Black-Box-KI
Was ist Black-Box-KI?
Black-Box-KI ist ein System der künstlichen Intelligenz (KI), dessen Eingaben und Vorgänge für den Benutzer oder eine andere interessierte Partei nicht sichtbar sind. Eine Black Box ist im Allgemeinen ein undurchdringliches System.
Black-Box-KI-Modelle kommen zu Schlussfolgerungen oder Entscheidungen, ohne zu erklären, wie sie zu diesen gelangt sind.
Im Zuge der Weiterentwicklung der KI-Technologie haben sich zwei Haupttypen von KI-Systemen herausgebildet: Black-Box-KI und erklärbare (oder White-Box-) KI. Der Begriff Black Box bezieht sich auf Systeme, die für Benutzer nicht transparent sind. Einfach ausgedrückt sind KI-Systeme, deren interne Funktionsweise, Entscheidungsabläufe und Einflussfaktoren für menschliche Benutzer nicht sichtbar sind oder unbekannt bleiben, als Black-Box-KI-Systeme bekannt.
Die mangelnde Transparenz erschwert es Menschen, zu verstehen oder zu erklären, wie das dem System zugrunde liegende Modell zu seinen Schlussfolgerungen gelangt. Black-Box-KI-Modelle können auch Probleme im Zusammenhang mit Flexibilität (Aktualisierung des Modells bei sich ändernden Anforderungen), Voreingenommenheit (falsche Ergebnisse, die einige Gruppen von Menschen beleidigen oder schädigen können), Genauigkeitsvalidierung (schwierig zu validieren oder den Ergebnissen zu vertrauen) und Sicherheit (unbekannte Schwachstellen machen das Modell anfällig für Cyberangriffe) verursachen.
Wie funktionieren Black-Box-Modelle für maschinelles Lernen?
Bei der Entwicklung eines maschinellen Lernmodells nimmt der Lernalgorithmus Millionen von Datenpunkten als Eingaben und korreliert spezifische Datenmerkmale, um Ausgaben zu erzeugen.
Der Prozess umfasst in der Regel folgende Schritte:
- Ausgefeilte KI-Algorithmen untersuchen umfangreiche Datensätze, um Muster zu finden. Um dies zu erreichen, nimmt der Algorithmus eine große Anzahl von Datenbeispielen auf, sodass er selbstständig durch Versuch und Irrtum experimentieren und lernen kann. Je mehr Trainingsdaten das Modell erhält, desto mehr lernt es, seine internen Parameter zu ändern, bis es einen Punkt erreicht, an dem es die genaue Ausgabe für neue Eingaben vorhersagen kann.
- Als Ergebnis dieses Trainings ist das Modell schließlich in der Lage, Vorhersagen anhand von Daten aus der realen Welt zu treffen. Die Betrugserkennung mithilfe einer Risikobewertung ist ein Beispiel für die Anwendung dieses Mechanismus.
- Das Modell skaliert seine Methode, Ansätze und sein Wissensspektrum und erzeugt dann nach und nach bessere Ergebnisse, wenn im Laufe der Zeit zusätzliche Daten gesammelt und ihm zugeführt werden.
In vielen Fällen sind die inneren Abläufe von Black-Box-Modellen für maschinelles Lernen nicht ohne Weiteres verfügbar und weitgehend selbstgesteuert. Deshalb ist es für Datenwissenschaftler, Programmierer und Benutzer schwierig zu verstehen, wie das Modell seine Vorhersagen generiert, oder der Genauigkeit und Richtigkeit seiner Ergebnisse zu vertrauen.
Wie funktionieren Black-Box-Deep-Learning-Modelle?
Viele Black-Box-KI-Modelle basieren auf Deep Learning, einem Zweig der KI – insbesondere einem Zweig des maschinellen Lernens –, bei dem mehrschichtige oder tiefe neuronale Netze verwendet werden, um das menschliche Gehirn nachzuahmen und seine Entscheidungsfähigkeit zu simulieren. Die neuronalen Netze bestehen aus mehreren Schichten miteinander verbundener Knoten, die als künstliche Neuronen bezeichnet werden.
In Black-Box-Modellen verteilen diese tiefen Netzwerke künstlicher Neuronen Daten und Entscheidungsfindung auf Zehntausende oder mehr Neuronen. Die Neuronen arbeiten zusammen, um die Daten zu verarbeiten und darin Muster zu erkennen, sodass das KI-Modell Vorhersagen treffen und zu bestimmten Entscheidungen oder Antworten gelangen kann.
