Datenmanagement
Was ist Datenmanagement?
Datenmanagement ist der Prozess der Erfassung, Speicherung, Organisation und Pflege von Daten, die eine Organisation erstellt und gesammelt hat. Ein effektives Datenmanagement ist ein entscheidender Bestandteil bei der Bereitstellung von IT-Systemen, die Geschäftsanwendungen ausführen und analytische Informationen bereitstellen, um die betriebliche Entscheidungsfindung und die strategische Planung der Unternehmensleitung, Managern und anderen Endbenutzern zu unterstützen.
Der Datenmanagementprozess umfasst eine Kombination verschiedener Funktionen, die zusammen sicherstellen sollen, dass die Daten in den Unternehmenssystemen korrekt, verfügbar und zugänglich sind. Der größte Teil der erforderlichen Arbeit wird von den IT- und Datenmanagement-Teams erledigt, aber auch die Geschäftsanwender sind in der Regel an einigen Teilen des Prozesses beteiligt, um sicherzustellen, dass die Daten ihren Bedürfnissen entsprechen, und um sie für die Richtlinien zur Nutzung der Daten zu gewinnen.
Die Bedeutung des Datenmanagements
Daten werden zunehmend als Unternehmensressource betrachtet, die genutzt werden kann, um fundiertere Geschäftsentscheidungen zu treffen, Marketingkampagnen zu verbessern, Geschäftsabläufe zu optimieren und Kosten zu senken – alles mit dem Ziel, Umsatz und Gewinn zu steigern. Ein unzureichendes Datenmanagement kann jedoch dazu führen, dass Unternehmen mit inkompatiblen Datensilos, inkonsistenten Datensätzen und Datenqualitätsproblemen konfrontiert werden, die ihre Fähigkeit zur Ausführung von Business-Intelligence- und Analyseanwendungen einschränken – oder sogar zu fehlerhaften Ergebnissen führen.
Die Bedeutung des Datenmanagements hat auch deshalb zugenommen, da Unternehmen immer mehr gesetzliche Vorschriften einhalten müssen, darunter Datenschutzgesetze wie die EU-Datenschutz-Grundverordnung (EU-DSGVO) und der California Consumer Privacy Act (CCPA). Hinzu kommt, dass Unternehmen immer größere Datenmengen und eine größere Vielfalt an Datentypen erfassen – beides Kennzeichen der Big-Data-Systeme, die viele Unternehmen eingesetzt haben. Ohne ein gutes Datenmanagement können solche Umgebungen unübersichtlich und schwer zu navigieren werden.
Arten von Datenmanagementfunktionen
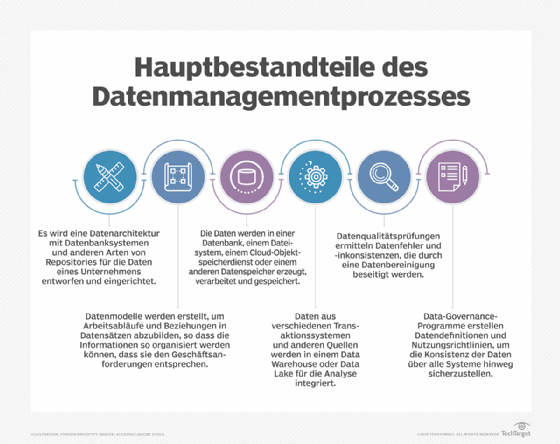
Die einzelnen Disziplinen, die Teil des gesamten Datenmanagementprozesses sind, umfassen eine Reihe von Schritten, von der Datenverarbeitung und -speicherung bis hin zur Steuerung der Datenformatierung und -verwendung in operativen und analytischen Systemen. Die Entwicklung einer Datenarchitektur ist oft der erste Schritt, insbesondere in großen Organisationen mit vielen zu verwaltenden Daten. Eine Datenarchitektur bietet einen Plan für das Management von Daten und den Einsatz von Datenbanken und anderen Datenplattformen, einschließlich spezifischer Technologien, die für einzelne Anwendungen geeignet sind.
