Data Protection

Was ist Data Protection?
Data Protection ist der Prozess der Sicherung von Daten und der Wiederherstellung wichtiger digitaler Informationen für den Fall, dass Daten aufgrund von Cyberangriffen, Ausfällen, vorsätzlicher Beschädigung oder menschlichem Versagen beschädigt, kompromittiert oder verloren gehen. Er umfasst Technologien, Verfahren, Prozesse und Arbeitsabläufe, die den rechtmäßigen Zugriff auf Daten gewährleisten, sodass diese bei Bedarf verfügbar sind.
Um Daten zu schützen und den Zugriff zu gewährleisten, kann eine angemessene Data Protection von verschiedenen Technologien und Techniken abhängen, darunter die folgenden:
- Magnetische oder Solid-State-Laufwerksspeichergeräte (Tapes oder SSDs), Storage-Server und Speicher-Arrays.
- Herkömmliche Datensicherungen, kontinuierliche Datensicherung (Continuous Data Protection, CDP) und Hochverfügbarkeitstechniken.
- Storage Tiering für wichtigere oder häufig abgerufene Daten.
Um sicherzustellen, dass Daten in geeigneter Weise aufbewahrt und behandelt werden, muss die Data Protection durch Dateninventarisierung, Backups und Recoveries sowie eine Strategie zur Verwaltung der Daten während ihres gesamten Lebenszyklus unterstützt werden:
- Die Dateninventarisierung ermittelt die Mengen und Arten der im Unternehmen vorhandenen Daten und stellt sicher, dass alle erkannten Daten in die Data-Protection-Planung und das Lebenszyklusmanagement einbezogen werden.
- Backup und Recovery schützen Daten vor Hardwareausfällen, versehentlichem Verlust oder vorsätzlicher Misshandlung, verfolgen die Häufigkeit von Sicherungen und beschreiben den Prozess der Datenwiederherstellung.
- Das Datenlebenszyklusmanagement (Data Lifecycle Management, DLM) umfasst die Tools und Prozesse zur Überwachung der Klassifizierung, Speicherung, Sicherung und schließlich Vernichtung von Daten gemäß internen Data-Protection-Richtlinien sowie Branchenstandards und Datenschutzgesetzen.
Dieser Leitfaden untersucht die Aspekte Der Data Protection, einschließlich Vorteile, Herausforderungen, Technologien und Trends. Die Leser erhalten außerdem eine Gesamtanalyse darüber, was Unternehmen tun müssen, um die immer zahlreicheren lokalen, nationalen und regionalen Datenschutzgesetze einzuhalten.
Warum ist Data Protection wichtig?
Weltweit erzeugen wir täglich etwa 2,5 Quintillionen (Millionen Billionen) Byte an Daten (diese Zahl wurde erstmals 2012 in einem Whitepaper zu Big Data von IBM veröffentlicht). Wie Unternehmen einen Großteil dieser Daten sammeln, verarbeiten, speichern und monetarisieren, entscheidet über ihre geschäftliche Zukunft. Die Festlegung von Richtlinien und die Implementierung von Technologien zum Schutz der Integrität und des rechtmäßigen Zugriffs auf dieses wichtige Kapital ist von größter Bedeutung.
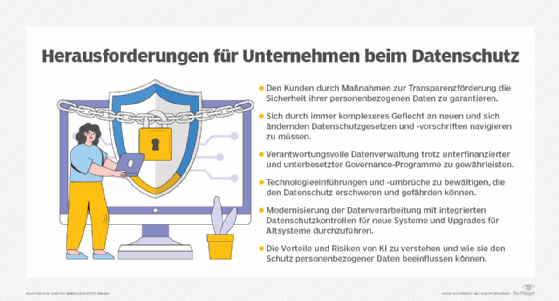
Diese Aufgabe ist nicht einfach. Das heutige Data-Protection-Klima unterscheidet sich erheblich von dem vor wenigen Jahren und ist weitaus komplexer. Die Herausforderungen im Bereich Data Protection und Privatsphäre sind vielfältig.
Zu den wichtigsten Problemen, mit denen Unternehmen und ihre Data-Protection-Teams fast täglich konfrontiert sind, gehören die folgenden:
- Verwaltung, Vorhalten und Monetarisierung riesiger Mengen gesammelter Daten.
- Feststellung, wann Daten ihre Nützlichkeit verloren haben und zu einer Belastung werden.
- Verhinderung neuer und immer ausgefeilter Cybersicherheitsbedrohungen und Datenverstöße.
- Sicherung von Daten und Dateien in zunehmend verteilten Cloud-Umgebungen.
- Integration der neuesten Technologien in bestehende IT- und Geschäftsumgebungen.
- Ausschöpfung des vollen Potenzials von künstlicher Intelligenz (KI), maschinellem Lernen (ML) und nun auch generativen KI-Technologien (GenAI).
- Einhaltung neuer und aktualisierter internationaler und staatlicher Datenschutzgesetze.
- Anpassung an strengere und manchmal unspezifische gesetzliche Bestimmungen, die mit schweren Strafen verbunden sind.
