Apache Hadoop YARN (Yet Another Resource Negotiator)
Apache Hadoop YARN ist die Technologie für das Ressourcen-Management und Job Scheduling im Open Source Hadoop Distributed Processing Framework. Als eine der Kernkomponenten von Apache Hadoop ist YARN verantwortlich für die Zuweisung von Systemressourcen zu den verschiedenen Anwendungen, die in einem Hadoop-Cluster ausgeführt werden, und für die Planung von Aufgaben, die auf verschiedenen Cluster-Knoten ausgeführt werden.
YARN steht für Yet Another Resource Negotiator. Der vollständige Name war ein selbstironischer Spaß der Entwickler. YARN war 2012 eines der Hadoop-Teilprojekte innerhalb der Apache Software Foundation (ASF). Es ist eines der zentralen Features von Hadoop 2.0, das im selben Jahr zum Testen freigegeben wurde. Im Oktober 2013 wurde YARN allgemein verfügbar gemacht.
Das Hinzufügen von YARN zu Hadoop erweiterte dessen Anwendungsmöglichkeiten erheblich, denn bei der ursprünglichen Version wurde lediglich das Hadoop Distributed File System (HDFS) mit dem Batch-orientierten MapReduce Programmier-Framework und der Processing Engine, die auch als Ressourcen-Manager und Job Scheduler der großen Datenplattform fungierte, verbunden. Infolgedessen konnten Hadoop-1.0-Systeme nur MapReduce-Anwendungen ausführen - eine Einschränkung, die Hadoop YARN beseitigt hat.
Bevor YARN seinen offiziellen Namen erhielt, wurde es informell MapReduce 2 oder NextGen MapReduce genannt. Doch YARN führte einen neuen Ansatz ein, bei dem das Cluster-Ressourcen-Management und die Planung von MapReduce abgekoppelt sind. Das ermöglichte Hadoop erstmals verschiedene Verarbeitung- und Prozessarten auszuführen. Beispielsweise können Hadoop-Cluster jetzt parallel zu den MapReduce-Batchjobs auch interaktive Abfragen, Streaming Data und Echtzeit-Analysen mit Apache Spark oder anderen Processing Engines ausführen.
Hadoop YARN Features und Funktionen
In einer Cluster-Architektur sitzt Apache Hadoop YARN zwischen HDFS und den Prozessoren, die zur Ausführung von Anwendungen verwendet werden. Es kombiniert einen zentralen Ressourcen-Manager mit Containern, Anwendungskoordinatoren und Agenten auf Knotenebene, die die Verarbeitungsvorgänge in einzelnen Cluster-Knoten überwachen. YARN kann den Anwendungen bei Bedarf dynamisch Ressourcen zuweisen, was die Ressourcennutzung und Anwendungsleistung im Vergleich zum eher statischen Allokationsansatz bei MapReduce verbessert.
Darüber hinaus unterstützt YARN mehrere Einplanungsmethoden, die alle auf einem Queue-Format für die Übermittlung von Verarbeitungsjobs basieren. Der Standard-FIFO-Scheduler führt Anwendungen auf einer First-in-first-out-Basis aus. Dies ist jedoch möglicherweise nicht optimal für Cluster, die von mehreren Benutzern gemeinsam genutzt werden. Das Fair Scheduler Tool in Hadoop weist stattdessen jedem Job, der gleichzeitig läuft, seinen „fairen Anteil“ an Cluster-Ressourcen zu, basierend auf einer Gewichtungsmetrik, die der Scheduler berechnet.
Ein weiteres ansteckbares Tool, der so genannte Capacity Scheduler, ermöglicht den Betrieb von Hadoop-Clustern als mandantenfähige Systeme, die von verschiedenen Einheiten in einer Organisation oder von mehreren Unternehmen gemeinsam genutzt werden können, wobei jede von ihnen eine garantierte Verarbeitungskapazität auf der Grundlage individueller Service-Level-Agreements (SLAs) erhält. Es verwendet hierarchische Queues und Subqueues, um sicherzustellen, dass jedem Benutzer genügend Cluster-Ressourcen zugewiesen werden, bevor Jobs in anderen Queues auf ungenutzte Ressourcen zugreifen können.
Hadoop YARN enthält außerdem eine Reservierungsfunktion, mit der Nutzer im Voraus Cluster-Ressourcen für besonders wichtige Jobs reservieren können. Damit wird sichergestellt, dass diese reibungslos ablaufen. Um zu verhindern, dass ein Cluster mit derartigen Reservierungen überlastet wird, können IT-Manager die Ressourcen begrenzen, die von einzelnen Usern reserviert werden. Es lassen sich auch automatisch Regeln erstellen, nach denen Reservierungsanforderungen abgelehnt werden, sofern damit die vorgegebenen Grenzwerte überschritten werden.
YARN Federation ist ein weiteres Feature, das in Hadoop 3.0 hinzugefügt wurde, welches seit Dezember 2017 allgemein verfügbar ist. YARN Federation wurde entwickelt, um die Anzahl an bearbeitbaren Knoten zu erhöhen, die jetzt von 10.000 bis zu mehreren Zehntausenden reicht. Dieses wurde dadurch erreicht, indem in einem Routing Layer verschiedene Subcluster verbunden werden. Dabei ist jeder einzelne Subcluster mit einem eigenen Ressourcen-Manager ausgestattet. Das Gesamtsystem fungiert wie ein einziger großer Cluster, der alle Verarbeitungsjobs auf allen verfügbaren Knoten ausführen kann.