Datenbanken sind die am häufigsten genutzte Plattform für die Speicherung von Unternehmensdaten. Sie enthalten eine Sammlung von Daten, die so organisiert sind, dass sie abgerufen, aktualisiert und verwaltet werden können. Sie werden sowohl in Transaktionsverarbeitungssystemen verwendet, die operative Daten wie Kundendatensätze und Kundenaufträge erstellen, als auch in Data Warehouses, in denen konsolidierte Datensätze aus Geschäftssystemen für BI und Analysen gespeichert werden.
Das macht das Datenbankmanagement zu einer Kernfunktion des Datenmanagements. Sobald die Datenbanken eingerichtet sind, muss die Leistung überwacht und abgestimmt werden, um akzeptable Antwortzeiten für Datenbankabfragen zu gewährleisten, die Benutzer ausführen, um Informationen aus den gespeicherten Daten zu erhalten. Zu den weiteren Managementaufgaben gehören Datenbankentwurf, -konfiguration, -installation und -aktualisierung, Datensicherheit, Datenbanksicherung und -wiederherstellung sowie die Anwendung von Software-Upgrades und Sicherheits-Patches.
Die primäre Technologie für den Einsatz und die Verwaltung von Datenbanken ist ein Datenbankmanagementsystem(DBMS), eine Software, die als Schnittstelle zwischen den von ihr kontrollierten Datenbanken und den Datenbankadministratoren (DBAs), den Endnutzern und den Anwendungen, die auf sie zugreifen, fungiert. Zu den alternativen Datenplattformen zu Datenbanken gehören Dateisysteme und Cloud-Objektspeicherdienste, die Daten auf weniger strukturierte Weise speichern als herkömmliche Datenbanken und mehr Flexibilität in Bezug auf die Arten von Daten, die gespeichert werden können, und die Art und Weise, wie die Daten formatiert werden, bieten. Daher eignen sie sich jedoch nicht für transaktionale Anwendungen.
Zu den anderen grundlegenden Disziplinen des Datenmanagements gehören:
- Datenmodellierung, bei der die Beziehungen zwischen Datenelementen und der Datenfluss durch die Systeme dargestellt werden
- Datenintegration, bei der Daten aus verschiedenen Datenquellen für operative und analytische Zwecke kombiniert werden
- Data Governance, die Richtlinien und Verfahren festlegt, um sicherzustellen, dass die Daten im gesamten Unternehmen konsistent sind
- Datenqualitätsmanagement, das darauf abzielt, Datenfehler und Inkonsistenzen zu beheben
- Stammdatenmanagement (Master Data Management, MDM), das einen gemeinsamen Satz von Referenzdaten, zum Beispiel zu Kunden und Produkten, erstellt
Tools und Techniken für das Datenmanagement
Im Rahmen des Datenmanagementprozesses kann eine breite Palette von Technologien, Tools und Techniken eingesetzt werden. Die folgenden Optionen sind für verschiedene Aspekte des Datenmanagements verfügbar.
Datenbankmanagementsysteme. Der am weitesten verbreitete Typ von DBMS ist das relationale Datenbankmanagementsystem (RDBMS). Relationale Datenbanken organisieren Daten in Tabellen mit Zeilen und Spalten, die Datenbankeinträge enthalten. Zusammengehörige Datensätze in verschiedenen Tabellen können durch die Verwendung von Primär- und Fremdschlüsseln miteinander verbunden werden, so dass keine doppelten Dateneinträge erstellt werden müssen. Relationale Datenbanken basieren auf der Programmiersprache SQL und einem starren Datenmodell, das sich am besten für strukturierte Transaktionsdaten eignet. Dies und ihre Unterstützung der AKID-Transaktionseigenschaften – Atomarität, Konsistenz, Isolation und Dauerhaftigkeit – haben sie zur ersten Wahl für transaktionsverarbeitende Anwendungen gemacht.
Es haben sich jedoch auch andere Arten von DBMS-Technologien für verschiedene Arten von Daten-Workloads herauskristallisiert. Die meisten werden als NoSQL-Datenbanken kategorisiert, die keine starren Anforderungen an Datenmodelle und Datenbankschemata stellen. Daher können sie unstrukturierte und semistrukturierte Datenspeichern, zum Beispiel Sensordaten, Internet-Clickstream-Datensätze und Netzwerk-, Server- sowie Anwendungsprotokolle.