- Bewältigung schwankender Budget- und Ausgabenprobleme aufgrund geopolitischer Ereignisse, die außerhalb der Kontrolle der meisten Unternehmen liegen.

Data Protection vs. Datenschutz vs. Datensicherheit
Die drei wichtigsten Aspekte Daten zu sichern sind Data Protection, Datensicherheit und Datenschutz. Diese drei Funktionen werden manchmal als synonym angesehen, aber jede von ihnen spielt je nach Organisation, Branche, Anwendung und geografischem Standort eine unterschiedliche Rolle.
Im Wesentlichen schützt Data Protection Informationen vor Beschädigung, Verfälschung oder Verlust und stellt durch Backup, Recovery und ordnungsgemäße Governance sicher, dass die Daten für die Benutzer jederzeit verfügbar sind. Beim Datenschutz geht es um die Kontrolle des Zugriffs auf bestimmte Daten. Die Datensicherheit zielt darauf ab, die Integrität der Daten vor internen und externen Bedrohungen durch Manipulation und Malware zu schützen.
Data Protection
Data Protection umfasst die Technologien, Praktiken, Prozesse und Arbeitsabläufe, die die Verfügbarkeit von Daten gewährleisten, einschließlich der Aufbewahrung, Unveränderlichkeit und Speicherung der Daten. In vielen Organisationen ist ein Data-Protection-Verantwortlicher oder eine Person in einer ähnlichen Position dafür verantwortlich, dass die Speicherung von Daten während ihres gesamten Lebenszyklus den geschäftlichen Anforderungen entspricht und den gesetzlichen Bestimmungen der Branche und der Regierung entspricht.
Data Protection umfasst dabei nicht nur die technischen Maßnahmen wie Backup, Recovery und Governance, sondern auch um den Schutz der Daten im rechtlichen Kontext. Die technischen Einrichtungen und Aktivitäten müssen also so konfiguriert, verwaltet und überwacht werden, dass sie die Compliance-Vorgaben einhalten. Data Protection wird oft synonym mit Datenschutz verwendet, der Begriff ist aber umfassender und enthält mehr Kriterien.
Datenschutz
Der Datenschutz schützt die Erhebung, Verwendung, Änderung, Speicherung und Offenlegung personenbezogener und sensibler Daten. Er setzt sich für das Recht des Einzelnen ein, seine Daten privat und vertraulich zu halten, einschließlich des Rechts auf Vergessenwerden. Personenbezogene Daten sind in der Regel Informationen, die als Daten, mit denen sich Personen identifizieren lassen (Personally Identifiable Information, PII), persönliche Gesundheitsdaten oder Finanzdaten klassifiziert sind. Die DSGVO kategorisiert zudem in ihrem Artikel 9 Gesundheitsdaten, biometrische Daten, genetische Daten sowie Daten zur politischen Meinung oder religiösen Überzeugung zu personenbezogenen Daten.
Weitere Beispiele für personenbezogene Daten sind:
- Name, Adresse, Telefonnummer, E-Mail-Adresse, Geburtsdatum, Ausweisnummern.
- IP-Adressen, MAC-Adressen, Cookies, Standortdaten, Geräte-IDs.
- Bankdaten, Kreditkartennummern, Steuer-ID, Versicherungsnummer.
Unternehmen, die gute Datenschutzpraktiken anwenden, zeigen sich transparent in Bezug auf die Erhebung, Speicherung und Verwendung personenbezogener Daten, sodass Kunden verstehen, warum ihre personenbezogenen Daten erhoben werden, wie ihre Daten verwendet oder weitergegeben werden, wie ihre Daten verwaltet und geschützt werden und welche Rechte sie haben, ihre Daten und deren Verwendung zu ergänzen, zu ändern oder einzuschränken. Ein Datenschutzbeauftragter ist für die Entwicklung, Umsetzung und Kommunikation von Datenschutzrichtlinien und -verfahren im Zusammenhang mit dem Datenzugriff verantwortlich.
Es gibt klare gesetzliche Richtlinien zum Datenschutz, so zum Beispiel die EU-DSGVO oder das BDSG (Bundesdatenschutzgesetz).

Datensicherheit
Datensicherheit spielt eine wichtige Rolle bei der Einhaltung gesetzlicher Vorschriften und der Unternehmensführung, da sie Daten während ihres gesamten Lebenszyklus vor Diebstahl, Beschädigung, unzulässiger Änderung oder unbefugtem Zugriff schützt. Datensicherheit wird für alle Daten gewährleistet, nicht nur für personenbezogene und sensible Daten.
Zu einer angemessenen Datensicherheit gehören Technologien und Prozesse, Speichergeräte, Server, Netzwerkgeräte und die physische Computerumgebung innerhalb des Rechenzentrums und im gesamten Unternehmen. Zur Datensicherheit gehören auch Zugriffskontrollsysteme wie Identitäts- und Zugriffsmanagement, Protokollierung, Überwachung und Verfolgung des Datenzugriffs sowie Verschlüsselungstechnologien für gespeicherte, verwendete und übertragene Daten. Ein Informationssicherheitsbeauftragter (ISB) implementiert Richtlinien und Verfahren, in denen detailliert beschrieben wird, wie Daten gesichert und abgerufen werden, sowie Ansätze zum Umgang mit Sicherheitsverletzungen.