Diese Vorhersagen und Entscheidungen führen zu einer Komplexität, die genauso schwer zu verstehen sein kann wie die Komplexität des menschlichen Gehirns. Wie bei Modellen des maschinellen Lernens ist es für Menschen schwierig, das Wie eines Deep-Learning-Modells zu erkennen, das heißt die spezifischen Schritte, die es unternommen hat, um diese Vorhersagen zu treffen oder zu diesen Entscheidungen zu gelangen. Aus all diesen Gründen werden solche Deep-Learning-Systeme als Black-Box-KI-Systeme bezeichnet.
Probleme mit Black-Box-KI
Während Black-Box-KI-Modelle unter bestimmten Umständen angemessen und äußerst wertvoll sind, können sie auch einige Probleme mit sich bringen.
1. KI-Voreingenommenheit (KI-Bias)
KI-Voreingenommenheit kann in Algorithmen für maschinelles Lernen oder neuronale Netze für Deep Learning als Ausdruck bewusster oder unbewusster Vorurteile seitens der Entwickler eingeführt werden. Voreingenommenheit kann sich auch durch unentdeckte Fehler oder durch Trainingsdaten einschleichen, wenn Details über den Datensatz nicht erkannt werden. In der Regel sind die Ergebnisse eines voreingenommenen KI-Systems verzerrt oder schlichtweg falsch, möglicherweise in einer Weise, die für einige Menschen oder Gruppen beleidigend, unfair oder geradezu gefährlich ist.
Beispiel
Ein KI-System, das für die IT-Rekrutierung eingesetzt wird, kann sich auf historische Daten stützen, um Personalteams bei der Auswahl von Kandidaten für Vorstellungsgespräche zu unterstützen. Da jedoch in der Vergangenheit die meisten IT-Mitarbeiter männlich waren, könnte der KI-Algorithmus diese Informationen nutzen, um nur männliche Kandidaten zu empfehlen, selbst wenn der Pool potenzieller Kandidaten qualifizierte Frauen umfasst. Einfach ausgedrückt zeigt er eine Voreingenommenheit gegenüber männlichen Bewerbern und diskriminiert weibliche Bewerber. Ähnliche Probleme könnten bei anderen Gruppen auftreten, zum Beispiel bei Bewerbern aus bestimmten ethnischen Gruppen, religiösen Minderheiten oder Einwanderergruppen.
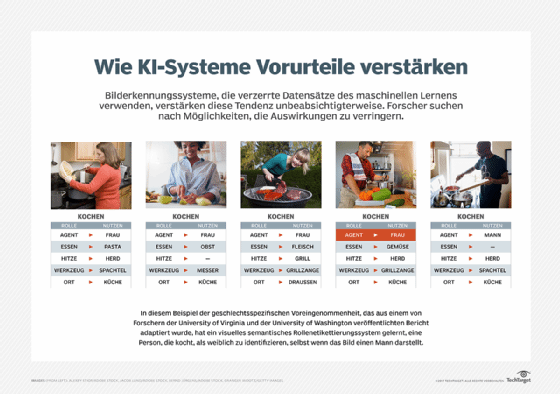
Bei Black-Box-KI ist es schwierig zu erkennen, woher die Voreingenommenheit kommt oder ob die Modelle des Systems unvoreingenommen sind. Wenn die inhärente Voreingenommenheit zu durchweg verzerrten Ergebnissen führt, kann dies dem Ruf der Organisation, die das System einsetzt, schaden. Es könnte auch zu Klagen wegen Diskriminierung führen. Voreingenommenheit in Black-Box-KI-Systemen kann auch soziale Kosten verursachen und zur Marginalisierung, Belästigung, unrechtmäßigen Inhaftierung und sogar zu Verletzungen oder zum Tod bestimmter Personengruppen führen.
Um solche schädlichen Folgen zu verhindern, müssen KI-Entwickler Transparenz in ihre Algorithmen einbauen. Es ist auch wichtig, dass sie die KI-Vorschriften einhalten, sich für Fehler verantwortlich zeigen und sich für die Förderung einer verantwortungsvollen Entwicklung und Nutzung von KI einsetzen.