Es gibt vier Haupttypen von NoSQL-Systemen:
- Dokumentdatenbanken, die Datenelemente in dokumentenähnlichen Strukturen speichern
- Key-Value-Datenbanken, die eindeutige Schlüssel und zugehörige Werte miteinander verbinden
- Wide-Column-Stores mit Tabellen, die eine große Anzahl von Spalten haben
- Graphdatenbanken, die zusammengehörige Datenelemente in einem Graphformat miteinander verbinden.
Die Bezeichnung NoSQL hat sich jedoch zu einer falschen Bezeichnung entwickelt: NoSQL-Datenbanken basieren zwar nicht auf SQL, aber viele von ihnen unterstützen mittlerweile Elemente davon und bieten ein gewisses Maß an AKID/ACID-Konformität.
Zu den zusätzlichen Datenbank- und DBMS-Optionen gehören In-Memory-Datenbanken, die Daten im Arbeitsspeicher eines Servers statt auf der Festplatte speichern, um die I/O-Leistung zu beschleunigen, sowie spaltenorientierte Datenbanken, die auf Analyseanwendungen ausgerichtet sind. Hierarchische Datenbanken, die auf Mainframes laufen und vor der Entwicklung von relationalen und NoSQL-Systemen entwickelt wurden, können ebenfalls noch verwendet werden. Benutzer können Datenbanken in lokalen oder Cloud-Systemen einsetzen. Darüber hinaus bieten verschiedene Datenbankanbieter gemanagte Cloud-Datenbankdienste an, bei denen sie die Bereitstellung, Konfiguration und Verwaltung von Datenbanken für die Nutzer übernehmen.
Big-Data-Management. NoSQL-Datenbanken werden aufgrund ihrer Fähigkeit, verschiedene Datentypen zu speichern und zu verwalten, häufig in Big-Data-Umgebungen eingesetzt. Big-Data-Umgebungen basieren häufig auf Open-Source-Technologien wie Hadoop, einem verteilten Verarbeitungs-Framework mit einem Dateisystem, das auf Clustern von handelsüblichen Servern ausgeführt wird, der zugehörigen HBase-Datenbank, der Spark-Verarbeitungsmaschine und den Stream-Verarbeitungsplattformen Kafka, Flink und Storm. Big-Data-Systeme werden zunehmend in der Cloud eingesetzt, wobei Objektspeicher wie der Amazon Simple Storage Service (S3) verwendet werden.
Data Warehouses und Data Lakes. Die beiden am weitesten verbreiteten Repositories für die Verwaltung von Analysedaten sind Data Warehouses und Data Lakes. Ein Data Warehouse – die traditionellere Methode – basiert in der Regel auf einer relationalen oder spaltenorientierten Datenbank und speichert strukturierte Daten, die aus verschiedenen operativen Systemen zusammengezogen und für die Analyse vorbereitet wurden. Die wichtigsten Anwendungsfälle für ein Data Warehouse sind Business-Intelligence-Abfragen und Unternehmensberichte, die es Analysten und Führungskräften ermöglichen, Umsatz, Bestandsmanagement und andere KPIs zu analysieren.
Ein Enterprise Data Warehouse umfasst Daten aus den Geschäftssystemen eines gesamten Unternehmens. In großen Unternehmen können einzelne Tochtergesellschaften und Geschäftseinheiten mit Managementautonomie ihre eigenen Data Warehouses aufbauen. Data Marts sind eine weitere Data-Warehouse-Option – kleinere Versionen von Data Warehouses, die Teilmengen der Daten eines Unternehmens für bestimmte Abteilungen oder Benutzergruppen enthalten. Bei einem Implementierungsansatz wird ein bestehendes Data Warehouse verwendet, um verschiedene Data Marts zu erstellen. Bei einem anderen Ansatz werden Data Marts zuerst erstellt und dann zum Auffüllen eines Data Warehouse verwendet.