Data-Protection-Technologien
Die zunehmende Häufigkeit und Raffinesse von Cyberbedrohungen hat Unternehmen dazu gezwungen, größere Investitionen in Tools, Technologien und Prozesse zu tätigen, die einen besseren Schutz und einen sichereren Zugriff auf Daten bieten. Datea-Protection-Technologien bieten eine Reihe von Funktionen und Merkmalen, darunter die folgenden:
- Bei der Datensicherung (Backup) werden Kopien der Produktionsdaten erstellt, mit denen ein Unternehmen seine Daten ersetzen kann, falls die Produktionsumgebung kompromittiert wird.
- Technisch bedeutet Datenportabilität die Fähigkeit, Daten zwischen Systemen und Cloud-Umgebungen nahtlos zu verschieben, um Abhängigkeiten von einzelnen Anbietern zu vermeiden. (Im rechtlichen Kontext bezeichnet Datenportabilität das Recht von Individuen, ihre personenbezogenen Daten in einem übertragbaren Format zu erhalten.)
- Datenwiederherstellungs-Tools (Recovery) optimieren oder automatisieren den Prozess der Wiederherstellung verlorener Daten und der davon abhängigen Systeme nach einer Datenverletzung, Beschädigung oder einem Verlust.
- Data-Discovery-Funktionen helfen dabei, Daten zu lokalisieren, die Unternehmen schützen müssen, deren Existenz ihnen jedoch in ihren komplexen IT-Umgebungen möglicherweise nicht bewusst ist.
- Das Data Mapping beschreibt den Prozess, Datenbestände zu identifizieren und nachzuvollziehen, wo sie gespeichert, verarbeitet und weitergegeben werden. Dadurch lassen sich Schutzmaßnahmen gezielter umsetzen und regulatorische Anforderungen wie die DSGVO besser erfüllen.
- Die Verhinderung von Datenverlusten (Data Loss Prevention, DLP) für Netzwerk-, Endpunkt- und Cloud-Anwendungen erkennt und verhindert den Verlust, die Weitergabe oder den Missbrauch von Daten durch Sicherheitsverletzungen, Exfiltrationsübertragungen und unbefugte Nutzung.
- Die Datenüberwachung verfolgt automatisch den Zugriff auf Datenbanken und andere Ressourcen, um Anomalien zu identifizieren, die auf Versuche hindeuten könnten, sensible Daten einzusehen, zu ändern oder zu löschen.
Data Protection as a Service (DPaaS) gilt als One-Stop-Shop für Data-Protection- und Datenmanagementfunktionen im Zusammenhang mit der Erstellung, Verarbeitung, Sicherheit, Verwaltung, Speicherung, Backups und Wiederherstellung von Daten, die alle in einem Managed Service gebündelt sind, der durch Cloud-basierte Ressourcen unterstützt wird. DPaaS kann in der Regel den Platzbedarf für physische Geräte reduzieren und ermöglicht eine schnellere Bereitstellung von Diensten im Vergleich zu einer Vor-Ort-Lösung. Unternehmen sollten jedoch die Risiken einer Anbieterabhängigkeit berücksichtigen, wenn sie mit einem einzigen DPaaS-Anbieter zusammenarbeiten. Außerdem speichern Managed-Service- und Cloud-Service-Anbieter alle Daten eines Unternehmens, was Sicherheitsbedenken aufwerfen könnte. Anbieter sollten in der Lage sein, Daten während der Übertragung (Data in Flight) und im Ruhezustand (Data at Rest) als Teil ihrer DPaaS-Dienste zu verschlüsseln.
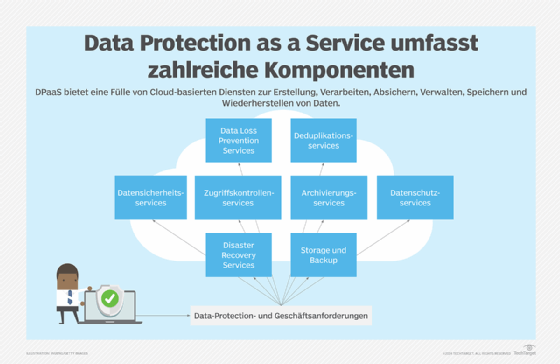
Zusätzlich zu den spezifischen Technologien für Data Protection sind Dutzende neuer Tools und Techniken entstanden, die Unternehmen bei der digitalen Transformation, der sicheren Migration ihrer Daten, Anwendungen und Workloads in die Cloud sowie beim besseren Schutz und der besseren Verwaltung ihrer Daten unterstützen. Neue Architekturen, Konzepte und Frameworks wie DataOps, Data Mesh, Lakehouse und Zero Trust haben an Dynamik gewonnen, um der zunehmenden Menge und Komplexität von Cybersicherheitsbedrohungen zu begegnen, den sicheren Fluss von E-Commerce-Kundendaten über mehrere Kanäle hinweg zu gewährleisten und gesetzliche Compliance-Vorgaben zu erfüllen.
