Was ist Dynamic Data Acceleration im Panasas PanFS?
Dynamic Data Acceleration ist eine Funktion im Filesystem PanFS von Panasas, das die Nutzung von SSD-Speicherressourcen optimieren und das Dateisystem leistungsfähiger machen soll.

Mit der Funktion Dynamic Data Acceleration in seinem Filesystem PanFS will das Unternehmen Panasas die hohen Anforderungen an Speicher im HPC-Umfeld (High-Performance Computing) bedienen und sowohl die Performance als auch die Latenzzeiten optimieren.
HPC-Systeme benötigen in der Regel Speichersysteme, die konsistent eine hohe Leistung erbringen und sich zudem automatisch den sich weiterentwickelnden HPC- und neuen KI-Workloads anpassen lassen.
Die sechs Herausforderungen an Storage im HPC-Segment
Der Hersteller betont, dass vor allem sechs sehr spezifische Speicheranforderungen beim HPC zu finden seien, die zwar in anderen Umgebungen auch anzutreffen sind, allerdings oft nicht so kritisch sind wie in diesem Hochleistungssegment.
Dazu gehört zum einen, dass All-Flash-Speichersysteme oft zu viel kosten, oftmals bis zu zehnmal mehr als hybride Storage-Lösungen. Da HPC-Systeme aber Unmengen an Daten erzeugen, können es sich Firmen nicht leisten, all diese auf Flash abzulegen, auch wenn die entsprechende Leistung benötigt wird. Hinzu kommt, dass HPC-Lösungen selbst sehr teuer sind, dass die IT-Budgets oft an anderer Stelle – beispielsweise dem Speicher – sparen wollen.
Tiered Storage ist eigentlich eine gute Idee: Daten, auf die viel zugegriffen werden, verschiebt das System per Policy auf schnellen Flash (Tier1), weniger genutzte Daten kommen auf schnelle Festplatten (Tier 2) und wenig abgerufene oder gar inaktive Daten auf langsame HDDs oder gar Tape (Tier 3).
Dieser Prozess kann aber beim High-Performance Computing zu komplex sein und dadurch zu inkonsistenter Leistung und reduzierter Produktivität führen. Verfügt man zudem nicht über ausreichenden Tier-1-Speicher, den die meisten HPC-Daten brauchen, so kann dies zur Verlangsamung der gesamten Verarbeitungs- und Speicherprozesse führen.
Ein weiteres Problem kann das manuelle Tuning sein, das häufig noch vonnöten ist. In einer Studie von Hyperion zu diesem Thema gaben 18 Prozent der befragten HPC-Verantwortlichen an, dass die Personalkosten und der Zeitaufwand von manuellem Tuning und Optimierungen eine Herausforderung ist, die sie gern eliminieren würden. Darüber hinaus fehlt es oft an ausreichenden Mitarbeitern mit den hierfür benötigten Kenntnissen.
Die Workloads in einer HPC-Umgebung unterliegen eigentlich ständigen Veränderungen. Mussten die Systeme gestern noch große Dateien verarbeiten, so können es morgen tausende an sehr kleinen Dateien sein. Hierfür muss das Filesystem entsprechend flexibel sein, sonst kommt es auch hier zu Engpässen.
Hinzugekommen sind zudem viele Workloads aus dem Bereich der künstlichen Intelligenz und dem maschinellen Lernen. Diese extrem Latenz-sensiblen Arbeitslasten können Speichersysteme schnell an ihre Grenzen bringen. Nicht zuletzt spielen auch die Betriebskosten stets eine Rolle. Diese hängen von der Komplexität, den Ausfallzeiten und dem Tuning des Storage-Systems ab.
Funktionsweise von Dynamic Data Acceleration
Dynamic Data Acceleration (DDA) wurde von Panasas in sein Dateisystem PanFS integriert und soll bei den oben erwähnten Problemen Abhilfe schaffen. Dafür optimiert diese Funktion die File-Performance auf SSDs und HDDs und nutzt das Potential der neu aufkommenden NVMe-Technologie.
DDA schiebt einen Software-Layer zwischen den Metadata Store und den eigentlichen Data Store und übernimmt eine Task-Priorisierung. Ein NVDIMM übernimmt das Logging beider Datensätze in den jeweiligen Store. Die Metadaten werden dabei in einer Datenbank auf einer NVMe-SSD mit extrem geringer Latenz abgelegt. Kleine Files werden auf SSDs mit geringer Latenz und hoher Bandbreite gesichert, große Dateien auf kostengünstige, hochkapazitive Festplatten mit hoher Bandbreite abgelegt.
DDA verwaltet quasi die Migration kleiner Dateien zwischen Festplatten und SSDs, um die Leistung bei zufälligem (Random) Zugriff und Workflows für kleine Dateien zu verbessern, indem diese von Streaming-Workflows isoliert werden. Wachsen Dateien aufgrund weiterer Transaktionen oder Änderungen an, können sie entsprechend auf HDDs verschoben werden.