In Data Lakes hingegen werden große Datenmengen gespeichert, die für prädiktive Modellierung, maschinelles Lernen und andere fortschrittliche Analyseanwendungen verwendet werden. Ursprünglich wurden sie meist auf Hadoop-Clustern aufgebaut, aber S3 und andere Cloud-Objektspeicherdienste werden zunehmend für Data-Lake-Bereitstellungen verwendet. Manchmal werden sie auch auf NoSQL-Datenbanken bereitgestellt, und verschiedene Plattformen lassen sich in einer verteilten Data-Lake-Umgebung kombinieren. Die Daten können für die Analyse verarbeitet werden, wenn man sie einspeist, doch ein Data Lake enthält oft Rohdaten, die unverändert gespeichert werden. In diesem Fall führen Data Scientists und andere Analysten in der Regel ihre eigene Datenaufbereitung für spezifische analytische Zwecke durch.
Eine dritte Plattformoption für die Speicherung und Verarbeitung von Analysedaten ist ebenfalls aufgetaucht: das Data Lakehouse. Wie der Name schon sagt, kombiniert es Elemente von Data Lakes und Data Warehouses und verbindet die flexible Datenspeicherung, die Skalierbarkeit und die niedrigeren Kosten eines Data Lakes mit den Abfragefunktionen und der strengeren Datenmanagementstruktur eines Data Warehouses.
Datenintegration. Die am weitesten verbreitete Datenintegrationstechnik ist Extract, Transform, Load (ETL), bei dem Daten aus Quellsystemen entnommen, in ein einheitliches Format umgewandelt und dann in ein Data Warehouse oder ein anderes Zielsystem geladen werden. Mittlerweile unterstützen Datenintegrationsplattformen jedoch auch eine Vielzahl anderer Integrationsmethoden. Dazu gehören Extract, Load, Transform (ELT), eine Variante von ETL, bei der man die Daten in ihrer ursprünglichen Form belässt, wenn sie in die Zielplattform geladen werden. ELT ist eine gängige Wahl für die Datenintegration in Data Lakes und andere Big-Data-Systeme.
ETL und ELT sind Batch-Integrationsprozesse, die in geplanten Intervallen ablaufen. Datenmanagementteams können auch eine Datenintegration in Echtzeit durchführen, indem sie Methoden wie die Änderungsdatenerfassung verwenden, bei der Änderungen an den Daten in Datenbanken in ein Data Warehouse oder ein anderes Repository übernommen werden, oder die Streaming-Datenintegration, bei der Echtzeitdatenströme kontinuierlich integriert werden. Datenvirtualisierung ist eine weitere Integrationsmöglichkeit, bei der eine Abstraktionsschicht verwendet wird, um eine virtuelle Ansicht von Daten aus verschiedenen Systemen für Endbenutzer zu erstellen, anstatt die Daten physisch in ein Data Warehouse zu laden.
Datenmodellierung. Datenmodellierer erstellen eine Reihe von konzeptionellen, logischen und physischen Datenmodellen, die Datensätze und Arbeitsabläufe in visueller Form dokumentieren und sie den Geschäftsanforderungen für die Transaktionsverarbeitung und Analyse zuordnen. Zu den gängigen Techniken der Datenmodellierung gehören die Entwicklung von Entity-Relationship-Diagrammen, Daten-Mapping und Schemata in einer Vielzahl von Modelltypen. Datenmodelle müssen oft aktualisiert werden, wenn neue Datenquellen hinzukommen oder sich der Informationsbedarf eines Unternehmens ändert.
Data Governance, Datenqualität und Stammdatenmanagement. Data Governance ist in erster Linie ein organisatorischer Prozess. Softwareprodukte, die bei der Verwaltung von Data-Governance-Programmen unterstützen, sind zwar verfügbar, stellen aber ein optionales Element dar. Governance-Programme können zwar von Datenmanagement-Fachleuten verwaltet werden, umfassen aber in der Regel einen Data Governance Council, der sich aus Führungskräften des Unternehmens zusammensetzt und gemeinsam Entscheidungen über gemeinsame Datendefinitionen und Unternehmensstandards für die Erstellung, Formatierung und Verwendung von Daten trifft.

