Buffer Overflow

Ein Buffer Overflow tritt auf, wenn ein Programm oder ein Prozess versucht, mehr Daten in einen Memory-Block (den Buffer) mit fester Länge zu schreiben, als der Buffer fassen kann. Buffer (zu deutsch Puffer) enthalten eine festgelegte Datenmenge; alle zusätzlichen Daten überschreiben Datenwerte in Memory-Adressen, die an den Zielpuffer angrenzen. Diese Art von Überlauf (Overflow) kann vermieden werden, wenn das Programm eine ausreichende Überprüfung der Grenzen vorsieht, um Daten zu kennzeichnen oder zu verwerfen, wenn zu viele Daten an einen Memory Buffer gesendet werden.
Funktionsweise des Buffer Overflow
Die Ausnutzung eines Buffer Overflow ermöglicht es einem Angreifer, einen Prozess zu kontrollieren, zum Absturz zu bringen oder seine internen Variablen zu verändern. Buffer Overflows stehen in der Common Weakness Enumeration (CWE) und den SANS Top 25 Most Dangerous Software Errors immer ganz oben auf der Liste. Ein klassischer Buffer Overflow ist im CWE-Wörterbuch der Schwachstellenarten als CWE-120 aufgeführt. Obwohl er gut bekannt ist, werden Buffer Overflows immer wieder von großen und kleinen Softwareherstellern beklagt.
Ein Buffer Overflow kann versehentlich auftreten oder von einem böswilligen Akteur verursacht werden. Ein Angreifer kann sorgfältig gestaltete Eingaben - so genannten beliebigen Code - an ein Programm senden. Das Programm versucht, die Eingabe in einem Buffer zu speichern, der nicht groß genug für die Eingabe ist. Wenn die überschüssigen Daten dann in das angrenzenden Memory geschrieben werden, überschreiben sie alle dort bereits vorhandenen Daten.
Die ursprünglichen Daten im Buffer enthalten den Rückgabezeiger (Return Pointer) der angegriffenen Funktion - die Adresse, zu der der Prozess als nächstes gehen sollte. Der Angreifer kann jedoch neue Werte setzen, die auf eine Adresse seiner Wahl zeigen. In der Regel setzt der Angreifer die neuen Werte an eine Stelle, an der sich die Nutzlast des Exploitsbefindet. Durch diese Änderung wird der Ausführungspfad des Prozesses geändert und die Kontrolle an den bösartigen Code des Angreifers übertragen.
Nehmen wir zum Beispiel an, ein Programm wartet darauf, dass der Benutzer seinen Namen eingibt. Anstatt den Namen einzugeben, würde der Hacker einen ausführbaren Befehl eingeben, der die Stack-Größe überschreitet. Der Befehl ist in der Regel etwas Kurzes. In einer Linux-Umgebung ist der Befehl beispielsweise typischerweise EXEC(„sh“), der das System anweist, ein Eingabeaufforderungsfenster zu öffnen, in Linux-Kreisen als Root-Shell bekannt.
Das Überlaufen des Puffers mit einem ausführbaren Befehl bedeutet jedoch nicht, dass der Befehl auch ausgeführt wird. Der Angreifer muss eine Rückführungsadresse (Return Address) angeben, die auf den bösartigen Befehl verweist. Das Programm stürzt teilweise ab, weil der Stack übergelaufen ist. Es versucht dann, sich zu erholen, indem es zur Rückführungsadresse geht, aber diese wurde so geändert, dass sie auf den vom Hacker angegebenen Befehl verweist. Der Hacker muss die Adresse kennen, an der sich der böswillige Befehl befinden wird.
Um die tatsächliche Adresse zu umgehen, wird der bösartige Befehl oft auf beiden Seiten mit NOP-Befehlen (No Operation), einer Art Zeiger (Pointer), aufgefüllt. Das Auffüllen auf beiden Seiten ist eine Technik, die verwendet wird, wenn der genaue Memory-Bereich unbekannt ist. Wenn die Adresse, die der Hacker angibt, irgendwo innerhalb der Auffüllung liegt, wird der bösartige Befehl ausgeführt.
Programmiersprachen wie C und C++ haben keinen Schutz gegen den Zugriff auf oder das Überschreiben von Daten in einem beliebigen Teil des Memory. Daher sind sie anfällig für Buffer-Overflow-Angriffe. Böswillige Hacker können mit gängigen Programmierkonstrukten direkte Memory-Manipulationen vornehmen.
Moderne Programmiersprachen wie C#, Java und Perl verringern die Wahrscheinlichkeit, dass Programmierfehler zu Schwachstellen im Buffer Overflow führen. Dennoch können Buffer Overflows in jeder Programmierumgebung auftreten, in der eine direkte Memory-Manipulation möglich ist, sei es durch Fehler im Programm-Compiler, in den Runtime-Bibliotheken oder in der Sprache selbst.