In einigen Fällen können Techniken wie Sensitivitätsanalysen und Merkmalsvisualisierungen eingesetzt werden, um einen Einblick in die Funktionsweise der internen Prozesse des KI-Modells zu erhalten. Dennoch bleiben diese Prozesse in den meisten Fällen undurchsichtig.
2. Mangel an Transparenz und Verantwortlichkeit
Die Komplexität von Black-Box-KI-Modellen kann Entwickler daran hindern, sie richtig zu verstehen und zu prüfen, selbst wenn sie genaue Ergebnisse liefern. Einige KI-Experten, selbst diejenigen, die an einigen der bahnbrechendsten Errungenschaften auf dem Gebiet der KI beteiligt waren, verstehen nicht vollständig, wie diese Modelle funktionieren. Ein solches Unverständnis führt zu einer geringeren Transparenz und minimiert das Verantwortungsbewusstsein.
Diese Probleme können in Bereichen mit hohen Risiken wie dem Gesundheitswesen, dem Bankwesen, dem Militär und der Strafjustiz äußerst problematisch sein. Da man den von diesen Modellen getroffenen Entscheidungen nicht trauen kann, können die letztendlichen Auswirkungen auf das Leben der Menschen weitreichend sein, und das nicht immer auf positive Weise. Es kann auch schwierig sein, Einzelpersonen für die Urteile des Algorithmus zur Verantwortung zu ziehen, wenn dieser unklare Modelle verwendet.
3. Mangelnde Flexibilität
Ein weiteres großes Problem bei Black-Box-KI ist ihre mangelnde Flexibilität. Wenn das Modell für einen anderen Anwendungsfall geändert werden muss – beispielsweise um ein anderes, aber physisch vergleichbares Objekt zu beschreiben –, kann die Festlegung der neuen Regeln oder Massenparameter für die Aktualisierung viel Arbeit erfordern.
4. Ergebnisse schwer zu validieren
Die Ergebnisse, die eine Black-Box-KI generiert, sind oft schwer zu validieren und zu replizieren. Wie ist das Modell zu diesem bestimmten Ergebnis gekommen? Warum ist es nur zu diesem Ergebnis gekommen und zu keinem anderen? Woher wissen wir, dass dies die beste/korrekteste Antwort ist? Es ist fast unmöglich, Antworten auf diese Fragen zu finden und sich auf die generierten Ergebnisse zu verlassen, um menschliche Handlungen oder Entscheidungen zu unterstützen. Dies ist einer der Gründe, warum es nicht ratsam ist, sensible Daten mit einem Black-Box-KI-Modell zu verarbeiten.
5. Sicherheitsmängel
Black-Box-KI-Modelle weisen häufig Mängel auf, die Bedrohungsakteure ausnutzen können, um die Eingabedaten zu manipulieren. Sie könnten beispielsweise die Daten ändern, um das Urteil des Modells zu beeinflussen, sodass es falsche oder sogar gefährliche Entscheidungen trifft. Da es keine Möglichkeit gibt, den Entscheidungsprozess des Modells rückzuentwickeln, ist es fast unmöglich, es davon abzuhalten, falsche Entscheidungen zu treffen.
Es ist auch schwierig, andere Sicherheitslücken zu identifizieren, die das KI-Modell betreffen. Eine häufige Sicherheitslücke entsteht durch Dritte, die Zugriff auf die Trainingsdaten des Modells haben. Wenn diese Parteien keine bewährten Sicherheitspraktiken zum Schutz der Daten befolgen, ist es schwierig, sie vor Cyberkriminellen zu schützen, die sich möglicherweise unbefugten Zugriff verschaffen, um das Modell zu manipulieren und seine Ergebnisse zu verfälschen.
Wann sollte Black-Box-KI eingesetzt werden?
Obwohl Black-Box-KI-Modelle viele Herausforderungen mit sich bringen, bieten sie auch Vorteile:
- Höhere Genauigkeit. Komplexe Black-Box-Systeme können eine höhere Vorhersagegenauigkeit bieten als interpretierbarere Systeme, insbesondere in der Computer Vision und der Verarbeitung natürlicher Sprache, da sie komplizierte Muster in den Daten erkennen können, die für den Menschen nicht ohne Weiteres erkennbar sind. Dennoch sind die Algorithmen aufgrund ihrer Genauigkeit hochkomplex, was sie auch weniger transparent machen kann.