Die Entwicklung von generativer KI, großen Sprachmodellen und Chatbot-Schnittstellen, die in der Lage sind, künstliche Inhalte zu erstellen, erhöht die Komplexität der Data Protection zusätzlich. Generative KI hat jedoch eine Reihe berechtigter Bedenken hinsichtlich des Datenschutzes aufgeworfen, darunter Datenqualität, Genauigkeit der Inhalte, Datenschutz, Plagiate, Urheberrechtsverletzungen, Voreingenommenheit (Bias) und Halluzinationen, die die Richtlinien und Verfahren zum Schutz von Geschäftsdaten verändern.
Data Protection vs. Datensicherung (Backup)
Backup-Systeme ermöglichen es Unternehmen, Kopien wichtiger Dateien, Anwendungen, Datenbanken und Systemkonfigurationen zu erstellen und diese an verschiedenen Orten zu speichern. Die Daten können dann wiederhergestellt und auf den aktuellen Stand gebracht werden, wenn sie aufgrund von menschlichem Versagen, Systemausfällen, Cyberangriffen oder Naturkatastrophen beschädigt wurden oder verloren gegangen sind, wodurch Ausfallzeiten minimiert werden. Die Datensicherung ist ein wichtiger Bestandteil der Business-Continuity- und Disaster-Recovery-Programme vieler Unternehmen.
Data Protection und Backups rücken angesichts der sich wandelnden Zusammensetzung von Netzwerken zunehmend in den Fokus. Ältere Backup-Systeme verwendeten physische Medien wie Bänder und Festplatten, doch heute setzen Unternehmen zunehmend auf SaaS-basierte Backup-as-a-Service-Lösungen. Zwar eignen sich nicht alle Daten für ein Cloud-Backup, aber zahlreiche Unternehmen nutzen die Cloud als Backup-Ziel, oft für weniger geschäftskritische Daten. Die Cloud bietet dabei verschiedene Recovery-Optionen.
Konvergenz von Backup und Disaster Recovery
Backup und Disaster Recovery (DR) sind eng miteinander verbunden, werden jedoch oft fälschlicherweise gleichgesetzt. Beim Backup werden Kopien von Daten, Anwendungen oder ganzen Systemumgebungen erstellt, um diese im Falle von Verlust, Beschädigung oder Angriff wiederherstellen zu können. Disaster Recovery hingegen umfasst den übergeordneten Plan und die Prozesse, mit denen ein Unternehmen nach einem schwerwiegenden Ausfall – etwa durch Hardwaredefekte, Naturkatastrophen oder Cyberangriffe – den Betrieb seiner IT-Systeme und Anwendungen schnell wieder aufnehmen kann.
Ein Unternehmen kann zwar Backups besitzen, ohne über einen DR-Plan zu verfügen – ein DR-Plan jedoch setzt immer aktuelle und verfügbare Backups oder andere Redundanzmechanismen voraus. Zu einem vollständigen DR-Konzept gehören zudem eine Kommunikationsstrategie, geschultes Personal, Monitoring sowie gegebenenfalls Ausweichrechenzentren oder Cloud-Ressourcen.
Viele moderne Cloud-Plattformen vereinen Backup, Recovery und zusätzliche Data-Protection-Funktionen in einer integrierten Lösung und unterstützen dabei gleichzeitig die Einhaltung branchenspezifischer Compliance-Vorgaben.
Data Protection für mobile Daten
Mobile Geräte wie Smartphones, Tablets und Laptops speichern eine Vielzahl sensibler Informationen, von Kontakten, E-Mails und Nachrichten über Standortdaten bis hin zu besonders schützenswerten Finanz- und Gesundheitsinformationen.
Mobile Data Protection (MDP) umfasst Technologien und Verfahren, mit denen diese Daten durch Verschlüsselung, Zugriffskontrolle und zentrale Verwaltung geschützt werden. MDP-Lösungen stützen sich dabei oft auf die nativen Sicherheitsfunktionen der Betriebssysteme (zum Beispiel BitLocker, FileVault, iOS-/Android-Geräteverschlüsselung), können diese aber auch durch zusätzliche Schutzmechanismen wie Passwortvorgaben, Zwei-Faktor-Authentifizierung oder Fernlöschung (Remote Wipe) ergänzen.
Für Unternehmen ist MDP eng mit Mobile Device Management (MDM) verbunden. Eine wirksame MDP-Strategie sollte mindestens drei Elemente berücksichtigen:
- Geräteverwaltung (Registrierung, Konfiguration, Remote Wipe)
- regelmäßige Betriebssystem- und App-Updates
- Schutz vor Malware und unsicheren Apps
Unternehmen sollten außerdem klar definieren, welche Gerätefunktionen geschäftlich notwendig sind und welche im Hinblick auf die Sicherheit eingeschränkt werden müssen.
Data-Protection- und Datenschutzbestimmungen
Vorschriften wie die Datenschutz-Grundverordnung (DSGVO) in der EU und Gesetze wie der California Consumer Privacy Act (CCPA) haben die Art und Weise, wie Unternehmen personenbezogene Daten erfassen, verarbeiten, speichern und löschen, grundlegend verändert. Im Mittelpunkt dieser Regelungen steht das Recht der betroffenen Personen, Kontrolle über ihre Daten zu behalten, einschließlich des Rechts auf Vergessenwerden.
