An inside look at Alibaba’s deep learning processor

From Huawei’s Kirin 970 system-on-chip (SoC) that packs in a neural processing unit to Google’s new Edge TPU that performs machine learning tasks on IoT devices, the use of dedicated chips to speed up artificial intelligence (AI) tasks has been in vogue in recent years.
But not all chips are built the same way. Google’s Edge TPU, for instance, is a purpose-built ASIC (application-specific integrated circuit) processor designed to perform AI inferencing, while GPUs (graphics processing units) – a type of ASIC chip – are more apt at training AI models where massive parallel processing is used to run matrix multiplications.
Then there are also FGPAs (field programmable gate arrays) which can be programmed for different use cases but are typically less powerful than ASIC chips.
The choice of chips depends on the types of AI workloads. For image recognition and analysis, which typically involve high workloads with strict requirements on service quality, Alibaba claims that GPUs are unable to balance low latency and high performance requirements at the same time.
In response, the Chinese cloud supplier has developed a FGPA-based ultra-low latency and high performance deep learning processor (DLP).
Alibaba said its DLP can support sparse convolution and low precision data computing at the same time, while a customised ISA (instruction set architecture) was defined to meet the requirements for flexibility and user experience.
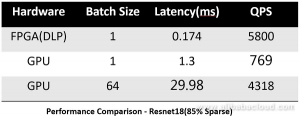
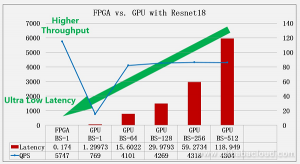
Latency test results with Resnet18 – a convolutional neural network architecture – showed that Alibaba’s DLP has a delay of only 0.174ms.
Here’s a look at how Alibaba thinking behind its DLP design:
Architecture
The DLP has four types of modules, classified based on their functions:
- Computing: Convolution, batch normalisation, activation and other calculations
- Data path: Data storage, movement and reshaping
- Parameter: Storage weight and other parameters, decoding
- Instruction: Instruction unit and global control
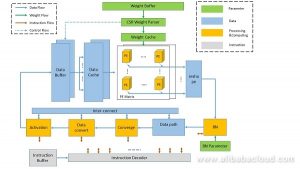
The Protocal Engine (PE) in the DLP can support:
- Int4 data type input.
- Int32 data type output.
- Int16 quantisation
This PE also offers over 90% efficiency. Furthermore, the DLP’s weight loading supports CSR Decoder and data pre-fetching.
Training
Re-training is needed to develop an accurate model. There are four main steps illustrated below to achieve both sparse weight and low precision data feature map.
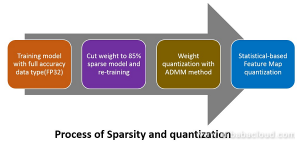
Alibaba used an effective method to train the Resnet18 model to sparse and low precision (1707.09870). The key component in its method is discretisation. It focused on compressing and accelerating deep models with network weights represented by very small numbers of bits, referred to as extremely low bit neural network. Then, it modeled this problem as a discretely constrained optimisation problem.
Borrowing the idea from Alternating Direction Method of Multipliers (ADMM), Alibaba decoupled the continuous parameters from the discrete constraints of the network, and cast the original hard problem into several sub-problems. Alibaba solved these sub-problems using extragradient and iterative quantisation algorithms, which led to considerably faster convergence compared to conventional optimisation methods.
Extensive experiments on image recognition and object detection showed that Alibaba’s algorithm is more effective than other approaches when working with extremely low bit neural network.
![]()
ISA/Compiler
Having low latency is not enough for most online services and usage scenarios since the algorithm model changes frequently. As FPGA development can take weeks or months, Alibaba designed an industry standard architecture (ISA) and compiler to reduce model upgrade time to just a few minutes.
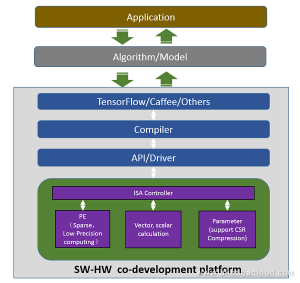
The software-hardware co-development platform comprises the following items:
- Compiler: model graph analysis and instruction generation
- API/driver: CPU-FPGA DMA picture reshape, weight compression
- ISA controller: instruction decoding, task scheduling, multi-thread pipeline management
Hardware card
The DLP was implemented on an Alibaba-designed FPGA card, which has PCIe and DDR4 memory. The DLP, combined with this FPGA card, can benefit applications such as online image searches.

Results
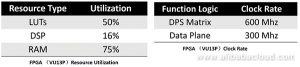
FPGA test results with Resnet18 showed that Alibaba’s design had achieved ultra-low level latency while maintaining very high performance with less than 70W chip power.