- Schnelle Schlussfolgerungen. Black-Box-Modelle basieren oft auf einem festen Satz von Regeln und Gleichungen, wodurch sie schnell ausgeführt und leicht optimiert werden können. So kann beispielsweise die Berechnung der Fläche unter einer Kurve mit einem Algorithmus zur Anpassung der kleinsten Quadrate die richtige Antwort liefern, auch wenn das Modell das Problem nicht vollständig versteht.
- Minimale Rechenleistung. Viele Black-Box-Modelle sind ziemlich einfach, sodass sie nicht viele Rechenressourcen benötigen.
- Automatisierung. Black-Box-KI-Modelle können komplexe Entscheidungsprozesse automatisieren und so den Bedarf an menschlicher Intervention reduzieren. Dies spart Zeit und Ressourcen und verbessert gleichzeitig die Effizienz von Prozessen, die bisher ausschließlich manuell durchgeführt wurden.
Im Allgemeinen wird der Black-Box-KI-Ansatz typischerweise in tiefen neuronalen Netzen verwendet, bei denen das Modell auf großen Datenmengen trainiert wird und die internen Gewichte und Parameter der Algorithmen entsprechend angepasst werden. Solche Modelle sind in bestimmten Anwendungen effektiv, darunter Bild- und Spracherkennung, bei denen das Ziel darin besteht, Daten genau und schnell zu klassifizieren oder zu identifizieren.
Black-Box-KI versus White-Box-KI
Black-Box-KI und White-Box-KI sind unterschiedliche Ansätze zur Entwicklung von KI-Systemen. Die Wahl eines bestimmten Ansatzes hängt von den spezifischen Anwendungen und Zielen des Endsystems ab. White-Box-KI wird auch als erklärbare KI (Explainable AI oder XAI) bezeichnet.
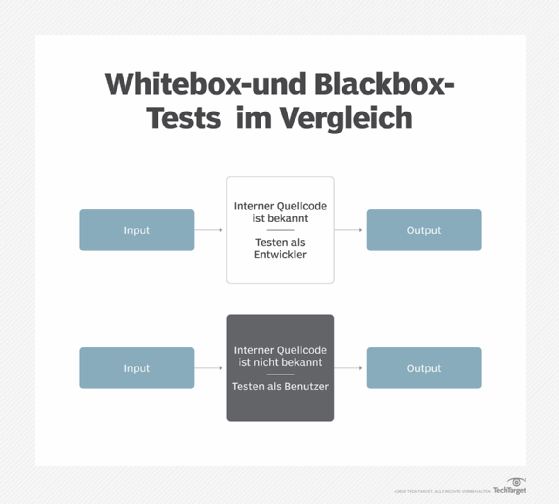
XAI wird so erstellt, dass eine typische Person ihre Logik und ihren Entscheidungsprozess verstehen kann. Abgesehen davon, dass menschliche Benutzer verstehen, wie das KI-Modell funktioniert und zu bestimmten Antworten gelangt, können sie auch den Ergebnissen des KI-Systems vertrauen. Aus all diesen Gründen ist XAI das Gegenteil von Black-Box-KI.
Während die Ein- und Ausgaben eines Black-Box-KI-Systems bekannt sind, ist seine interne Funktionsweise nicht transparent oder schwer zu verstehen. White-Box-KI ist transparent, wie sie zu ihren Schlussfolgerungen kommt. Ihre Ergebnisse sind auch interpretierbar und erklärbar, sodass Datenwissenschaftler einen White-Box-Algorithmus untersuchen und dann bestimmen können, wie er sich verhält und welche Variablen sein Urteil beeinflussen.
Da die internen Abläufe eines White-Box-Systems für Benutzer verfügbar und leicht verständlich sind, wird dieser Ansatz häufig in Anwendungen zur Entscheidungsfindung eingesetzt, zum Beispiel in der medizinischen Diagnose oder in der Finanzanalyse, wo es wichtig ist zu wissen, wie die KI zu ihren Schlussfolgerungen gelangt ist.
Erklärbare oder White-Box-KI ist aus vielen Gründen der wünschenswertere KI-Typ.
Erstens ermöglicht es den Entwicklern, Ingenieuren und Datenwissenschaftlern des Modells, das Modell zu überprüfen und zu bestätigen, dass das KI-System wie erwartet funktioniert. Wenn nicht, können sie bestimmen, welche Änderungen erforderlich sind, um die Leistung des Systems zu verbessern.