Die Nichteinhaltung kann zu erheblichen Bußgeldern und Reputationsschäden führen, während eine konsequente Umsetzung von Datenschutzvorgaben auch als Wettbewerbsvorteil wirken kann.
Während die EU mit der DSGVO einen einheitlichen Rechtsrahmen geschaffen hat, existiert in den USA bislang kein nationales Datenschutzgesetz. Stattdessen gibt es eine Vielzahl einzelstaatlicher Regelungen (zum Beispiel den CCPA in Kalifornien). Mit dem American Privacy Rights Act of 2024 liegt jedoch seit Juni 2024 ein Entwurf für ein bundeseinheitliches Gesetz vor. Es sollte eine Ausschussberatung erfolgen, die Aber Ende Juni 2024 abgesagt wurde. Die Republikanische Parteiführungen gegen ein weiteres Voranschreiten des Gesetzes, was dazu führte, dass bislang (Stand September 2025) keine Verabschiedung vorliegt. Beobachter bewerten die Lage skeptisch: Der Gesetzesentwurf hat an Momentum verloren, und seine Erfolgsaussichten in dieser Legislaturperiode (2025 – 2029, unter dem republikanischen Präsidenten Trump) gelten als gering.
Auch international haben viele Länder eigene Datenschutzgesetze verabschiedet – etwa Brasilien, Kanada, Japan oder Indien (Digital Personal Data Protection Act, 2023). Damit orientieren sich zahlreiche Rechtsordnungen zunehmend an den Prinzipien der DSGVO.
Was sind die zentralen Prinzipien der Data Protection?
Data Protection umfasst im weiteren Sinn sämtliche Maßnahmen, die sensible Daten vor Verlust, Manipulation oder unbefugtem Zugriff schützen und zugleich ihre Verfügbarkeit sicherstellen – dazu gehören technische, organisatorische und prozessuale Vorkehrungen wie Backup, Disaster Recovery oder Datensicherheit.
Im engeren, rechtlichen Verständnis – insbesondere im europäischen Kontext – wird Data Protection häufig synonym mit Datenschutz verwendet. Maßgeblich ist hier die Datenschutz-Grundverordnung (DSGVO), die international als Goldstandard gilt. In Artikel 5 legt sie sieben Prinzipien für die Verarbeitung personenbezogener Daten fest. Diese Grundsätze richten sich zwar an Unternehmen, die in der EU tätig sind, adressieren aber universelle Herausforderungen im Umgang mit personenbezogenen Daten.
Die sieben Prinzipien sind:
1. Rechtmäßigkeit, Verarbeitung nach Treu und Glauben, Transparenz
Personenbezogene Daten müssen auf rechtmäßige, faire und transparente Weise verarbeitet werden.
2. Zweckbindung
Personenbezogene Daten dürfen nur für festgelegte, eindeutige und legitime Zwecke erhoben und nicht in einer mit diesen Zwecken unvereinbaren Weise weiterverarbeitet werden.
3. Datenminimierung
Personenbezogene Daten müssen dem Zweck angemessen und erheblich sowie auf das für die Verarbeitung notwendige Maß beschränkt sein.
4. Richtigkeit
Personenbezogene Daten müssen sachlich richtig und erforderlichenfalls auf dem neuesten Stand sein; unrichtige Daten sind unverzüglich zu löschen oder zu berichtigen.
5. Speicherbegrenzung
Personenbezogene Daten dürfen nur so lange gespeichert werden, wie es für die Zwecke erforderlich ist; längere Speicherungen sind nur zulässig, wenn sie allein wissenschaftlichen, historischen oder statistischen Zwecken dienen und durch geeignete Schutzmaßnahmen flankiert sind.
6. Integrität und Vertraulichkeit
Personenbezogene Daten müssen durch geeignete technische und organisatorische Maßnahmen vor unbefugter oder unrechtmäßiger Verarbeitung, Verlust oder Zerstörung geschützt werden.
7. Rechenschaftspflicht
Der Verantwortliche muss die Einhaltung aller vorstehenden Grundsätze nachweisen können.
Wie die Einhaltung der DSGVO die Data Protection verbessert
Für Unternehmen, die in EU-Mitgliedsstaaten tätig sind, bedeutet die Einhaltung der DSGVO nicht nur, regulatorische Anforderungen zu erfüllen und hohe Strafen zu vermeiden. Die Prinzipien und Zielsetzungen der DSGVO zielen zwar formal auf den Schutz personenbezogener Daten, wirken sich jedoch in der Praxis auch positiv auf breitere Data-Protection-Maßnahmen aus. Unternehmen werden dadurch gezwungen, interne Richtlinien und Verfahren einzuführen, die ihre Data Protection in mehreren zentralen Bereichen verbessern können – etwa Business Continuity, Data Governance, Backup und Recovery, Cloud-Migration, Transparenz und Nachvollziehbarkeit sowie Datenmonetarisierung.
Diese Bereiche sind für Data Protection aus folgenden Gründen entscheidend:
- Business Continuity: Verbesserte Notfall- und Wiederherstellungspläne erhöhen die Wahrscheinlichkeit, dass Unternehmen nach einer Datenpanne kritische Systeme und Abläufe schnell wiederherstellen können.