Ein weiterer wichtiger Aspekt von Governance-Initiativen ist die Datenverwaltung, bei der es darum geht, die Datensätze zu überwachen und sicherzustellen, dass die Endbenutzer die genehmigten Datenrichtlinien einhalten. Je nach Größe des Unternehmens und dem Umfang des Governance-Programms kann es sich bei dem Datenverantwortlichen um eine Voll- oder Teilzeitstelle handeln. Datenmanager können sowohl aus dem Geschäftsbetrieb als auch aus der IT-Abteilung kommen. In jedem Fall ist eine genaue Kenntnis der Daten, die sie überwachen, normalerweise eine Voraussetzung.
Data Governance ist eng mit Bemühungen zur Verbesserung der Datenqualität verbunden. Die Sicherstellung eines hohen Datenqualitätsniveaus ist ein wesentlicher Bestandteil einer effektiven Data Governance, und Kennzahlen, die Verbesserungen der Datenqualität eines Unternehmens dokumentieren, sind von zentraler Bedeutung für den Nachweis des geschäftlichen Nutzens von Governance-Programmen. Zu den wichtigsten Datenqualitätstechniken, die von verschiedenen Software-Tools unterstützt werden, gehören:
- Data Profiling, bei der Datensätze gescannt werden, um Ausreißerwerte zu identifizieren, bei denen es sich um Fehler handeln kann
- Datenbereinigung, auch bekannt als Data Scrubbing, bei der Datenfehler durch Änderung oder Löschung fehlerhafter Daten behoben werden
- Datenvalidierung, bei der die Daten anhand vorgegebener Qualitätsregeln überprüft werden
Stammdatenmanagement ist auch mit Data Governance und Datenqualitätsmanagement verbunden, obwohl es noch nicht so weit verbreitet ist wie diese. Das liegt zum Teil an der Komplexität von Stammdatenmanagementprogrammen, die sie meist auf große Unternehmen beschränkt. Stammdatenmanagement erstellt ein zentrales Register von Stammdaten für ausgewählte Datendomänen, was oft als Golden Recordbezeichnet wird. Die Stammdaten werden in einem Hub gespeichert, der die Daten an Analysesysteme für konsistente Unternehmensberichte und -analysen weiterleitet. Falls gewünscht, kann der Hub auch aktualisierte Stammdaten an die Quellsysteme zurückgeben.
Data Observability (Datenbeobachtung) ist ein neuer Prozess, der Datenqualitäts- und Data-Governance-Initiativen ergänzt, indem er ein vollständigeres Bild des Datenzustands in einem Unternehmen liefert. In Anlehnung an die Beobachtungspraktiken in IT-Systemen überwacht Data Observability Datenpipelines und Datensätze und identifiziert Probleme, die behoben werden müssen. Tools zur Datenbeobachtung können zur Automatisierung von Überwachungs-, Warn- und Ursachenanalyseverfahren sowie zur Planung und Priorisierung von Problembehebungsmaßnahmen eingesetzt werden.
Bewährte Praktiken des Datenmanagements
Im Folgenden finden Sie einige Best Practices, die dazu beitragen, den Datenmanagementprozess in einem Unternehmen auf dem richtigen Weg zu halten.
Machen Sie Data Governance und Datenqualität zur obersten Priorität. Ein starkes Data-Governance-Programmist eine entscheidende Komponente effektiver Datenverwaltungsstrategien, insbesondere in Unternehmen mit verteilten Datenumgebungen, die eine Vielzahl von Systemen umfassen. Ein starker Fokus auf die Datenqualität ist ebenfalls ein Muss. In beiden Fällen können die IT- und Datenverwaltungsteams jedoch keine Alleingänge machen. Die Geschäftsleitung und die Benutzer müssen einbezogen werden, um sicherzustellen, dass ihre Datenanforderungen erfüllt werden und Datenqualitätsprobleme nicht fortbestehen. Das Gleiche gilt für Datenmodellierungsprojekte.
Setzen Sie Datenmanagementplattformen mit Bedacht ein. Die Vielzahl an Datenbanken und anderen Datenplattformen, die zur Verfügung stehen, erfordert einen sorgfältigen Ansatz beim Entwurf einer Architektur und bei der Bewertung und Auswahl von Technologien. IT- und Datenmanager müssen sicher sein, dass die von ihnen implementierten Datenmanagementsysteme für den beabsichtigten Zweck geeignet sind und die Datenverarbeitungsfunktionen und Analyseinformationen bereitstellen, die für die Geschäftsabläufe eines Unternehmens erforderlich sind.
