können auch Daten von einem System in ein anderes als Teil von Betriebsanwendungen übertragen.
Da immer mehr Unternehmen versuchen, Daten und Analysen in ihre Geschäftsabläufe zu integrieren, wächst auch die Rolle und Bedeutung von Datenpipelines. Organisationen können Tausende von Datenpipelines haben, die Datenbewegungen von Quellsystemen zu Zielsystemen und -anwendungen durchführen. Bei so vielen Pipelines ist es wichtig, sie so weit wie möglich zu vereinfachen, um die Komplexität der Verwaltung zu reduzieren.
Um Datenpipelines effektiv zu unterstützen, benötigen Organisationen die folgenden Komponenten:
- Eine GUI-basierte Spezifikations- und Entwicklungsumgebung, die zur Definition, Erstellung und zum Testen von Datenpipelines verwendet werden kann und über Versionskontrollfunktionen zur Pflege einer Pipeline-Bibliothek verfügt.
- Eine Anwendung zur Überwachung von Datenpipelines, die Benutzern bei der Überwachung, Verwaltung und Fehlerbehebung von Pipelines hilft.
- Datenpipeline-Entwicklungs-, Wartungs- und Verwaltungsprozesse, die Pipelines als spezialisierte Software-Assets behandeln.
Was ist der Zweck einer Datenpipeline?
Die Datenpipeline ist ein Schlüsselelement im gesamten Datenverwaltungsprozess. Ihr Zweck besteht darin, sich wiederholende Datenflüsse und die damit verbundenen Aufgaben der Datenerfassung, -transformation und -integration zu automatisieren und zu skalieren. Eine ordnungsgemäß aufgebaute Datenpipeline kann die Verarbeitung beschleunigen, die erforderlich ist, wenn Daten gesammelt, bereinigt, gefiltert, angereichert und an nachgelagerte Systeme und Anwendungen weitergeleitet werden.
Gut konzipierte Pipelines ermöglichen es Organisationen auch, Big-Data-Ressourcen zu nutzen, die oft große Mengen strukturierter, unstrukturierter und halbstrukturierter Daten enthalten. In vielen Fällen handelt es sich dabei um Echtzeitdaten, die fortlaufend generiert und aktualisiert werden. Da das Volumen, die Vielfalt und die Geschwindigkeit von Daten in Big-Data-Systemen weiter zunehmen, wird der Bedarf an linear skalierbaren Datenpipelines – ob in lokalen, Cloud- oder Hybrid-Cloud-Umgebungen – für Analyseinitiativen und Geschäftsabläufe immer wichtiger.
Wer braucht eine Datenpipeline?
Eine Datenpipeline wird für jede Analyseanwendung oder jeden Geschäftsprozess benötigt, der eine regelmäßige Aggregation, Bereinigung, Umwandlung und Verteilung von Daten an nachgelagerte Datenkonsumenten erfordert. Zu den typischen Nutzern von Datenpipelines gehören:
- Datenwissenschaftler und andere Mitglieder von Datenwissenschaftsteams
- Business-Intelligence-Analysten und -Entwickler
- Unternehmensanalysten
- Führungskräfte und andere leitende Angestellte
- Marketing- und Vertriebsteams
- Operative Mitarbeiter
Um Geschäftsanwendern den Zugriff auf relevante Daten zu erleichtern, können Pipelines auch dazu verwendet werden, diese in BI-Dashboards und -Berichte sowie in Betriebsüberwachungs- und Warnsysteme einzuspeisen.
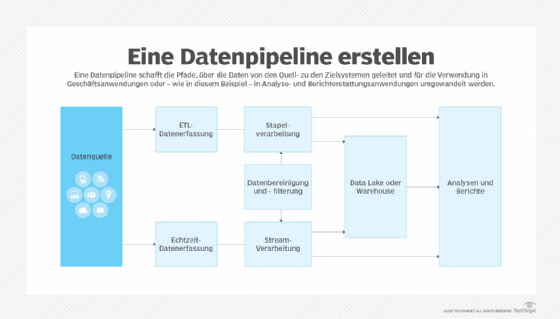
Wie funktioniert eine Datenpipeline?
Der Entwicklungsprozess einer Datenpipeline beginnt mit der Definition, welche Daten wo und wie generiert oder gesammelt werden. Dazu gehört die Erfassung von Eigenschaften des Quellsystems, wie Datenformate, Datenstrukturen, Datenschemata und Datendefinitionen – Informationen, die für die Planung und den Aufbau einer Pipeline benötigt werden. Sobald sie eingerichtet ist, umfasst die Datenpipeline in der Regel die folgenden Schritte:
- Datenerfassung. Rohdaten aus einem oder mehreren Quellsystemen werden in die Datenpipeline eingespeist. Je nach Datensatz kann die Datenerfassung im Stapel- oder Echtzeitmodus erfolgen.
