IT modernisation series – Paperspace: We need a common (ML) dev tool stack

Unlike digital-first organisations, traditional businesses have a wealth of enterprise applications built up over decades, many of which continue to run core business processes.
In this series of articles we investigate how organisations are approaching the modernisation, replatforming and migration of legacy applications and related data services.
We look at the tools and technologies available encompassing aspects of change management and the use of APIs and containerisation (and more) to make legacy functionality and data available to cloud-native applications.
This post is written by Paperspace co-founder Daniel Kobran — Paperspace is a platform for developing Machine Learning applications — similar to Google AutoML or AWS Sagemaker.
Kobran writes as follows…
Deep learning workflows make for a challenging IT modernisation talk track, right? But why does a brand new toolset warrant a modernisation strategy?
It’s not that companies using them are trying to shrug off decades of machine learning rubbish — more typically, they’re trying for the first time to coalesce a few years of ad-hoc experimentation and innovation into something deterministic and scalable.
So how do we bring new workflows to bear on deep learning pipelines? Or, to put it another way, how can we expose these new workflows to the advantages of deep learning?
The question we need to ask ourselves is: how can we think about the ideal organisational philosophy that embraces machine learning innovation? What is the ‘stack’ that makes this possible?
Stack underflow
The short answer is that no single ‘stack’ exists yet for machine learning. Most machine learning teams are hacking together a laundry list of tools and frameworks. While many are successful, many more are reporting endless months and even years to get a single model to production.
As a result, the benefits of machine learning in production are proving elusive for many companies, no matter how innovative they typically are.
Further, we know that purse as strings tighten throughout the global economy, it will become ever more prudent to show real value quickly by productionalizing [Ed: yes, we left the z in] real models.
While there is no consensus stack available yet, there are answers in the form of cloud-native production environments and toolsets that make machine learning workflows more repeatable and machine learning teams more successful.
The cloud atmosphere
The most important enablers of ML value are determinism and collaboration.
Workflows that lack determinism are neither repeatable nor scalable — and so rare are the individuals that can orchestrate the many levels of an ML stack that collaborative tooling is necessary to allow, for example, a data scientist to obtain insight without the hand-holding of an infrastructure engineer at every level.
Cloud-based ML tooling makes this challenge easier. An effective toolset in this space need to provide help at every layer, we would offer the following selection pack as an ideal option: a cloud-hosted Jupyter notebook for experimentation, dependency management intelligence, framework-agnostic support, a CLI and a GUI to manipulate models, admin-level management… and a never-constrained choice of public and private cloud machines to perform training.
The result is a machine learning control panel that is available to any member of the team and makes it easy to incorporate frameworks and algorithms you already use under one roof for maximum efficiency and visibility.
No I without teams
For an individual contributor to be successful doing machine learning within a company there needs to be a common workspace and a common tooling philosophy. We’ve already seen that Gradient can solve the workspace problem — bring your own algorithms, data, frameworks, dependencies and even compute — but it also solves the philosophical problem of how to grow and scale without losing velocity.
Gradient provides continuous integration for machine learning workflows. GradientCI allows you to push code via GitHub. It allows you to orchestrate complex pipelines from the UI or from the command line. And it allows each member of a team to ship experiments with his or her code and train them on the fly with machines that are provisioned instantly and effortlessly.
With a tool like Gradient, existing team members have 100% confidence that their models are improving over time and costs are fully controlled and new team members can be productive and successful shipping experiments on Day 1.
Final (deep) thoughts
Machine learning represents a sea-change for creating new business value from existing data — but only for the teams that can get their individual contributors to work together in deterministic environments.
There are so many exciting technologies out there that can augment your machine learning efforts — go ahead and take advantage of them! But always remember to choose a toolset that will help your team collaborate and improve over time. It’s the best way to ensure success.
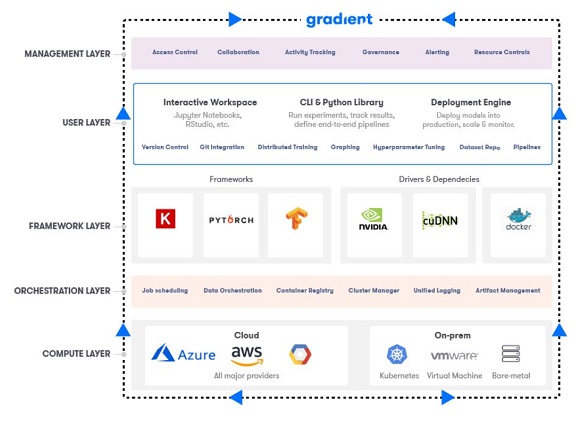
Image credit: Paperspace – spelling out the ‘layers’ of ML.