- Data Governance und Transparenz: Eine klare Governance-Strategie sowie Funktionen zur Nachvollziehbarkeit erleichtern das Auffinden, Verarbeiten und Absichern von Daten und machen die Prozesse skalierbarer – was zugleich die effiziente Nutzung und Monetarisierung von Datenressourcen ermöglicht.
- Vertrauensvorteil: Unternehmen, die die DSGVO einhalten, zeigen Regulierungsbehörden, Kunden und Partnern, dass sie Data Protection ernst nehmen und verantwortungsvoll mit personenbezogenen Daten umgehen. Dies kann das Markenvertrauen stärken und Wettbewerbsvorteile schaffen.
Grenzen der DSGVO im Bereich KI
Die prinzipienbasierte Herangehensweise der DSGVO hat sich in vielen Bereichen als wirksam erwiesen – was zahlreiche Bußgelder gegen globale Konzerne belegen (unter anderem Meta mit einer Rekordstrafe von 1,3 Milliarden USD im Jahr 2023, Amazon 2021, TikTok 2023 und Google zwischen 2019 und 2022).
Allerdings wird zunehmend deutlich, dass die DSGVO bei der Regulierung neuer Technologien wie künstlicher Intelligenz (KI), maschinellem Lernen und generativer KI an ihre Grenzen stößt. Kritisiert werden unter anderem:
- fehlende spezifische Vorgaben zum Umgang mit algorithmischen Verzerrungen (Bias) in Trainingsdaten.
- unklare Verantwortlichkeiten in komplexen KI-Lieferketten.
- das Fehlen einer direkten Adressierung gesellschaftlicher und ethischer Fragen über den reinen Datenschutz hinaus.
- die unzureichende Abdeckung branchenspezifischer Risiken.
Um diese Lücken zu schließen, hat die EU den Artificial Intelligence Act verabschiedet – einen neuen Rechtsrahmen, der speziell auf KI-Praktiken, Hochrisiko-Systeme, allgemeine KI-Modelle und deren Anwendung abzielt. Unternehmen sollten dennoch eng mit Fachberatern zusammenarbeiten, um die praktische Umsetzung und Auswirkungen dieser neuen Vorgaben zu bewerten.
Best Practices für Datenschutzstrategien im Rahmen von Data Protection
Datenschutz ist ein zentraler Bestandteil einer umfassenden Data-Protection-Strategie. Unternehmen stehen hier vor zahlreichen Herausforderungen, die eine Reihe von Best Practices erfordern, um die Grundprinzipien der Datenerhebung, -verarbeitung, -speicherung und -löschung einzuhalten und gleichzeitig die damit verbundenen Risiken zu verringern.
Vertrauen der Verbraucher
Misstrauen entsteht durch mangelnde Transparenz. Verbraucher wissen oft nicht, wie ihre Daten verwaltet und weitergegeben werden, und fragen sich, ob ihre Daten sicher sind. Unternehmen müssen Vertrauen aufbauen, indem sie Datenschutzvereinbarungen in klarer Sprache und in überschaubarer Länge verfassen, den Betroffenen möglichst umfassende Transparenz über die Verarbeitung ihrer Daten geben und einfache Opt-out-Optionen für die Nutzung ihrer Daten bereitstellen.
Fragmentierung von Gesetzen und Vorschriften
Unternehmen müssen sich mit einer Vielzahl von Datenschutzgesetzen und -vorschriften auseinandersetzen. Sie sollten ausreichend Ressourcen bereitstellen, um sicherzustellen, dass die betroffenen Stakeholder über regulatorische Anforderungen informiert sind und die Bedingungen für die Einwilligung der Verbraucher den gesetzlichen Bestimmungen entsprechen.
Diese Begriffe sind für Data Protection und Datenschutz wichtig
Was ist Continiuous Data Protection (CDP)?
Was ist ein Bundesdatenschutzbeauftragter (BfDI)?
Was ist ein Europäischer Datenschutzbeauftragter (EDBS)?
Daten-Governance
Unternehmen sind für den Datenschutz, die Einhaltung von Vorschriften und die kontinuierliche Überwachung verantwortlich. Governance sollte bei jeder neuen Dateninitiative im Vordergrund stehen. Dazu gehören ein Rahmenwerk mit Richtlinien und Standards für den Schutz personenbezogener Daten im gesamten Unternehmen, ein Überblick über vorhandene Daten und deren Nutzung sowie die Einrichtung eines Datenschutzgremiums zur Förderung der Zusammenarbeit.
Technologischer Umbruch
Technologie ist ein zweischneidiges Schwert in der Datenschutzpraxis. Sie ermöglicht Unternehmen, personenbezogene Daten besser zu schützen, bietet aber auch Angriffsflächen für Cyberkriminelle. Firmen müssen neue Technologien, ihre potenziellen Risiken und Möglichkeiten zur Risikominderung sorgfältig bewerten. Datenschutz sollte im Zentrum jeder Technologieentscheidung stehen. Zudem sollten Datenschutzkompetenz und Zusammenarbeit im gesamten Unternehmen gefördert werden, um überstürzte und unzureichend geprüfte Implementierungen zu vermeiden.