Stellen Sie sicher, dass Sie die Geschäfts- und Benutzeranforderungen jetzt und in Zukunft erfüllen.Datenumgebungen sind nicht statisch – neue Datenquellen kommen hinzu, bestehende Datensätze ändern sich und die geschäftlichen Anforderungen an Daten entwickeln sich weiter. Um mithalten zu können, muss das Datenmanagement in der Lage sein, sich an veränderte Anforderungen anzupassen. Beispielsweise müssen Datenteams bei der Erstellung und Aktualisierung von Datenpipelines eng mit den Endbenutzern zusammenarbeiten, um sicherzustellen, dass sie alle erforderlichen Daten kontinuierlich enthalten. Ein DataOps-Prozess kann dabei unterstützen – ein kollaborativer Ansatz für die Entwicklung von Datensystemen und Pipelines, der aus einer Kombination von DevOps, agiler Softwareentwicklung und schlanken Fertigungsmethoden abgeleitet ist. DataOps bringt Datenmanager und Benutzer zusammen, um Arbeitsabläufe zu automatisieren, die Kommunikation zu verbessern und die Datenbereitstellung zu beschleunigen.
DAMA International, die Data Governance Professionals Organization und andere Branchengruppen bieten ebenfalls Best-Practice-Anleitungen und Bildungsressourcen zu Datenmanagementdisziplinen an. DAMA hat beispielsweise das DAMA-DMBOK: Data Management Body of Knowledge veröffentlicht, ein Nachschlagewerk, das versucht, eine Standardansicht der Datenmanagementfunktionen und -methoden zu definieren. Es wurde 2009 erstmals veröffentlicht und 2017 in einer zweiten Auflage, dem DMBOK2, herausgegeben.
Risiken und Herausforderungen des Datenmanagements
Ständig wachsende Datenmengen erschweren den Datenmanagementprozess, insbesondere wenn es sich um eine Mischung aus strukturierten, semistrukturierten und unstrukturierten Daten handelt. Wenn ein Unternehmen nicht über eine gut durchdachte Datenarchitektur verfügt, kann es außerdem zu isolierten Systemen kommen, die sich nur schwer integrieren und koordiniert verwalten lassen. Dadurch wird es schwieriger, sicherzustellen, dass die Datensätze über alle Datenplattformen hinweg korrekt und konsistent sind.
Selbst in besser geplanten Umgebungen kann es für Datenwissenschaftler und andere Analysten eine Herausforderung sein, relevante Daten zu finden und darauf zuzugreifen, insbesondere wenn die Daten über verschiedene Datenbanken und Big-Data-Systeme verteilt sind. Um den Zugang zu den Daten zu erleichtern, erstellen viele Datenmanagementteams Datenkataloge, die dokumentieren, was in den Systemen verfügbar ist, und die in der Regel Geschäftsglossare, Datenwörterbücher auf Basis von Metadaten und Data-Lineage-Aufzeichnungen enthalten.
Die zunehmende Verlagerung in die Cloud kann einige Aspekte der Datenmanagementarbeit erleichtern, schafft aber auch neue Herausforderungen. So kann die Migration zu Cloud-Datenbanken für Unternehmen, die Daten und Verarbeitungslasten von bestehenden lokalen Systemen verlagern müssen, kompliziert sein. Die Kosten sind ein weiteres großes Thema in der Cloud: Die Nutzung von Cloud-Systemen und gemanagten Diensten muss genau überwacht werden, um sicherzustellen, dass die Rechnungen für die Datenverarbeitung die veranschlagten Beträge nicht übersteigen.
Viele Datenmanagementteams gehören heute zu den Mitarbeitern, die für den Schutz der Unternehmensdaten und die Begrenzung der potenziellen rechtlichen Haftung bei Datenschutzverletzungen oder Datenmissbrauch verantwortlich sind. Datenmanager müssen dazu beitragen, die Einhaltung der staatlichen und branchenspezifischen Vorschriften für Datensicherheit, Datenschutz und Datennutzung zu gewährleisten. Mit der Verabschiedung der EU-DSGVO, die im Mai 2018 in Kraft trat, und dem CCPA, das 2018 unterzeichnet wurde und Anfang 2020 in Kraft trat, ist dies ein dringlicheres Anliegen geworden.