- Datenintegration. Wenn mehrere Datensätze zur Verwendung in Analyse- oder Betriebsanwendungen in die Pipeline gezogen werden, müssen sie durch Datenintegrationsprozesse kombiniert werden.
- Datenbereinigung. Bei den meisten Anwendungen werden Maßnahmen zur Datenqualitätsverwaltung auf die Rohdaten in der Pipeline angewendet, um sicherzustellen, dass sie bereinigt, genau und konsistent sind.
- Datenfilterung. Datensätze werden in der Regel gefiltert, um Daten zu entfernen, die für die jeweiligen Anwendungen, für die die Pipeline erstellt wurde, nicht benötigt werden.
- Datentransformation. Die Daten werden je nach Bedarf für die geplanten Anwendungen modifiziert. Zu den Methoden der Datentransformation gehören Aggregation, Generalisierung, Reduktion und Glättung.
- Datenanreicherung. In einigen Fällen werden Datensätze im Rahmen der Pipeline durch Hinzufügen weiterer Datenelemente, die für Anwendungen erforderlich sind, ergänzt und angereichert.
- Datenvalidierung. Die endgültigen Daten werden überprüft, um sicherzustellen, dass sie gültig sind und die Anwendungsanforderungen vollständig erfüllen.
- Daten laden. Für BI- und Analyseanwendungen werden die Daten in einen Datenspeicher geladen, damit Benutzer darauf zugreifen können. In der Regel handelt es sich dabei um ein Data Warehouse, einen Data Lake oder ein Data Lakehouse, das Elemente der beiden anderen Plattformen kombiniert.
Viele Datenpipelines wenden auch maschinelles Lernen und neuronale Netzwerkalgorithmen an, um fortgeschrittenere Datentransformationen und -anreicherungen zu erstellen. Dazu gehören Segmentierung, Regressionsanalyse, Clustering und die Erstellung fortgeschrittener Indizes und Neigungsbewertungen.
Darüber hinaus können Logik und Algorithmen in eine Datenpipeline integriert werden, um die Intelligenz zu erhöhen.
Da maschinelles Lernen – und insbesondere automatisiertes maschinelles Lernen (AutoML) – immer häufiger eingesetzt wird, werden Datenpipelines wahrscheinlich immer intelligenter werden. Mit diesen Prozessen können intelligente Datenpipelines kontinuierlich lernen und sich an die Eigenschaften der Quellsysteme, die erforderlichen Datentransformationen und -anreicherungen sowie die sich entwickelnden Geschäfts- und Anwendungsanforderungen anpassen.
Welche verschiedenen Arten von Datenpipeline-Architekturen gibt es?
Dies sind die primären Betriebsmodi für eine Datenpipeline-Architektur:
- Stapelverarbeitung (Batch). Die Stapelverarbeitung in einer Datenpipeline ist am nützlichsten, wenn eine Organisation große Datenmengen in regelmäßigen Abständen verschieben möchte und eine sofortige Bereitstellung an Endbenutzer oder Geschäftsanwendungen nicht erforderlich ist. Eine Batch-Architektur kann beispielsweise nützlich sein, um Marketingdaten in einen Datenpool zu integrieren, damit sie von Datenwissenschaftlern analysiert werden können.
- Echtzeit oder Streaming. Die Echtzeit- oder Streaming-Datenverarbeitung ist nützlich, wenn Daten von einer Streaming-Quelle, wie zum Beispiel Finanzmärkten oder Geräten des Internets der Dinge (IoT), gesammelt werden. Eine für die Echtzeitverarbeitung erstellte Datenpipeline erfasst Daten aus den Quellsystemen und wandelt sie bei Bedarf schnell um, bevor sie an nachgeschaltete Benutzer oder Anwendungen gesendet werden.
- Lambda-Architektur. Diese Art von Architektur kombiniert Stapel- und Echtzeitverarbeitung in einer einzigen Datenpipeline. Obwohl sie komplizierter zu entwerfen und zu implementieren ist, kann sie in Big-Data-Umgebungen, die verschiedene Arten von Analyseanwendungen umfassen, besonders nützlich sein.
Die ereignisgesteuerte Verarbeitung kann auch in einer Datenpipeline nützlich sein, wenn ein vorher festgelegtes Ereignis im Quellsystem eintritt, das eine dringende Aktion auslöst, wie zum Beispiel eine Betrugswarnung bei einem Kreditkartenunternehmen. Wenn das vorher festgelegte Ereignis eintritt, extrahiert die Datenpipeline die erforderlichen Daten und überträgt sie an bestimmte Benutzer oder ein anderes System.
