Infrastructure-as-Code series - DataStax: Making data services as easy as code

The Computer Weekly Developer Network (CWDN) continues its Infrastructure-as-Code (IaC) series of technical analysis discussions to uncover what this layer of the global IT fabric really means, how it integrates with the current push to orchestrate increasingly cloud-native systems more efficiently and what it means for software application development professionals now looking to take advantage of its core technology proposition.
This piece is written by Jeff Carpenter in his special role overseeing developer relations advocacy at DataStax.
DataStax is the company behind a ‘highly available’ cloud-native NoSQL data platform built on Apache Cassandra, which is a free and open source, distributed, wide column store, NoSQL database management system.
Carpenter writes as follows…
Infrastructure as Code developed as an approach to help developers take control of the complexity of managing ad-hoc deployments. Turning infrastructure management into code makes these deployments easier to inspect for potential issues and makes them repeatable over time.
IaC grew as developers began to appreciate the efficiencies that come with storing infrastructure configurations in the same source code repositories alongside the applications that rely on them.
IaC advantage in terms of data
Now it’s time to apply these same IaC principles to data. Most developers would love to spend less time worrying about deploying and managing databases and other data infrastructure. Rather than implementing these services themselves, it’s often much simpler to make use of existing services to deliver what they need.
This has led to a range of database-as-a-service (DBaaS) offerings entering the market over the past few years; serverless database products have expanded as well.
Data management by APIs
While it’s useful to be able to automate database deployment or use a managed database service, another alternative is emerging at a higher level of abstraction: the ability to deploy services that make data accessible through APIs. This matches the way developers are accustomed to interacting with other services. Over time, all the data that applications create will be managed via APIs. The data services providing these APIs will be deployable using IaC techniques; using them will be based on code that is easier to understand, faster to replicate, and simpler to deploy again.
So then, thinking about data within Infrastructure as Code.

Carpenter: (Most) developers would typically love to spend less time worrying about deploying & managing databases & other data infrastructures.
To implement this approach will require having your data reside on the same cloud infrastructure as the rest of your applications. Given the continuing trend toward cloud native architectures that consist of microservices and serverless functions, this means targeting environments like Kubernetes. Let’s look at the elements of these solutions.
Kubernetes ground zero
First, databases will need to run on Kubernetes. The best way to handle this is via a Kubernetes operator. Operators handle the creation of new database nodes, provisioning storage resources, monitoring database health, backups, replacing failed nodes, and, in advanced cases, can even automate scaling up and scaling down as the capacity needed by the application goes up and down.
All of this is managed in the background automatically, so that the service itself remains reliable and available. Kubernetes operators are available for most popular databases.
Next, building on the automation at the database layer, the database itself should be invisible to the developer. Instead, they should work solely through APIs. To make this work, developers can leverage the emerging data gateway approach that abstracts the database from the service.
The data gateway
Let’s examine the data gateway concept.
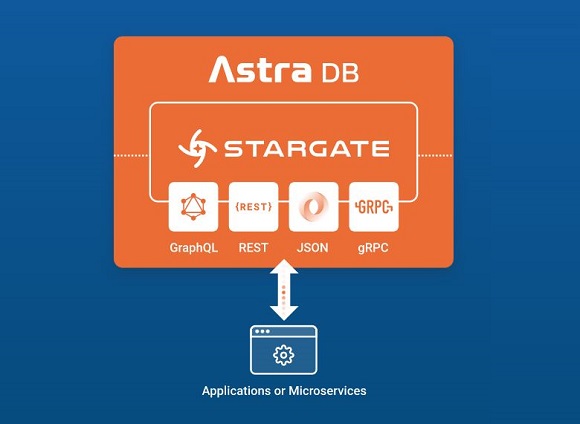
Over the years, many development teams have created internal abstraction layers for their databases to help shield application developers from the specifics of interacting with the underlying database, or to adapt an application written with a specific database query pattern to sit on top of a database with a different query language. These custom data gateways can now be replaced by more general-purpose gateways. One example of this is the Stargate project, which was launched to provide APIs such as REST, GraphQL, Document and gRPC over multiple databases, starting with Apache Cassandra.
Using a data gateway is the next step in automating data infrastructure using IaC. Developers can focus on writing to well-known APIs and hand over operational tasks such as schema management or potentially even data loading to the data gateway. Linking this developer-facing abstraction layer with automated database instances makes it easier to implement and run databases within an application. Finally, Infrastructure as Code is the glue that will enable developers to automate the entire process of building, managing and interacting with both data and data infrastructure over time.