Datenverarbeitung
Um die wachsenden Mengen personenbezogener Daten zu bewältigen, müssen Unternehmen Datenschutzkontrollen in modernen Systemen operationalisieren und ältere Systeme nachrüsten. Daten sollten nur gesammelt, gespeichert und weitergegeben werden, wenn dies für den Geschäftsbetrieb erforderlich ist. Systeme sollten nach dem Prinzip Privacy by Design konzipiert und mit richtlinienbasierter Automatisierung unterstützt werden.
Einführung von KI
KI durchdringt nahezu alle Bereiche des Geschäftsbetriebs. Sie kann Prozesse optimieren, birgt jedoch erhebliche Risiken: unzureichende Sicherheitsvorkehrungen, algorithmische Verzerrungen und mangelnde Transparenz. Die Einführung generativer KI verstärkt diese Risiken zusätzlich. Unternehmen müssen die mit KI verbundenen Herausforderungen verstehen und mit Vorsicht vorgehen. Dazu gehören die Bewertung und laufende Überprüfung möglicher Verzerrungen in Trainings- und Produktionsdaten sowie die Abstimmung der KI-Systeme mit den Unternehmenswerten. Mit dem EU AI Act werden zudem spezifischere Vorgaben zur Regulierung von Hochrisiko- und generativen KI-Systemen geschaffen, die Unternehmen frühzeitig berücksichtigen sollten.

Entwicklung einer Data-Protection-Richtlinie
Um sensible Informationen zu schützen, eine Vielzahl regionaler Gesetze einzuhalten und hohe Strafen zu vermeiden, müssen Unternehmen interne Data-Protection-Policies entwickeln und implementieren, die sowohl die Geschäftsziele als auch die Datenschutzvorschriften berücksichtigen. Die Schritte zum Aufbau einer solchen Policy können so vielfältig sein wie die Arten von Daten, die erhoben werden, und die Datenschutzgesetze, die einzuhalten sind.
Vor der Entwicklung einer Data-Protection-Policy ist es wichtig, ein Data Privacy Audit durchzuführen – einen umfassenden Prüfprozess zur Bewertung des Umgangs der Organisation mit personenbezogenen Informationen. Dabei werden die erhobenen Daten, die Mittel der Verarbeitung sowie die eingesetzten Sicherheitsmaßnahmen kritisch überprüft. Der Umfang eines solchen Audits umfasst in der Regel Richtlinien, Verfahren und Praktiken, die sicherstellen, dass geltende Gesetze und Vorschriften wie die DSGVO oder auch (außerhalb Europas) der CCPA eingehalten werden.
Ein zentrales Instrument zur weiteren Bewertung der Sicherheit und des Schutzes geschäftskritischer Daten ist die Data Protection Impact Assessment (DPIA) – im Deutschen als Datenschutz-Folgenabschätzung bezeichnet. Die DSGVO schreibt diese Maßnahme verpflichtend vor, wenn eine Verarbeitung ein hohes Risiko für die Rechte und Freiheiten von Personen darstellt. Eine DPIA (zu deutsch: Datenschutz-Folgenabschätzung) trägt dazu bei, sicherzustellen, dass Daten verfügbar bleiben, ihre Integrität vor Angriffen geschützt ist und ihre Verfügbarkeit gewährleistet wird.
Data-Protection-Policies haben keine festgelegte Struktur und kein einheitliches Template. Das kann für Unternehmen von Vorteil sein, da jede Organisation unterschiedliche Ziele verfolgt. Dennoch unterliegen Unternehmen in derselben Region denselben gesetzlichen Anforderungen und grundlegenden Verpflichtungen zum Schutz personenbezogener Daten. Wichtige Bestandteile einer Data-Protection-Policy sind:
- die Angabe des Grundes für die Einführung der Policy im Hinblick auf strategische Unternehmensziele.
- das Bewusstsein für die jeweils geltenden Gesetze und Vorschriften, die den Umgang mit Daten in verschiedenen Umgebungen bestimmen.
- das Verständnis der vorhandenen Datentypen, ihrer Sensitivität sowie ihrer Aufbewahrung, Verwaltung und Nutzung.
- die klare Definition zentraler Begriffe, ein Überblick über Prozesse und die Rollen relevanter Stakeholder.
- gegebenenfalls die Einbindung von Fachleuten mit Erfahrung in der Planung und Umsetzung von Data-Protection-Policies.
- die regelmäßige Überprüfung der Policy – mindestens einmal jährlich oder bei Änderungen der Rechtslage –, um ihre Relevanz und Compliance sicherzustellen.
Essenzielle Schritte für den Aufbau einer Data-Protection-Richtlinie
1. Zielsetzung festlegen
- Warum wird die Policy erstellt?
- Strategische Unternehmensziele berücksichtigen
- Bezug zu Data Protection und Datenschutz (DSGVO)
2. Rechtliche Grundlagen prüfen
- DSGVO, nationale Datenschutzgesetze
- CCPA (falls international relevant)
- EU AI Act (bei KI-Anwendungen)
3. Dateninventar erstellen
- Welche Daten werden erhoben?