Aufgaben und Rollen des Datenmanagements
Der Datenmanagementprozess umfasst ein breites Spektrum an Aufgaben, Pflichten und Fähigkeiten. In kleineren Organisationen mit begrenzten Ressourcen können einzelne Mitarbeiter mehrere Aufgaben übernehmen. In größeren Unternehmen hingegen gehören zu den Datenmanagementteams in der Regel Datenarchitekten, Datenmodellierer, DBAs, Datenbankentwickler, Datenadministratoren, Datenqualitätsanalysten und -ingenieure sowie ETL-Entwickler. Eine weitere Rolle, die immer häufiger anzutreffen ist, ist die des Data-Warehouse-Analysten, der bei der Verwaltung der Daten in einem Data Warehouse unterstützt und analytische Datenmodelle für Geschäftsanwender erstellt.
Data Scientists, andere Datenanalysten und Dateningenieure, die bei der Erstellung von Datenpipelines und der Vorbereitung von Daten für die Analyse unterstützen, können ebenfalls Teil eines Datenmanagementteams sein. In anderen Fällen gehören sie zu einem separaten Datenwissenschaftler- oder Analyseteam. Aber selbst dann erledigen sie in der Regel einige Datenmanagementaufgaben selbst, insbesondere in Data Lakes mit Rohdaten, die gefiltert und für bestimmte Analysezwecke vorbereitet werden müssen.
Ebenso unterstützen Anwendungsentwickler manchmal bei der Bereitstellung und Verwaltung von Big-Data-Plattformen, die im Vergleich zu relationalen Datenbanksystemen insgesamt neue Fähigkeiten erfordern. Infolgedessen müssen Unternehmen möglicherweise neue Mitarbeiter einstellen oder herkömmliche DBAs umschulen, um ihre Big-Data-Managementanforderungen zu erfüllen.
Data-Governance-Manager und Datenmanager zählen ebenfalls zu den Datenmanagement-Experten. Sie sind jedoch in der Regel Teil eines separaten Data-Governance-Teams.
Vorteile eines guten Datenmanagements
Eine gut umgesetzte Datenmanagementstrategie kann Unternehmen auf verschiedene Weise zugutekommen:
- Sie kann Unternehmen dabei unterstützen, potenzielle Wettbewerbsvorteile gegenüber ihren Konkurrenten zu erlangen, indem sie sowohl die betriebliche Effizienz verbessert als auch eine bessere Entscheidungsfindung ermöglicht.
- Unternehmen mit gut gemanagten Daten können flexibler werden, indem sie Markttrends erkennen und neue Geschäftsmöglichkeiten schneller nutzen können.
- Ein effektives Datenmanagement kann Unternehmen auch dabei unterstützen, Datenschutzverletzungen, Fehler bei der Datenerfassung und andere Probleme mit der Datensicherheit und dem Datenschutz zu vermeiden, die ihrem Ruf schaden, unerwartete Kosten verursachen und sie in rechtliche Schwierigkeiten bringen können.
- Letztendlich kann ein solider Ansatz für das Datenmanagement zu einer besseren Unternehmensleistung führen, indem er dazu beiträgt, Geschäftsstrategien und -prozesse zu verbessern.
Geschichte, Entwicklung und Trends des Datenmanagements
Die erste Hochphase des Datenmanagements wurde größtenteils von IT-Fachleuten vorangetrieben, die sich auf die Lösung des Problems Garbage in, garbage out in den ersten Computern konzentrierten, nachdem sie erkannt hatten, dass die Maschinen zu falschen Schlussfolgerungen kamen, weil sie mit ungenauen oder unzureichenden Daten gespeist wurden. In den 1960er Jahren kamen hierarchische Datenbanken auf Großrechnern auf, die den aufkeimenden Prozess des Datenmanagements formaler gestalteten.