Zweitens ermöglicht ein erklärbares KI-System denjenigen, die von seiner Leistung oder seinen Entscheidungen betroffen sind, das Ergebnis in Frage zu stellen, insbesondere wenn die Möglichkeit besteht, dass das Ergebnis auf einer im KI-Modell eingebauten Voreingenommenheit beruht.
Drittens erleichtert die Erklärbarkeit die Sicherstellung, dass das System den regulatorischen Standards entspricht, von denen viele in den letzten Jahren entstanden sind – der EU AI Act ist ein bekanntes Beispiel –, um die negativen Auswirkungen von KI zu minimieren. Dazu gehören Risiken für den Datenschutz, KI-Halluzinationen, die zu falschen Ergebnissen führen, Datenschutzverletzungen, die Regierungen oder Unternehmen betreffen, und die Verbreitung von Audio- oder Video-Deepfakes, die zur Verbreitung von Fehlinformationen führen.
Schließlich ist die Erklärbarkeit für die Umsetzung einer verantwortungsvollen KI von entscheidender Bedeutung. Verantwortungsvolle KI bezieht sich auf KI-Systeme, die sicher, transparent und rechenschaftspflichtig sind und auf ethische Weise eingesetzt werden, um vertrauenswürdige und zuverlässige Ergebnisse zu erzielen. Das Ziel einer verantwortungsvollen KI ist es, positive Ergebnisse zu erzielen und Schäden zu minimieren.
Hier ist eine Zusammenfassung der Unterschiede zwischen Black-Box-KI und White-Box-KI:
- Black-Box-KI ist oft genauer und effizienter als White-Box-KI.
- White-Box-KI ist leichter zu verstehen als Black-Box-KI.
- Black-Box-Modelle umfassen Boosting- und Random-Forest-Modelle, die von Natur aus stark nichtlinear und schwieriger zu erklären sind.
- White-Box-KI ist aufgrund ihrer transparenten, interpretierbaren Natur leichter zu debuggen und zu beheben.
- Lineare Modelle, Entscheidungsbäume und Regressionsbäume sind allesamt White-Box-KI-Modelle.
Mehr über verantwortungsvolle KI
KI, die auf moralisch integre und sozial verantwortliche Weise entwickelt und eingesetzt wird, wird als verantwortungsvolle KI bezeichnet. Dabei geht es darum, den KI-Algorithmus verantwortlich zu machen, bevor er Ergebnisse generiert. Die Leitprinzipien und bewährten Verfahren verantwortungsvoller KI zielen darauf ab, die negativen finanziellen, rufschädigenden und ethischen Risiken zu verringern, die Black-Box-KI mit sich bringen kann. Auf diese Weise kann verantwortungsvolle KI sowohl KI-Produzenten als auch KI-Konsumenten unterstützen.
KI-Praktiken gelten als verantwortungsvoll, wenn sie diese Grundsätze einhalten:
- Fairness. Das KI-System behandelt alle Menschen und demografischen Gruppen fair und verstärkt oder verschärft keine bereits bestehenden Vorurteile oder Diskriminierungen.
- Transparenz. Das System ist sowohl für seine Benutzer als auch für die Betroffenen leicht verständlich und erklärbar. Darüber hinaus müssen KI-Entwickler offenlegen, wie die für das Training eines KI-Systems verwendeten Daten gesammelt, gespeichert und verwendet werden.
- Rechenschaftspflicht. Die Organisationen und Personen, die KI erstellen und verwenden, sollten für die Urteile und Entscheidungen des KI-Systems verantwortlich gemacht werden.
- Kontinuierliche Weiterentwicklung. Eine ständige Überwachung ist notwendig, um sicherzustellen, dass die Ergebnisse stets mit moralischen KI-Konzepten und gesellschaftlichen Normen übereinstimmen.
- Menschliche Aufsicht. Jedes KI-System sollte so konzipiert sein, dass es eine menschliche Überwachung und Intervention ermöglicht, wenn dies angebracht ist.
Wenn KI sowohl erklärbar als auch verantwortungsbewusst ist, ist es wahrscheinlicher, dass sie einen positiven Einfluss auf die Menschheit hat.