- Sensitivität der Daten prüfen (zum Beispiel personenbezogen, gesundheitsbezogen, finanziell)
- Speicherorte, Systeme, Cloud-Anwendungen erfassen
4. Rollen und Verantwortlichkeiten definieren
- Datenschutzbeauftragter / Data Protection Officer
- IT-Sicherheitsteam
- Fachabteilungen / Prozessverantwortliche
5. Prozesse und Maßnahmen bestimmen
- Datenverarbeitungskontrollen implementieren
- Privacy by Design / Privacy by Default berücksichtigen
- Backup und Recovery, Business Continuity
- DPIA / Datenschutz-Folgenabschätzung für risikoreiche Prozesse
6. Schulung und Awareness
- Mitarbeiterschulungen zum Datenschutz
- Sensibilisierung für KI, Cloud-Services und Datenzugriff
7. Überprüfung und Anpassung
- Regelmäßiges Review der Policy (mindestens jährlich)
- Anpassungen bei Gesetzesänderungen oder neuen Technologien
- Audit- und Kontrollmaßnahmen dokumentieren
Trends und Erwartungen im Bereich Data Protection
Unternehmen, Verbraucher und Regulierungsbehörden passen sich kontinuierlich an das komplexe und sich ständig verändernde Umfeld von Data Protection und Datenschutz an. Es ist zu erwarten, dass mehrere der folgenden Trends die Art und Weise beeinflussen werden, wie Unternehmen personenbezogene und sensible Daten erheben, verarbeiten, steuern, sichern und weitergeben:
- Künstliche Intelligenz (KI) als zweischneidiges Schwert: KI bietet Unternehmen neue und verbesserte Möglichkeiten, Daten zu schützen, gleichzeitig eröffnet sie aber Cyberkriminellen neue Wege, proprietäre Informationen zu stehlen oder zu kompromittieren.
- Schnelle Entwicklungen generativer KI: Unternehmen müssen ständig mit den nahezu täglichen Fortschritten generativer KI Schritt halten.
- Steigende Kosten für Data Protection: Mit zunehmenden Investitionen in Tools, Verfahren sowie in rechtliche und technische Expertise steigen die Ausgaben für Datenschutz- und Data-Protection-Maßnahmen.
- Zunahme gesetzlicher Regelungen: Mit der wachsenden Zahl nationaler und regionaler Datenschutzgesetze suchen Unternehmen nach klaren Vorgaben, insbesondere im Hinblick auf die Nutzung von KI.
- Einfluss der DSGVO: Wie die DSGVO die Wahrnehmung personenbezogener Daten bei Unternehmen und Verbrauchern verändert hat, könnten ihre Grundsätze auch die Entwicklung und den Einsatz von KI beeinflussen.
- Verbraucherbewusstsein: Technikaffine Konsumenten, unterstützt durch strengere Datenschutzregelungen, werden zunehmend die Kontrolle über ihre persönlichen Daten einfordern.
- US-amerikanische Gesetzgebung: Ein von Kongress diskutierter nationaler Datenschutzentwurf könnte, falls er verabschiedet wird, bestehende bundesstaatliche Regelungen überlagern und entweder für mehr Kohärenz oder für zusätzliche Verwirrung sorgen.
- Wandel in der gesellschaftlichen Wahrnehmung: Das Verständnis von Datenhoheit und Kontrolle entwickelt sich weiter, und Privacy by Default könnte zunehmend zur Norm werden.
- Digitales Sicherheits- und Ethikbewusstsein: Unternehmen werden ihren Fokus auf digitale Sicherheit und ethische Standards erhöhen und eine Kultur der Wertschätzung von Daten etablieren.
- Handel mit personenbezogenen Daten: Der Handel mit personenbezogenen Daten – ob freiwillig bereitgestellt oder gestohlen – entwickelt sich zu einem eigenen Wirtschaftszweig.
Data Protection: Das Allerwichtigste auf einen Blick
Data Protection ist ein umfassendes Konzept, das eng mit Datenschutz und Datensicherheit verbunden ist, jedoch einen größeren Anwendungsbereich umfasst. Es zielt darauf ab, digitale Informationen vor Verlust, Manipulation oder unbefugtem Zugriff zu schützen und gleichzeitig deren Verfügbarkeit für Geschäftsprozesse sicherzustellen.
Unternehmen setzen hierzu eine Kombination aus Technologien, Prozessen und organisatorischen Maßnahmen ein, darunter Backup, Recovery, Dateninventarisierung, Verschlüsselung und Data-Lifecycle-Management.
Data Protection unterstützt nicht nur die Einhaltung gesetzlicher Vorgaben und regulatorischer Anforderungen, sondern fördert auch die Business Continuity, die Nachvollziehbarkeit von Datenprozessen und den verantwortungsvollen Umgang mit sensiblen Informationen. Durch diese ganzheitliche Herangehensweise wird sichergestellt, dass Daten jederzeit geschützt, verfügbar und korrekt verwaltet sind – ein entscheidender Faktor für den Geschäftserfolg im digitalen Zeitalter.