Arten von Buffer-Overflow-Angriffen
Die Techniken zur Ausnutzung von Buffer-Overflow-Schwachstellen variieren je nach Betriebssystem (OS) und Programmiersprache. Das Ziel ist jedoch immer, den Arbeitsspeicher (Memory) eines Computers zu manipulieren, um die Programmausführung zu untergraben oder zu kontrollieren.
Buffer Overflows werden nach der Position des Puffers im Prozess-Memory kategorisiert. Meistens handelt es sich um Stack-basierte Overflows oder Heap-basierte Overflows. Beide befinden sich im RAM eines Geräts.
Einige Arten von Pufferüberlaufangriffen sind die folgenden.
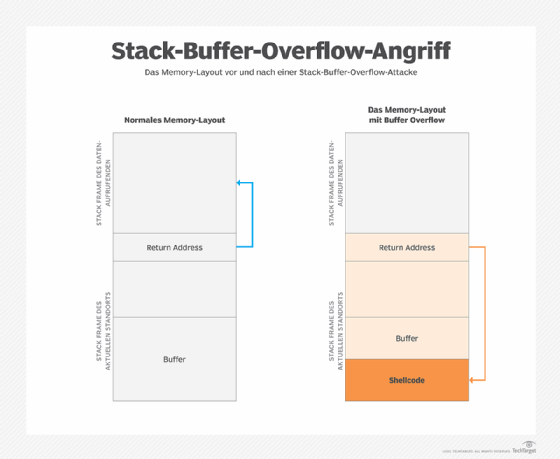
Stack-basierter Buffer Overflow oder Stack-Buffer-Overrun-Angriff
Der Stack speichert Daten in einer Last-in-First-out-Struktur. Es handelt sich dabei um einen kontinuierlichen Memory-Bereich, in dem die mit Funktionsaufrufen verbundenen Daten organisiert werden, einschließlich Funktionsparameter, lokale Funktionsvariablen und Verwaltungsinformationen wie Frame- und Befehlszeiger. Normalerweise ist der Stack leer, bis das Zielprogramm eine Benutzereingabe verlangt, zum Beispiel einen Benutzernamen oder ein Passwort. Zu diesem Zeitpunkt schreibt das Programm eine Rückführungsadresse in den Stack, und dann wird die Benutzereingabe darüber gelegt. Wenn der Stack verarbeitet wird, wird die Benutzereingabe an die vom Programm angegebene Rückführungsadresse gesendet.
Ein Stack hat jedoch eine begrenzte Größe. Der Programmierer, der den Code entwickelt, muss eine bestimmte Menge an Platz für den Stack reservieren. Wenn die Eingaben des Benutzers länger sind als der für sie reservierte Platz auf dem Stack und das Programm nicht überprüft, ob die Eingaben hineinpassen, läuft der Stack über. Dies ist an sich kein großes Problem, wird aber zu einer großen Sicherheitslücke, wenn es mit böswilligen Eingaben kombiniert wird.
Heap-basierter Buffer-Overflow-Angriff
Der Heap ist eine Memory-Struktur, die zur Verwaltung des dynamischen Arbeitsspeichers verwendet wird. Programmierer verwenden den Heap häufig, um Memory zuzuweisen, dessen Größe zum Zeitpunkt der Kompilierung nicht bekannt ist, wenn die benötigte Memory-Menge zu groß ist, um auf den Stack zu passen, oder wenn der Arbeitsspeicher für mehrere Funktionsaufrufe verwendet werden soll. Heap-basierte Angriffe überfluten den für ein Programm oder einen Prozess reservierten Speicherplatz im Memory. Heap-basierte Schwachstellen, wie der Anfang 2021 in Google Chrome entdeckte Zero-Day-Bug, sind schwer auszunutzen und daher seltener als Stack-Angriffe.
Integer-Overflow-Angriff
In den meisten Programmiersprachen sind Maximalgrößen für ganze Zahlen (Integer) definiert. Wenn diese Größen überschritten werden, kann das Ergebnis einen Fehler verursachen, oder es kann ein falsches Ergebnis innerhalb der Integer-Längengrenze zurückgegeben werden. Ein Integer-Overflow-Angriff kann auftreten, wenn eine ganze Zahl in einer arithmetischen Operation verwendet wird und das Ergebnis der Berechnung ein Wert ist, der die maximale Größe der ganzen Zahl überschreitet. Zum Beispiel werden 8 Bits an Memory benötigt, um die Zahl 192 zu speichern. Wenn der Prozess 64 zu dieser Zahl addiert, passt die Antwort 256 nicht in den zugewiesenen Arbeitsspeicher, da sie 9 Bits benötigt.