Schlüsseltechnologien für Datenpipelines
Datenpipelines erfordern in der Regel die folgenden Technologien:
- Extrahieren, Transformieren und Laden (ETL) ist der Stapelprozess, bei dem Daten aus einem oder mehreren Quellsystemen in ein Zielsystem kopiert werden. ETL-Software kann verwendet werden, um mehrere Datensätze zu integrieren und grundlegende Datentransformationen wie Filtern, Aggregieren, Stichproben und Durchschnittsberechnungen durchzuführen.
- Oft werden auch andere Arten von Datenintegrationswerkzeugen verwendet, um Daten zu extrahieren, zu konsolidieren und zu transformieren. Dazu gehören ELT-Werkzeuge (Extrahieren, Laden und Transformieren), die den zweiten und dritten Schritt des ETL-Prozesses umkehren, und Software zur Datenerfassung, die die Echtzeitintegration unterstützt. Alle diese Integrationswerkzeuge können zusammen mit verwandten Datenverwaltungs-, Data-Governance- und Datenqualitätswerkzeugen verwendet werden.
- Daten-Streaming-Plattformen unterstützen die Echtzeit-Datenerfassung und -verarbeitung, oft mit großen Datenmengen.
- SQL ist eine domänenspezifische Programmiersprache, die häufig in Datenpipelines verwendet wird. Sie ist in erster Linie für die Verwaltung von Daten konzipiert, die in relationalen Datenbanken oder Stream-Verarbeitungsanwendungen mit relationalen Daten gespeichert sind.
- Skriptsprachen werden auch verwendet, um die Ausführung von Aufgaben in Datenpipelines zu automatisieren.
Open Source Tools werden in Datenpipelines immer häufiger eingesetzt. Sie sind am nützlichsten, wenn eine Organisation eine kostengünstige Alternative zu einem kommerziellen Produkt benötigt. Open-Source-Software kann auch von Vorteil sein, wenn eine Organisation über das Fachwissen verfügt, um das Tool für ihre Verarbeitungszwecke zu entwickeln oder zu erweitern.
Was ist der Unterschied zwischen einer ETL-Pipeline und einer Datenpipeline?
Eine ETL-Pipeline bezieht sich auf eine Reihe von integrationsbezogenen Stapelprozessen, die nach einem Zeitplan ausgeführt werden. ETL-Jobs extrahieren Daten aus einem oder mehreren Systemen, führen grundlegende Datentransformationen durch und laden die Daten in ein Repository für Analyse- oder Betriebszwecke.
Eine Datenpipeline hingegen umfasst eine Reihe fortgeschrittener Datenverarbeitungsaktivitäten zum Filtern, Umwandeln und Anreichern von Daten, um den Anforderungen der Benutzer gerecht zu werden. Wie bereits erwähnt, kann eine Datenpipeline die Stapelverarbeitung übernehmen, aber auch im Echtzeitmodus ausgeführt werden, entweder mit Streaming-Daten oder ausgelöst durch eine vorgegebene Regel oder eine Reihe von Bedingungen. Daher kann eine ETL-Pipeline als eine Form einer Datenpipeline angesehen werden.
Bewährte Verfahren für Datenpipelines
Viele Datenpipelines werden von Dateningenieuren oder Big-Data-Ingenieuren erstellt. Um effektive Pipelines zu erstellen, ist es wichtig, dass sie ihre Soft Skills entwickeln – das heißt ihre zwischenmenschlichen und kommunikativen Fähigkeiten. Dies unterstützt dabei, mit Datenwissenschaftlern, anderen Analysten und Geschäftsinteressenten zusammenzuarbeiten, um die Benutzeranforderungen und die dafür erforderlichen Daten zu ermitteln, bevor man ein Entwicklungsprojekt für eine Datenpipeline startet. Solche Fähigkeiten sind auch für laufende Gespräche erforderlich, um neue Entwicklungspläne zu priorisieren und bestehende Datenpipelines zu verwalten.
Zu den weiteren bewährten Verfahren für Datenpipelines gehören:
- Verwalten Sie die Entwicklung einer Datenpipeline als Projekt mit definierten Zielen und Lieferterminen.
- Dokumentieren Sie Informationen zur Datenherkunft, damit die Historie, die technischen Attribute und die geschäftliche Bedeutung von Daten nachvollzogen werden können.
- Stellen Sie sicher, dass der richtige Kontext der Daten beibehalten wird, wenn sie in einer Pipeline transformiert werden.
- Erstellen Sie wiederverwendbare Prozesse oder Vorlagen für Datenpipelineschritte, um die Entwicklung zu optimieren.
Vermeiden Sie eine schleichende Ausweitung des Projektumfangs, die Pipelineprojekte verkomplizieren und bei den Benutzern unrealistische Erwartungen wecken kann.