Hauptkomponenten von Hadoop YARN
In MapReduce überwachte der Masterprozess JobTracker die gesamte Ressourcenverwaltung sowie die Planung und die Überwachung aller Verarbeitungsaufträge. Der JobTracker generierte untergeordnete Prozesse namens TaskTrackers, die die einzelne Mapping- und Reduce-Aufgaben ausführen und über den jeweiligen Fortschritt berichten.
Doch der größte Teil der Ressourcenzuweisungs- und Koordinierungsarbeit wurde im JobTracker zentralisiert. Dies führte zu Leistungsengpässen und zu Skalierungsproblemen sobald die Cluster-Größen und die Anzahl der Anwendungen – und damit auch die Zahl der zugehörigen TaskTrackers – zunahmen.
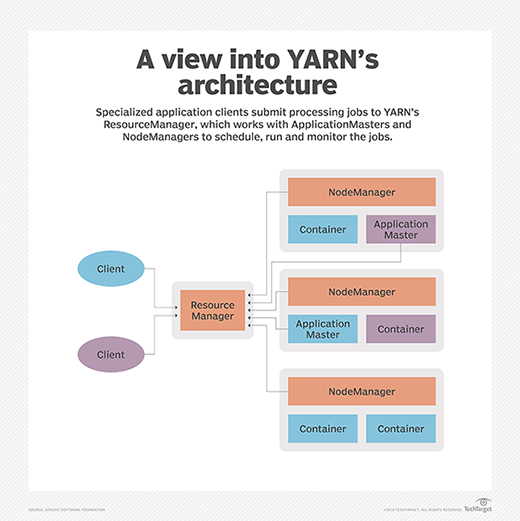
YARN dezentralisiert die Ausführung und Überwachung von Verarbeitungsaufträgen, indem die verschiedenen Zuständigkeiten aufgeteilt werden. Dabei handelt es sich um folgende Komponenten:
- Einen globalen ResourceManager, der Jobanmeldungen von Benutzern akzeptiert, diese Jobs terminiert und ihnen Ressourcen zuweist.
- Ein NodeManager-Slave, der an jedem Knoten installiert ist und als Monitoring- und Reporting-Agent des ResourceManager fungiert.
- Ein ApplicationMaster, der für jede Anwendung erstellt wird, um über Ressourcen zu verhandeln und mit dem NodeManager zu arbeiten, um Aufgaben auszuführen und zu überwachen.
- Ressourcen-Container, die von den NodeManagern gesteuert werden und den einzelnen Anwendungen, die vom System bereitgestellten Ressourcen zuweisen.
YARN-Container werden normalerweise in den Knoten eingerichtet und nur dann ausgeführt, wenn ihnen die entsprechenden Systemressourcen zugewiesen werden. Hadoop 3.0 unterstützt jedoch das Anlegen von sogenannten „opportunistischen Containern“. Diese warten bei den NodeManagers und starten sobald die nötigen Ressourcen verfügbar sind. Dieses Konzept zielt darauf ab, die Nutzung von Cluster-Ressourcen zu optimieren und letztendlich den gesamten Verarbeitungsdurchsatz in einem Hadoop-System zu erhöhen.
Auch wenn normalerweise YARN-Container direkt auf den Cluster-Knoten ausgeführt werden, so bietet Hadoop 3.1 die Möglichkeit, sie in Docker-Container einzufügen. Damit werden die Anwendungen sowohl untereinander als auch von der Ausführungsumgebung des NodeManagers isoliert. Darüber hinaus können mehrere Versionen einer Anwendung gleichzeitig in verschiedenen Docker-Containern ausgeführt werden.
Die Vorteile von YARN
Die Verwendung von Apache Hadoop YARN zur Trennung von HDFS und MapReduce macht die Hadoop-Umgebung besser geeignet für Echtzeit-Verarbeitungsanwendungen und andere Anwendungen, die nicht auf das Ende von Batch Jobs warten können. MapReduce ist nur noch eine von vielen Processing Engines, die Hadoop-Anwendungen ausführen können. Es gibt nicht einmal mehr eine Sperre für die Stapelverarbeitung in Hadoop: In vielen Fällen wird es durch Spark ersetzt, um eine schnellere Performance bei Batch-Anwendungen wie Extrahieren, Transformieren und Laden von Jobs zu erreichen.
Spark kann dank YARN auch Streaming Processing in Hadoop-Clustern ausführen, ebenso wie die Apache-Technologien Flink und Storm. YARN hat auch neue Anwendungen für Apache HBase, eine Begleitdatenbank zu HDFS, und für Apache Hive, Apache Drill, Apache Impala, Presto und andere SQL-on-Hadoop-Abfrage-Engines eröffnet. Neben einer größeren Auswahl an Anwendungen und Technologien bietet YARN Skalierbarkeit, Ressourcenauslastung, Hochverfügbarkeit und Leistungssteigerung gegenüber MapReduce.