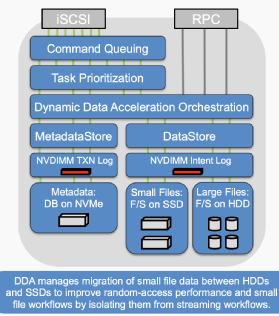
Der Hersteller gibt an, damit die Auslastung der SSDs zu maximieren und nahezu All-Flash-Performance zu einem günstigeren Preis anbieten zu können. Diese Architektur sei somit effizienter als die einiger Marktbegleiter die Daten nach ihrer „Temperatur“ priorisieren. Hierbei werden Files nach der Anzahl ihrer Zugriffe in „hot“, „warm“ und „cold“ eingeteilt und entsprechend auf dem jeweiligen Medium oder Tier gespeichert. Der Anbieter gibt ebenso an, in einem Vergleichstest zweimal so schnell wie seine Konkurrenten – BeeGFS, Lustre, GPFS – zu sein.
Es gibt derzeit verschiedene Ansätze, ein direktes Storage Tiering durch intelligente Datenplatzierung abzulösen, da der Tiering-Prozess zu viel Managementaufwand und Leistungseinschränkungen mit sich bringen kann. Nicht nur Panasas, auch andere Firmen versuchen hier Lösungsansätze in der Branche zu etablieren. So gehört unter anderem VAST Data als Marktneuling ebenso zu diesen Anbietern.
Anwendungsbeispiele
Als prominentes Anwendungsbeispiel gibt Panasas das Unternehmen Genomics England an, ein Unternehmen, das vom Ministerium für Gesundheit und Soziales gegründet wurde und das 100.000-Genom-Projekte bearbeitet, mit dem 100.000 Genome von NHS-Patienten mit einer seltenen Krankheit sowie von Krebspatienten sequenziert werden sollen.
Dort machte Panasas einen direkten Vergleichstest zu einem Wettbewerber. Die Konkurrenzfirma konnte 150 GB/s mit einem 1,3 Petabyte großen All-Flash-Layer erreichen. Zu höheren Latenzzeiten kam es, wenn Daten aus dem 40 Petabyte großen „kalten“ Festplatten-Tier benötigt wurden.
Darüber hinaus mussten Daten manuell von der HDD zurück auf das NVMe-Medium geschoben werden. Letztlich kostete das System 400 US-Dollar pro Terabyte. Im direkten Vergleich dazu erreichte Panasas eine Leistung von 410 GB/s mit ihrem 41 Petabyte großen hybriden System in der gleichen Umgebung. Alle Daten wiesen die gleiche Latenz auf und das Management der Daten erfolgt automatisch. Die Kosten beliefen sich mit dieser Lösung auf 200 US-Dollar pro Terabyte.
Ein Kunde des Unternehmens ist das Zentrum für Mikrobiom-Innovation der Universität Kalifornien in San Diego. Das Zentrum nutzt hochmoderne Technologien wie Genomik und Metagenomik und verarbeitet jedes Jahr hunderttausende Materialproben von Menschen, Tieren, Lebensmitteln und der bebauten Umwelt.
Dank dieser modernen Technologien und mit Hilfe von wissenschaftlicher Instrumente wie DNA-Sequenzer und Massenspektrometer können CMI-Forscher, Doktoranden und Postdoktoranden in verschiedenen Forschungslabors neue Instrumente und Methoden zur Verbesserung der menschlichen Gesundheit und zum Nutzen der Umwelt entwickeln. Insgesamt sind mehr als 150 Labore auf dem Campus aktiv.

Die genomische Sequenzierung und Analyse von Mikrobiomen erfordert riesige Datenmengen. Dazu erhält jeder der fast 300 Benutzer im CMI lokalen Speicherplatz über zwei Cluster. Allerdings reichen die vorhandenen Ressourcen heute nicht mehr für die Bewältigung umfangreicher E/A-Aufgaben wie die Verarbeitung von DNA-Sequenzen oder die Analyse anderer Multi-Terabyte-Datensätze aus. Versuche, die aktuellen Datenmengen mit herkömmlichen Speichertechnologien zu verarbeiten, führten zu Leistungseinbußen bei den Rechenabläufen und zu Beeinträchtigungen der Auswertungsgeschwindigkeit.
Für die Unterstützung datenintensiver Forschungsarbeiten mit der Notwendigkeit einer Analyse von wachsenden Datenmengen und das Ausführen einer ständig wachsenden Anzahl E/A-intensiver Aufgaben ohne Beeinträchtigung der Systemleistung nutzt das Forschungsinstitut die Panasas-Storage-Lösung ActiveStor. Die die CMI-Forscher speichern extrem große Datenmengen schnell und können diese ebenso rasch abrufen und analysieren. Das parallele PanFS-Dateisystem beschleunigt die Arbeit in allen Phasen des rechnergestützten Forschungsprozesses.
Frühere Speicherlösungen erwiesen sich für CMI-Wissenschaftler beim Abschluss ihrer Forschungen als Hindernis. Zu terminkritischen Zeiten erhielten manche Benutzer nicht einmal einen Login-Prompt für ihre Rechner. Dies verärgerte die Wissenschaftler, verlangsamte die Forschungsarbeit und führte zu vermehrten Beschwerden an die IT-Abteilung.






