Project Trino: a data-developer inside story

In 2012, while working at Facebook, Martin Traverso, David Phillips, Dain Sundstrom and Eric Hwang created open source project Presto to replace Apache Hive to attempt to address the problems of low-latency interactive analytics over Facebook’s massive Hadoop data warehouse.
The creators believed in the power of open communities and developers coming together to build successful software that can stand the test of time.
Therefore, they decided, from the very beginning, to build Presto with the goal of open sourcing it and did so in November 2013.
However, in 2018, it became clear that Facebook wanted to have tighter control over the project and its future. It was at this point that Presto creators Martin, David and Dain left Facebook to pursue building the Presto Open Source Community full-time.
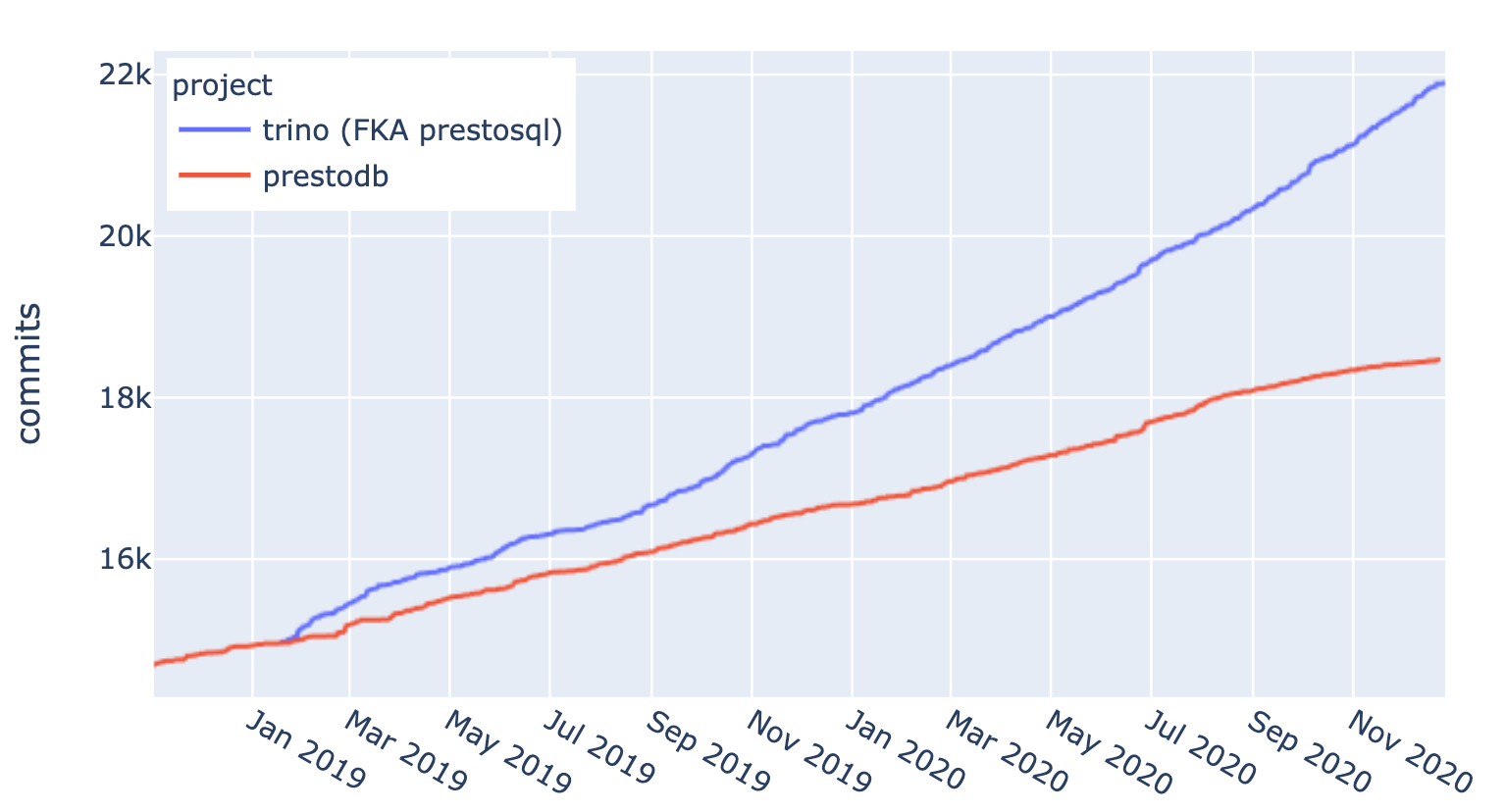
When Facebook donated its Presto project (PrestoDB) to the Linux Foundation, the name “PrestoSQL” was established to distinguish between them. All of the leading contributors outside of Facebook followed the Presto creators to this new repo and development continued at a fast pace.
{kind=link}
In December 2020, PrestoSQL was rebranded as Trino and Trino continues to serve a rapidly growing number of companies that require faster access to all of their data to drive business outcomes in an increasingly digital world.
Martin Traverso explains what happens next and writes from this point forward…
The Trino way

Traverso: Straddling the distributed data divide is no mean feat.
The insights gained from understanding that data and working with it can make or break the success of any initiative, or even a company. However, as data volumes captured from a myriad of sources are rapidly increasing and the variety of storage and management mechanisms are exploding, accessing all of this data distributed across various sources and silos presents a major challenge.
Trino addresses modern data challenges associated with exploding data volumes and sources by unlocking new opportunities with federated queries to disparate systems, parallel queries, horizontal cluster scaling etc. As an open source, distributed SQL query engine, Trino was designed to process, transform, analyse and orchestrate data against disparate data sources including data lakes.
It understands, supports and executes SQL, making it useful for online analytical processing (OLAP) workloads.
It is primarily a query engine that queries data where it lives and does not require migration of data to a single location. While the underlying data sources operate as the storage layer, Trino operates as the compute layer, scaling up and down (or horizontally) based on analytics demand to access this data.
SQL-on-Anything strength
Trino can query traditional relational database management systems (RDBMS) such as Microsoft SQL Server, PostgreSQL, MySQL, Oracle, Teradata and Amazon Redshift, as well as NoSQL systems such as Apache Cassandra, Apache Kafka, MongoDB, or Elasticsearch.
Essentially, Trino can query virtually any data as a SQL-on-Anything system.
Today, the Trino community thrives and grows, while Trino continues to be used at scale by many well-known organizations.
The project is maintained by a flourishing community of developers and contributors from many companies across the world. Companies including LinkedIn, Lyft, Netflix, GrubHub, Amazon, Bloomberg, Google, Comcast, FINRA, Condé Nast, Nordstrom and thousands of others use Trino to more quickly access and analyse data that drives better business decisions.

Image source: Trino