Angriff mit Formatierungszeichenfolgen
Angreifer verändern den Ablauf einer Anwendung, indem sie Funktionen der String-Formatierungsbibliothek, wie printf und sprintf, missbrauchen, um auf andere Memory-Bereiche zuzugreifen und diese zu manipulieren.
Unicode-Overflow-Angriffe
Diese Angriffe machen sich zunutze, dass für die Speicherung einer Zeichenkette im Unicode-Format mehr Memory-Platz benötigt wird als für ASCII-Zeichen (American Standard Code for Information Interchange). Sie können gegen Programme eingesetzt werden, die alle Eingaben als ASCII-Zeichen erwarten.
Wie man Buffer-Overflow-Angriffe verhindert
Es gibt mehrere Möglichkeiten, Buffer-Overflow-Angriffe zu verhindern, darunter die folgenden fünf:
- Verwenden Sie den Laufzeitschutz (Runtime Protection) des Betriebssystems. Die meisten Betriebssysteme verwenden diese Maßnahmen wie die folgenden, um den Erfolg von Buffer-Overflow-Angriffen zu erschweren:
Address Space Layout Randomization (ASLR) ordnet die Adressraumpositionen der wichtigsten Datenbereiche eines Prozesses zufällig an. Dazu gehören die Basis der ausführbaren Datei und die Positionen von Stack, Heap und Bibliotheken. Dieser Ansatz macht es einem Angreifer schwer, zuverlässig zu einer bestimmten Funktion im Memory zu springen.Die Datenausführungsverhinderung (Data Execution Prevention) markiert Memory-Bereiche entweder als ausführbar oder als nicht ausführbar. Dadurch wird verhindert, dass ein Angreifer Anweisungen ausführen kann, die über einen Buffer Overflow in einen Datenbereich geschrieben wurden.
Structured Exception Handling Overwrite Protection wurde entwickelt, um Angriffe zu blockieren, die die Structured Exception Handler-Überschreibetechnik verwenden, bei der ein Stack-basierter Pufferüberlauf verwendet wird. - Halten Sie die Geräte gepatcht. Die Hersteller geben Software-Patches und -Updates heraus, um entdeckte Pufferüberlaufschwachstellen zu beheben. Zwischen der Entdeckung der Schwachstelle und der Erstellung und Bereitstellung des Patches besteht immer noch ein gewisses Risiko.
- Befolgen Sie das Prinzip der geringsten Privilegien (Principle Of Least Privileges, POLP). Benutzer und Anwendungen sollten nur die Berechtigungen erhalten, die sie für ihre Arbeit oder die Ausführung der ihnen zugewiesenen Aufgaben benötigen. Die Befolgung eines POLP-Ansatzes verringert die Wahrscheinlichkeit eines Pufferüberlaufs. Im obigen Beispiel eines Stack Overflows wird das geöffnete Eingabeaufforderungsfenster mit denselben Berechtigungen ausgeführt wie die Anwendung, die kompromittiert wurde; je weniger Berechtigungen es hat, desto weniger hat der Angreifer. Gewähren Sie Benutzern und Anwendungen nach Möglichkeit nur temporäre Berechtigungen und nehmen Sie diese zurück, sobald die Aufgabe erledigt ist.
- Verwenden Sie Memory-sichere Programmiersprachen. Der häufigste Grund für Pufferüberlauf-Angriffe ist, dass Anwendungen es versäumen, Memory-Zuweisungen zu verwalten und Eingaben vom Client oder anderen Prozessen zu validieren. Anwendungen, die in C oder C++ entwickelt wurden, sollten gefährliche Standardbibliotheksfunktionen vermeiden, die nicht auf ihre Beschränkungen hin überprüft werden, wie gets, scanf und strcpy. Stattdessen sollten sie Bibliotheken oder Klassen verwenden, die für die sichere Ausführung von String- und anderen Memory-Operationen konzipiert wurden. Noch besser ist es, eine Programmiersprache zu verwenden, die die Gefahr eines Pufferüberlaufs verringert, beispielsweise mit Java, Python oder C#.
- Validieren Sie Daten. Eigenentwickelte Mobil- und Webanwendungen sollten stets alle Benutzereingaben und Daten aus nicht vertrauenswürdigen Quellen validieren, um sicherzustellen, dass sie sich im Rahmen des Erwarteten bewegen und um zu lange Eingabewerte zu vermeiden. Jede Sicherheitsrichtlinie für Anwendungen sollte vor der Bereitstellung Schwachstellentests für potenzielle Schwachstellen bei der Eingabevalidierung und bei Pufferüberläufen vorsehen.