Die relationale Datenbank kam in den 1970er Jahren auf und etablierte sich in den 1980er Jahren im Zentrum des Datenmanagementökosystems. Die Idee des Data Warehouse wurde Ende der 1980er Jahre entwickelt, und die ersten Anwender des Konzepts begannen Mitte der 1990er Jahre mit der Einrichtung von Data Warehouses. Anfang der 2000er Jahre war relationale Software eine dominierende Technologie, die den Einsatz von Datenbanken praktisch ausschloss.
Die erste Version von Hadoop kam 2006 auf den Markt, gefolgt von Spark und verschiedenen anderen Big-Data-Technologien. Im gleichen Zeitraum wurde auch eine Reihe von NoSQL-Datenbanken auf den Markt gebracht. Zwar sind relationale Plattformen immer noch die bei weitem am häufigsten verwendeten Datenspeicher, doch mit dem Aufkommen von Big Data und NoSQL-Alternativen und den von ihnen ermöglichten Data-Lake-Umgebungen haben Unternehmen eine breitere Auswahl an Datenmanagementmöglichkeiten. Mit der Einführung des Data-Lakehouse-Konzepts im Jahr 2017 wurden die Möglichkeiten noch erweitert.
Aber all diese Möglichkeiten haben viele Datenumgebungen komplexer gemacht. Das treibt die Entwicklung neuer Technologien und Prozesse voran, die deren Verwaltung erleichtern sollen. Dazu gehören neben Data Observability auch Data Fabric, ein Framework, das darauf abzielt, Datenbestände durch die Automatisierung von Integrationsprozessen und ihre Wiederverwendbarkeit besser zu vereinheitlichen, und Data Mesh, eine dezentrale Architektur, bei der die Verantwortung für Dateneigentum und -verwaltung einzelnen Geschäftsbereichen übertragen wird, mit einer föderierten Governance zur Vereinbarung von Unternehmensstandards und -richtlinien.
Keiner dieser drei Ansätze ist jedoch bisher weit verbreitet. In seinem Bericht zum Hype Cycle 2022 über neue Datenmanagementtechnologien stellt das Beratungsunternehmen Gartner fest, dass jede dieser Technologien von weniger als fünf Prozent der Zielanwendergruppe angenommen wird. Gartner prognostizierte, dass Data Fabric und Data Observability beide noch fünf bis zehn Jahre davon entfernt sind, ihre volle Reife zu erlangen und von der breiten Masse angenommen zu werden, aber sie können letztendlich vorteilhaft für die Nutzer sein. Bei Data Mesh ist man weniger optimistisch und stuft den potenziellen Nutzen als gering ein.
Im Folgenden werden einige weitere bemerkenswerte Trends vorgestellt:
Technologien zum Datenmanagement in der Cloud sind auf dem Vormarsch. Gartner hat berechnet, dass Cloud-Datenbanken im Jahr 2022 50 Prozent des gesamten DBMS-Umsatzes ausgemacht haben. Im Hype-Cycle-Bericht heißt es, dass Unternehmen auch schnell neue Datenmanagementtechnologien in der Cloud einsetzen. Für Unternehmen, die noch nicht für eine vollständige Migration bereit sind, sind hybride Cloud-Architekturen, die Cloud- und lokale Systeme kombinieren, wie zum Beispiel hybride Data-Warehouse-Umgebungen, ebenfalls eine Option.
Erweiterte Datenmanagementfunktionen tragen zur Rationalisierung von Prozessen bei. Softwareanbieter fügen erweiterte Funktionen für Datenqualität, Datenbankmanagement, Datenintegration und Datenkatalogisierung hinzu, die KI- und Machine-Learning-Technologien nutzen, um sich wiederholende Aufgaben zu automatisieren, Probleme zu erkennen und Maßnahmen vorzuschlagen.
Das Wachstum des Edge Computing schafft neue Anforderungen an das Datenmanagement. Da Unternehmen zunehmend Remote-Sensoren und IoT-Geräte einsetzen, um Daten als Teil von Edge-Computing-Umgebungen zu sammeln und zu verarbeiten, entwickeln einige Anbieter auch Edge-Data-Management-Funktionen für Endpunktgeräte.







